Обнаруживать и исключать выбросы в кадре данных Pandas
У меня есть пандас dataframe с несколькими столбцами.
Теперь я знаю, что определенные строки являются выбросами на основе определенного значения столбца.
Например, столбцы - "Vol" имеет все значения около 12.xx и одно значение 4000
Теперь я хотел бы исключить те строки, которые имеют Vol Column, как это.
По сути, мне нужно установить фильтр таким образом, чтобы мы выбирали все строки, в которых значения определенного столбца находятся в пределах, скажем, 3 стандартных отклонений от среднего значения.
Какой элегантный способ добиться этого.
19 ответов
Если у вас есть несколько столбцов в вашем фрейме данных и вы хотите удалить все строки, которые имеют выбросы хотя бы в одном столбце, следующее выражение сделает это за один кадр.
df = pd.DataFrame(np.random.randn(100, 3))
from scipy import stats
df[(np.abs(stats.zscore(df)) < 3).all(axis=1)]
Для каждого столбца данных можно получить квантиль с помощью:
q = df["col"].quantile(0.99)
а затем отфильтруйте с помощью:
df[df["col"] < q]
Использование boolean индексация, как вы бы сделали в numpy.array
df = pd.DataFrame({'Data':np.random.normal(size=200)})
# example dataset of normally distributed data.
df[np.abs(df.Data-df.Data.mean()) <= (3*df.Data.std())]
# keep only the ones that are within +3 to -3 standard deviations in the column 'Data'.
df[~(np.abs(df.Data-df.Data.mean()) > (3*df.Data.std()))]
# or if you prefer the other way around
Для серии это похоже:
S = pd.Series(np.random.normal(size=200))
S[~((S-S.mean()).abs() > 3*S.std())]
Прежде чем ответить на вопрос, мы должны задать еще один, который очень важен в зависимости от характера ваших данных:
Что такое выброс?
Представьте себе серию ценностей
[3, 2, 3, 4, 999] (где, казалось бы, не вписывается) и проанализируйте различные способы обнаружения выбросов
Z-оценка
Проблема здесь в том, что рассматриваемая стоимость искажает наши измерения.
mean а также
std сильно, что приводит к незаметному z-баллу примерно
[-0.5, -0.5, -0.5, -0.5, 2.0], сохраняя каждое значение в пределах двух стандартных отклонений от среднего. Следовательно, один очень большой выброс может исказить всю вашу оценку выбросов. Я бы не одобрил такой подход.
Квантильный фильтр
Способ дается более надежный подход этот ответ , исключая нижнюю и верхнюю 1% данных. Однако это устраняет фиксированную долю независимо от вопроса, действительно ли эти данные являются выбросами. Вы можете потерять много достоверных данных и, с другой стороны, по-прежнему сохранить некоторые выбросы, если у вас более 1% или 2% данных как выбросы.
IQR-расстояние от медианы
Еще более надежная версия квантильного принципа: исключить все данные, превышающие
fумноженное на межквартильный размах от медианы данных. Это то что
sklearn«S RobustScaler делает, например. IQR и медиана устойчивы к выбросам, поэтому вы перехитрите проблемы подхода z-показателя.
В нормальном распределении примерно
iqr=1.35*s, так что вы бы переводили
z=3 фильтра по z-оценке, чтобы
f=2.22iqr-фильтра. Это приведет к падению
999 в приведенном выше примере.
Основное предположение состоит в том, что по крайней мере «средняя половина» ваших данных действительна и хорошо напоминает распределение, в то время как вы также ошибаетесь, если хвосты имеют отношение к рассматриваемой проблеме.
Расширенные статистические методы
Конечно, существуют причудливые математические методы, такие как критерий Пирса , тест Грабба или Q-тест Диксона, и это лишь некоторые из них, которые также подходят для данных с ненормальным распределением. Ни один из них не реализуется легко и, следовательно, не рассматривается в дальнейшем.
