Как Java HashMap обрабатывает различные объекты с одним и тем же хеш-кодом?
В соответствии с моим пониманием я думаю:
- Вполне допустимо, чтобы два объекта имели одинаковый хеш-код.
- Если два объекта равны (используя метод equals()), они имеют одинаковый хэш-код.
- Если два объекта не равны, они не могут иметь одинаковый хэш-код
Я прав?
Теперь, если я прав, у меня есть следующий вопрос: HashMap внутренне использует хеш-код объекта. Итак, если два объекта могут иметь одинаковый хэш-код, то как HashMap отслеживать, какой ключ он использует?
Может кто-нибудь объяснить, как HashMap внутренне использует хеш-код объекта?
17 ответов
Хэш-карта работает следующим образом (это немного упрощено, но иллюстрирует основной механизм):
У него есть несколько "сегментов", которые он использует для хранения пар ключ-значение. Каждый блок имеет уникальный номер - это то, что идентифицирует блок. Когда вы помещаете пару ключ-значение в карту, хеш-карта будет смотреть на хеш-код ключа и сохранять пару в том блоке, идентификатором которого является хеш-код ключа. Например: хэш-код ключа - 235 -> пара сохраняется в номере корзины 235. (Обратите внимание, что в одной корзине может храниться более одной пары ключ-значение).
Когда вы просматриваете значение в hashmap, давая ему ключ, оно сначала смотрит на хеш-код ключа, который вы дали. Затем хэш-карта будет смотреть в соответствующее ведро, а затем сравнивать ключ, который вы дали, с ключами всех пар в ведре, сравнивая их с equals(),
Теперь вы можете увидеть, как это очень эффективно для поиска пар ключ-значение на карте: по хэш-коду ключа хэш-карта сразу знает, в каком сегменте искать, так что ему нужно только проверить, что находится в этом сегменте.
Рассматривая вышеупомянутый механизм, вы также можете увидеть, какие требования необходимы для hashCode() а также equals() методы ключей:
Если два ключа совпадают (
equals()возвращаетсяtrueкогда вы их сравниваете), ихhashCode()Метод должен вернуть тот же номер. Если ключи нарушают это, то равные ключи могут храниться в разных сегментах, и хэш-карта не сможет найти пары ключ-значение (потому что она будет выглядеть в одном и том же сегменте).Если два ключа разные, то не имеет значения, одинаковы ли их хэш-коды или нет. Они будут храниться в одном и том же сегменте, если их хэш-коды совпадают, и в этом случае хэш-карта будет использовать
equals()рассказать им отдельно.
Ваше третье утверждение неверно.
Совершенно законно, что два неравных объекта имеют одинаковый хеш-код. Используется HashMap как "фильтр первого прохода", так что карта может быстро найти возможные записи с указанным ключом. Затем ключи с одинаковым хеш-кодом проверяются на равенство с указанным ключом.
Вы не хотели бы требовать, чтобы два неравных объекта не могли иметь одинаковый хеш-код, иначе это ограничило бы вас32 32 возможными объектами. (Это также означает, что разные типы не могут даже использовать поля объекта для генерации хеш-кодов, так как другие классы могут генерировать тот же хеш.)

HashMap это массив Entry объекты.
Рассматривать HashMap как просто массив объектов.
Посмотрите, что это Object является:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
…
}
каждый Entry Объект представляет пару ключ-значение. Поле next относится к другому Entry объект, если в ведре более одного Entry,
Иногда может случиться, что хеш-коды для двух разных объектов совпадают. В этом случае два объекта будут сохранены в одном сегменте и будут представлены в виде связанного списка. Точка входа - это недавно добавленный объект. Этот объект относится к другому объекту с next поле и тд. Последняя запись относится к null,
Когда вы создаете HashMap с конструктором по умолчанию
HashMap hashMap = new HashMap();
Массив создается с размером 16 и балансировкой нагрузки 0,75 по умолчанию.
Добавление новой пары ключ-значение
- Рассчитать хеш-код для ключа
- Рассчитать позицию
hash % (arrayLength-1)где должен быть размещен элемент (номер корзины) - Если вы попытаетесь добавить значение с ключом, который уже был сохранен в
HashMap, тогда значение перезаписывается. - В противном случае элемент добавляется в корзину.
Если в корзине уже есть хотя бы один элемент, добавляется новый и помещается в первую позицию корзины. это next поле относится к старому элементу.
делеция
- Рассчитать хеш-код для данного ключа
- Рассчитать номер ковша
hash % (arrayLength-1) - Получить ссылку на первый объект Entry в сегменте и с помощью метода equals выполнить итерацию по всем элементам в данном сегменте. В конце концов мы найдем правильный
Entry, Если нужный элемент не найден, вернутьnull
Вы можете найти отличную информацию на http://javarevisited.blogspot.com/2011/02/how-hashmap-works-in-java.html
Подвести итоги:
HashMap работает по принципу хеширования
put(ключ, значение): HashMap сохраняет объект ключа и значения как Map.Entry. Hashmap применяет хеш-код (ключ), чтобы получить корзину. если есть столкновение, HashMap использует LinkedList для хранения объекта.
get (key): HashMap использует хеш-код Key Object для определения местоположения сегмента, а затем вызывает метод keys.equals(), чтобы определить правильный узел в LinkedList и вернуть объект связанного значения для этого ключа в Java HashMap.
Вот примерное описание HashMapМеханизм, для Java 8 версия, (она может немного отличаться от Java 6).
Структуры данных
- Хеш-таблица
Значение хеша вычисляется черезhash()на ключ, и он решает, какой сегмент хеш-таблицы использовать для данного ключа. - Связанный список (отдельно)
Когда количество элементов в корзине мало, используется односвязный список. - Красно-Черное дерево
Когда количество элементов в корзине велико, используется красно-черное дерево.
Классы (внутренние)
Map.Entry
Представлять один объект на карте, ключ / значение объекта.HashMap.Node
Версия связанного списка узла.Это может представлять:
- Хэш-ведро.
Потому что у него есть свойство хеша. - Узел в односвязном списке (таким образом, также глава связного списка).
- Хэш-ведро.
HashMap.TreeNode
Древовидная версия узла.
Поля (внутренние)
Node[] table
Таблица ведра, (глава связанных списков).
Если корзина не содержит элементов, то она пуста, поэтому занимает только место ссылки.Set<Map.Entry> entrySetНабор сущностей.int size
Количество объектов.float loadFactor
Укажите, насколько полна хеш-таблица, до изменения размера.int threshold
Следующий размер для изменения размера.
Формула:threshold = capacity * loadFactor
Методы (внутренние)
int hash(key)
Рассчитать хеш по ключу.Как сопоставить хэш с ведром?
Используйте следующую логику:static int hashToBucket(int tableSize, int hash) { return (tableSize - 1) & hash; }
О емкости
В хеш-таблице, емкость означает количество сегментов, которое можно получить из table.length,
Также можно рассчитать через threshold а также loadFactorТаким образом, нет необходимости определять поле класса.
Может получить эффективную мощность через: capacity()
операции
- Найти сущность по ключу.
Сначала найдите корзину по значению хеша, затем зацикливайте связанный список или ищите отсортированное дерево. - Добавить сущность с ключом.
Сначала найдите корзину в соответствии с хэш-значением ключа.
Затем попробуйте найти значение:- Если найдено, замените значение.
- В противном случае добавьте новый узел в начале связанного списка или вставьте в отсортированное дерево.
- Изменение размера
когдаthresholdдостигнут, удвоит емкость хеш-таблицы (table.length), затем выполните повторное хеширование всех элементов, чтобы восстановить таблицу.
Это может быть дорогой операцией.
Спектакль
- получить и положить
Время сложностьO(1), так как:- Доступ к Bucket осуществляется через индекс массива, таким образом,
O(1), - Связанный список в каждом сегменте имеет небольшую длину, поэтому его можно рассматривать как
O(1), - Размер дерева также ограничен, поскольку при увеличении количества элементов будет расширяться емкость и повторное хеширование, поэтому его можно рассматривать как
O(1)неO(log N),
- Доступ к Bucket осуществляется через индекс массива, таким образом,
Хэш-код определяет, какой сегмент для хэш-карты нужно проверить. Если в корзине более одного объекта, то выполняется линейный поиск, чтобы определить, какой элемент в корзине равен желаемому предмету (используя equals()) метод.