Код
Замена всех выбросов для всех числовых столбцов на
np.nanна примере фрейма данных. Этот метод устойчив ко всем типам dtypes, которые предоставляет pandas, и может быть легко применен к фреймам данных со смешанными типами:
import pandas as pd
import numpy as np
# sample data of all dtypes in pandas (column 'a' has an outlier) # dtype:
df = pd.DataFrame({'a': list(np.random.rand(8)) + [123456, np.nan], # float64
'b': [0,1,2,3,np.nan,5,6,np.nan,8,9], # int64
'c': [np.nan] + list("qwertzuio"), # object
'd': [pd.to_datetime(_) for _ in range(10)], # datetime64[ns]
'e': [pd.Timedelta(_) for _ in range(10)], # timedelta[ns]
'f': [True] * 5 + [False] * 5, # bool
'g': pd.Series(list("abcbabbcaa"), dtype="category")}) # category
cols = df.select_dtypes('number').columns # limits to a (float), b (int) and e (timedelta)
df_sub = df.loc[:, cols]
# OPTION 1: z-score filter: z-score < 3
lim = np.abs((df_sub - df_sub.mean()) / df_sub.std(ddof=0)) < 3
# OPTION 2: quantile filter: discard 1% upper / lower values
lim = np.logical_or(df_sub < df_sub.quantile(0.99, numeric_only=False),
df_sub > df_sub.quantile(0.01, numeric_only=False))
# OPTION 3: iqr filter: within 2.22 IQR (equiv. to z-score < 3)
iqr = df_sub.quantile(0.75, numeric_only=False) - df_sub.quantile(0.25, numeric_only=False)
lim = np.abs((df_sub - df_sub.median()) / iqr) < 2.22
# replace outliers with nan
df.loc[:, cols] = df_sub.where(lim, np.nan)
Если вы хотите удалить все строки, содержащие значение nan, используйте это (удаляет также строки с NaN в нечисловых столбцах):
df.dropna(inplace=True)
Использование функций pandas 1.3:
Этот ответ аналогичен ответу @tanemaki, но использует lambda выражение вместо scipy stats,
df = pd.DataFrame(np.random.randn(100, 3), columns=list('ABC'))
df[df.apply(lambda x: np.abs(x - x.mean()) / x.std() < 3).all(axis=1)]
Для фильтрации DataFrame, где только один столбец (например, "B") находится в пределах трех стандартных отклонений:
df[((df.B - df.B.mean()) / df.B.std()).abs() < 3]
#------------------------------------------------------------------------------
# accept a dataframe, remove outliers, return cleaned data in a new dataframe
# see http://www.itl.nist.gov/div898/handbook/prc/section1/prc16.htm
#------------------------------------------------------------------------------
def remove_outlier(df_in, col_name):
q1 = df_in[col_name].quantile(0.25)
q3 = df_in[col_name].quantile(0.75)
iqr = q3-q1 #Interquartile range
fence_low = q1-1.5*iqr
fence_high = q3+1.5*iqr
df_out = df_in.loc[(df_in[col_name] > fence_low) & (df_in[col_name] < fence_high)]
return df_out
Поскольку я не видел ответа, касающегося числовых и нечисловых атрибутов, вот ответ на дополнение.
Возможно, вы захотите сбросить выбросы только для числовых атрибутов (категориальные переменные вряд ли могут быть выбросами).
Определение функции
Я расширил предложение @ tanemaki для обработки данных, когда присутствуют также нечисловые атрибуты:
from scipy import stats
def drop_numerical_outliers(df, z_thresh=3):
# Constrains will contain `True` or `False` depending on if it is a value below the threshold.
constrains = df.select_dtypes(include=[np.number]) \
.apply(lambda x: np.abs(stats.zscore(x)) < z_thresh, reduce=False) \
.all(axis=1)
# Drop (inplace) values set to be rejected
df.drop(df.index[~constrains], inplace=True)
использование
drop_numerical_outliers(df)
пример
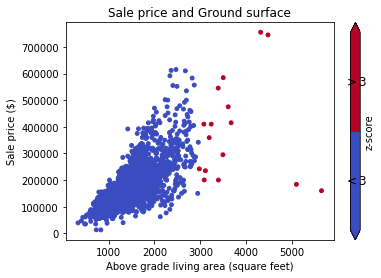
Представьте набор данных df с некоторыми значениями о домах: переулок, контур земли, цена продажи, например: документация данных
Во-первых, вы хотите визуализировать данные на диаграмме рассеяния (с z-счетом Thresh=3):