Другими словами, если у вас есть идеальный хеш-код, тогда доступ к хеш-карте является постоянным, вам никогда не придется выполнять итерации по сегменту (технически вам также потребуется иметь MAX_INT-сегменты, реализация Java может совместно использовать несколько хеш-кодов в одном сегменте для сократить требования к пространству). Если у вас худший хеш-код (всегда возвращает одно и то же число), тогда ваш доступ к хэш-карте становится линейным, поскольку вам нужно искать все элементы на карте (все они в одном ведре), чтобы получить то, что вы хотите.
Большую часть времени хорошо написанный хэш-код не идеален, но достаточно уникален, чтобы предоставить вам более или менее постоянный доступ.
Вы ошибаетесь в третьем пункте. Две записи могут иметь одинаковый хеш-код, но не быть равными. Посмотрите на реализацию HashMap.get из OpenJdk. Вы можете видеть, что он проверяет, что хэши равны, а ключи равны. Если бы пункт три был верным, то было бы ненужно проверять, чтобы ключи были равны. Хеш-код сравнивается перед ключом, потому что первый - более эффективное сравнение.
Если вам интересно узнать немного больше об этом, взгляните на статью в Википедии, посвященную разрешению коллизий в Open Addressing, которая, как я считаю, является механизмом, который использует реализация OpenJdk. Этот механизм несколько отличается от подхода "корзины", который упоминается в других ответах.
import java.util.HashMap;
public class Students {
String name;
int age;
Students(String name, int age ){
this.name = name;
this.age=age;
}
@Override
public int hashCode() {
System.out.println("__hash__");
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
System.out.println("__eq__");
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Students other = (Students) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public static void main(String[] args) {
Students S1 = new Students("taj",22);
Students S2 = new Students("taj",21);
System.out.println(S1.hashCode());
System.out.println(S2.hashCode());
HashMap<Students,String > HM = new HashMap<Students,String > ();
HM.put(S1, "tajinder");
HM.put(S2, "tajinder");
System.out.println(HM.size());
}
}
Output:
__ hash __
116232
__ hash __
116201
__ hash __
__ hash __
2
Итак, здесь мы видим, что если оба объекта S1 и S2 имеют разное содержимое, то мы почти уверены, что наш переопределенный метод Hashcode сгенерирует разные Hashcode(116232,11601) для обоих объектов. СЕЙЧАС, поскольку существуют разные хэш-коды, поэтому даже не стоит вызывать метод EQUALS. Потому что другой Hashcode ГАРАНТИРУЕТ РАЗНОЕ содержимое в объекте.
public static void main(String[] args) {
Students S1 = new Students("taj",21);
Students S2 = new Students("taj",21);
System.out.println(S1.hashCode());
System.out.println(S2.hashCode());
HashMap<Students,String > HM = new HashMap<Students,String > ();
HM.put(S1, "tajinder");
HM.put(S2, "tajinder");
System.out.println(HM.size());
}
}
Now lets change out main method a little bit. Output after this change is
__ hash __
116201
__ hash __
116201
__ hash __
__ hash __
__ eq __
1
We can clearly see that equal method is called. Here is print statement __eq__, since we have same hashcode, then content of objects MAY or MAY not be similar. So program internally calls Equal method to verify this.
Conclusion
If hashcode is different , equal method will not get called.
if hashcode is same, equal method will get called.
Thanks , hope it helps.
Это самый запутанный вопрос для многих из нас в интервью. Но это не так сложно.
Мы знаем
HashMap хранит пару ключ-значение в Map.Entry (мы все знаем)
HashMap работает над алгоритмом хеширования и использует методы hashCode() и equals() в методах put () и get (). (даже мы это знаем)
When we call put method by passing key-value pair, HashMap uses Key **hashCode()** with hashing to **find out the index** to store the key-value pair. (this is important)The Entry is **stored in the LinkedList**, so if there are already existing entry, it uses **equals() method to check if the passed key already exists** (even this is important)если да, он перезаписывает значение, иначе он создает новую запись и сохраняет эту запись значения ключа.
Когда мы вызываем метод get, передавая Key, он снова использует hashCode(), чтобы найти индекс в массиве, а затем использует метод equals(), чтобы найти правильный Entry и вернуть его значение. (теперь это очевидно)
ЭТО ИЗОБРАЖЕНИЕ ПОМОЖЕТ ВАМ ПОНИМАТЬ:
Редактировать сентябрь 2017 года: здесь мы видим, как значение хеш-функции, если используется вместе с равными после того, как мы найдем сегмент.
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
}
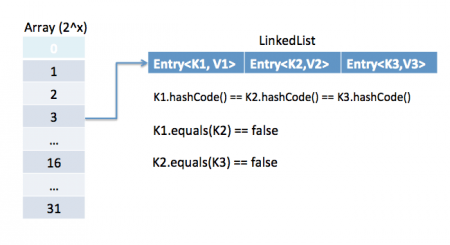
два объекта равны, подразумевается, что они имеют одинаковый хэш-код, но не наоборот
Обновление Java 8 в HashMap-
Вы делаете эту операцию в своем коде -
myHashmap.put("old","key-value-pair");
myHashMap.put("very-old","old-key-value-pair");
Итак, предположим, что ваш хэш-код возвращается для обоих ключей "old" а также "very-old" такой же. Тогда что будет.
myHashMap является HashMap, и предположим, что изначально вы не указали его емкость. Таким образом, емкость по умолчанию для java равна 16. Итак, теперь, когда вы инициализировали hashmap с помощью нового ключевого слова, он создал 16 сегментов. теперь, когда вы выполнили первое заявление-
myHashmap.put("old","key-value-pair");
тогда хеш-код для "old" вычисляется, и потому что хеш-код может быть очень большим целым числом, поэтому, java внутренне сделал это - (хеш-код здесь хеш-код, а >>> это сдвиг вправо)
hash XOR hash >>> 16
таким образом, чтобы дать большую картину, он вернет некоторый индекс, который будет между 0 и 15. Теперь ваша пара ключ-значение "old" а также "key-value-pair" будет преобразован в ключ объекта Entry и переменную экземпляра значения. и тогда этот объект записи будет сохранен в корзине, или вы можете сказать, что при определенном индексе этот объект записи будет сохранен.
FYI- Entry - это класс в интерфейсе Map - Map.Entry, с этими сигнатурами / определениями
class Entry{
final Key k;
value v;
final int hash;
Entry next;
}
теперь, когда вы выполняете следующую инструкцию -
myHashmap.put("very-old","old-key-value-pair");
а также "very-old" дает тот же хэш-код, что и "old"Таким образом, эта новая пара ключ-значение снова отправляется в тот же индекс или в тот же сегмент. Но так как это ведро не пустое, то next переменная объекта Entry используется для хранения этой новой пары ключ-значение.
и он будет сохранен как связанный список для каждого объекта, имеющего тот же хеш-код, но TRIEFY_THRESHOLD задается со значением 6. поэтому после достижения этого связанный список преобразуется в сбалансированное дерево (красно-черное дерево) с первым элементом в качестве корень.
Каждый объект Entry представляет пару ключ-значение. Поле next относится к другому объекту Entry, если в ячейке более 1 записи.
Иногда может случиться, что хэш-коды для 2 разных объектов одинаковы. В этом случае 2 объекта будут сохранены в одном сегменте и будут представлены как LinkedList. Точкой входа является недавно добавленный объект. Этот объект ссылается на другой объект со следующим полем и так один. Последняя запись относится к нулю. Когда вы создаете HashMap с конструктором по умолчанию
Массив создается с размером 16 и балансировкой нагрузки 0,75 по умолчанию.

Хеш-карта работает по принципу хеширования
Метод get(Key k) HashMap вызывает метод hashCode для объекта ключа и применяет возвращенное hashValue к своей собственной статической хэш-функции, чтобы найти местоположение сегмента (вспомогательный массив), где ключи и значения хранятся в форме вложенного класса с именем Entry (Map. Вступление) . Итак, вы пришли к выводу, что из предыдущей строки и ключ, и значение хранятся в корзине как форма объекта Entry. Поэтому думать, что в корзине хранится только значение, не правильно и не произведет хорошего впечатления на интервьюера.
- Всякий раз, когда мы вызываем метод get(Key k) для объекта HashMap. Сначала он проверяет, является ли ключ нулевым или нет. Обратите внимание, что в HashMap может быть только один нулевой ключ.
Если ключ имеет значение null, то ключи с нулевым значением всегда отображаются в хэш 0, то есть индекс 0.
Если ключ не равен нулю, он вызовет hashfunction для объекта ключа, см. Строку 4 в вышеупомянутом методе, т.е. key.hashCode(), поэтому после того, как key.hashCode () вернет hashValue, строка 4 выглядит следующим образом:
int hash = hash(hashValue)
и теперь он применяет возвращенное hashValue в свою собственную функцию хеширования.
Мы можем задаться вопросом, почему мы снова вычисляем hashvalue, используя hash (hashValue) . Ответ защищает от хеш-функций низкого качества.
Теперь окончательное хеш-значение используется для определения местоположения сегмента, в котором хранится объект Entry. Объект ввода хранится в корзине следующим образом (хэш, ключ, значение, индекс ведра)
Принимая во внимание приведенные здесь объяснения структуры хэш-карты, возможно, кто-то сможет объяснить следующий абзац о Baeldung:-
В Java есть несколько реализаций интерфейса Map, каждая со своими особенностями.
Однако ни одна из существующих реализаций Java Core Map не позволяет Map обрабатывать несколько значений для одного ключа.
Как мы видим, если мы попытаемся вставить два значения для одного и того же ключа, второе значение будет сохранено, а первое будет удалено.
Он также будет возвращен (каждой правильной реализацией метода put (K key, V value)):
Map<String, String> map = new HashMap<>();
assertThat(map.put("key1", "value1")).isEqualTo(null);
assertThat(map.put("key1", "value2")).isEqualTo("value1");
assertThat(map.get("key1")).isEqualTo("value2");
Я не буду вдаваться в подробности того, как работает HashMap, но приведу пример, чтобы мы могли помнить, как работает HashMap, связывая его с реальностью.
У нас есть Key, Value,HashCode и bucket.
В течение некоторого времени мы будем связывать каждого из них со следующим:
- Ведро -> Общество
- HashCode -> адрес общества (всегда уникальный)
- Значение -> Дом в обществе
- Ключ -> Домашний адрес.
Используя Map.get(ключ):
Стиви хочет попасть в дом своего друга (Джосс), который живет на вилле в VIP-обществе, пусть это будет Общество любителей Java. Адрес Джосса - это его SSN(он у всех разный). Поддерживается индекс, в котором мы узнаем название Общества на основе SSN. Этот индекс можно считать алгоритмом для определения HashCode.
- Название Общества SSN
- 92313(Josse's) - JavaLovers
- 13214 - AngularJSLovers
- 98080 - JavaLovers
- 53808 - Любители биологии
- Этот SSN(ключ) сначала дает нам HashCode(из таблицы индексов), который является не чем иным, как названием Общества.
- Теперь несколько домов могут находиться в одном обществе, поэтому хэш-код может быть обычным явлением.
- Предположим, что Общество является общим для двух домов, как мы собираемся определить, в какой дом мы пойдем, да, используя ключ (SSN), который является не чем иным, как адресом дома
Использование Map.put (ключ, значение)
Это находит подходящее общество для этого значения, находя HashCode, а затем значение сохраняется.
Я надеюсь, что это помогает, и это открыто для изменений.
В обобщенном виде Как работает hashMap в Java?
HashMap работает по принципу хэширования, у нас есть метод put() и get() для хранения и извлечения объекта из HashMap. Когда мы передаем и ключ, и значение для метода put() для хранения в HashMap, он использует метод hashcode() ключевого объекта для вычисления хеш-кода, и они, применяя хеширование к этому хэш-коду, идентифицируют местоположение сегмента для хранения объекта значения. При извлечении используется метод равенства объектов ключа, чтобы найти правильную пару значений ключа и объект возвращаемого значения, связанный с этим ключом. HashMap использует связанный список в случае коллизии, и объект будет сохранен в следующем узле связанного списка. Также HashMap хранит кортеж ключ + значение в каждом узле связанного списка.
Как говорится, картинка стоит 1000 слов. Я говорю: какой-то код лучше, чем 1000 слов. Вот исходный код HashMap. Получить метод:
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Таким образом, становится ясно, что хеш используется для поиска "сегмента", и первый элемент всегда проверяется в этом блоке. Если нет то equals ключа используется для поиска фактического элемента в связанном списке.
Давайте посмотрим put() метод:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Это немного сложнее, но становится ясно, что новый элемент помещается во вкладку в позиции, рассчитанной на основе хеша:
i = (n - 1) & hash Вот i это индекс, в который будет помещен новый элемент (или это "корзина"). n это размер tab массив (массив "ведер").
Во-первых, его пытаются поставить в качестве первого элемента в этом "ведре". Если элемент уже существует, добавьте новый узел в список.
Ответ будет длинным, выпей и читай...
Хеширование - это сохранение пары ключ-значение в памяти, которая может быть прочитана и записана быстрее. Он хранит ключи в массиве и значения в LinkedList.
Скажем, я хочу сохранить 4 пары ключ-значение -
{
“girl” => “ahhan” ,
“misused” => “Manmohan Singh” ,
“horsemints” => “guess what”,
“no” => “way”
}
Поэтому для хранения ключей нам нужен массив из 4 элементов. Теперь, как мне сопоставить один из этих 4 ключей с 4 индексами массива (0,1,2,3)?
Поэтому java находит хэш-код отдельных ключей и сопоставляет их с определенным индексом массива. Hashcode Formulas - это
1) reverse the string.
2) keep on multiplying ascii of each character with increasing power of 31 . then add the components .
3) So hashCode() of girl would be –(ascii values of l,r,i,g are 108, 114, 105 and 103) .
e.g. girl = 108 * 31^0 + 114 * 31^1 + 105 * 31^2 + 103 * 31^3 = 3173020
Хэш и девушка!! Я знаю, что вы думаете. Ваше увлечение этим диким дуэтом может заставить вас упустить важную вещь.
Почему ява умножает это на 31?
Это потому, что 31 - нечетное простое число в форме 2^5 - 1. И нечетное простое число уменьшает вероятность хеш-коллизии
Теперь, как этот хэш-код отображается на индекс массива?
ответ, Hash Code % (Array length -1), Так “girl” сопоставлен с (3173020 % 3) = 1 в нашем случае. который является вторым элементом массива.
и значение "ахан" сохраняется в LinkedList, связанном с индексом массива 1.
HashCollision - если вы попытаетесь найти hasHCode из ключей “misused” а также “horsemints” используя формулы, описанные выше, вы увидите, что оба дают нам то же самое 1069518484, Воуаа!! урок выучен -
2 равных объекта должны иметь одинаковый hashCode, но нет гарантии, что hashCode совпадает, тогда объекты равны. Таким образом, он должен хранить оба значения, соответствующие "неправильно использованным" и "лошадиным мятам", в интервал 1 (1069518484 % 3) .
Теперь хэш-карта выглядит так:
Array Index 0 –
Array Index 1 - LinkedIst (“ahhan” , “Manmohan Singh” , “guess what”)
Array Index 2 – LinkedList (“way”)
Array Index 3 –
Теперь, если какое-то тело пытается найти значение для ключа “horsemints”, Java быстро найдет его хеш-код, отредактирует его и начнет искать его значение в соответствующем LinkedList index 1, Таким образом, нам не нужно искать все 4 индекса массива, что ускоряет доступ к данным.
Но, подождите, одну секунду есть 3 значения в этом LinkList, соответствующем индексу массива 1, как он узнает, какое из них было значением для ключевых "скачек"?
На самом деле я солгал, когда сказал, что HashMap просто хранит значения в LinkedList.
Он хранит обе пары ключ-значение в качестве записи карты. Так что на самом деле карта выглядит так.
Array Index 0 –
Array Index 1 - LinkedIst (<”girl” => “ahhan”> , <” misused” => “Manmohan Singh”> , <”horsemints” => “guess what”>)
Array Index 2 – LinkedList (<”no” => “way”>)
Array Index 3 –
Теперь вы можете видеть, проходя через связанный список, соответствующий ArrayIndex 1, он фактически сравнивает ключ каждой записи с этим LinkedList с "скачками", и когда он находит его, он просто возвращает его значение.
Надеюсь, вам было весело читать это:)