# Plot data before dropping those greater than z-score 3.
# The scatterAreaVsPrice function's definition has been removed for readability's sake.
scatterAreaVsPrice(df)
# Drop the outliers on every attributes
drop_numerical_outliers(train_df)
# Plot the result. All outliers were dropped. Note that the red points are not
# the same outliers from the first plot, but the new computed outliers based on the new data-frame.
scatterAreaVsPrice(train_df)
Для каждой серии в кадре данных вы можете использовать between а также quantile удалить выбросы.
x = pd.Series(np.random.normal(size=200)) # with outliers
x = x[x.between(x.quantile(.25), x.quantile(.75))] # without outliers
scipy.stats имеет методы trim1() а также trimboth() вырезать выбросы в одну строку в соответствии с ранжированием и введенным процентом удаленных значений.
Если вам нравится цепочка методов, вы можете получить логическое условие для всех числовых столбцов, например:
df.sub(df.mean()).div(df.std()).abs().lt(3)
Каждое значение каждого столбца будет преобразовано в True/False основанный на том, меньше ли его трех стандартных отклонений от среднего или нет.
Другой вариант - преобразовать ваши данные, чтобы уменьшить влияние выбросов. Вы можете сделать это, украсив ваши данные.
import pandas as pd
from scipy.stats import mstats
%matplotlib inline
test_data = pd.Series(range(30))
test_data.plot()

# Truncate values to the 5th and 95th percentiles
transformed_test_data = pd.Series(mstats.winsorize(test_data, limits=[0.05, 0.05]))
transformed_test_data.plot()

Вы можете использовать логическую маску:
import pandas as pd
def remove_outliers(df, q=0.05):
upper = df.quantile(1-q)
lower = df.quantile(q)
mask = (df < upper) & (df > lower)
return mask
t = pd.DataFrame({'train': [1,1,2,3,4,5,6,7,8,9,9],
'y': [1,0,0,1,1,0,0,1,1,1,0]})
mask = remove_outliers(t['train'], 0.1)
print(t[mask])
выход:
train y
2 2 0
3 3 1
4 4 1
5 5 0
6 6 0
7 7 1
8 8 1
Поскольку я нахожусь на очень ранней стадии моего пути в науке о данных, я лечу выбросы с помощью приведенного ниже кода.
#Outlier Treatment
def outlier_detect(df):
for i in df.describe().columns:
Q1=df.describe().at['25%',i]
Q3=df.describe().at['75%',i]
IQR=Q3 - Q1
LTV=Q1 - 1.5 * IQR
UTV=Q3 + 1.5 * IQR
x=np.array(df[i])
p=[]
for j in x:
if j < LTV or j>UTV:
p.append(df[i].median())
else:
p.append(j)
df[i]=p
return df
Получите 98-й и 2-й процентили как пределы наших выбросов
upper_limit = np.percentile(X_train.logerror.values, 98)
lower_limit = np.percentile(X_train.logerror.values, 2) # Filter the outliers from the dataframe
data[‘target’].loc[X_train[‘target’]>upper_limit] = upper_limit data[‘target’].loc[X_train[‘target’]<lower_limit] = lower_limit
Ниже приведен полный пример с данными и двумя группами:
Импорт:
from StringIO import StringIO
import pandas as pd
#pandas config
pd.set_option('display.max_rows', 20)
Пример данных с двумя группами: G1: группа 1. G2: группа 2:
TESTDATA = StringIO("""G1;G2;Value
1;A;1.6
1;A;5.1
1;A;7.1
1;A;8.1
1;B;21.1
1;B;22.1
1;B;24.1
1;B;30.6
2;A;40.6
2;A;51.1
2;A;52.1
2;A;60.6
2;B;80.1
2;B;70.6
2;B;90.6
2;B;85.1
""")
Прочитать текстовые данные в pandas dataframe:
df = pd.read_csv(TESTDATA, sep=";")
Определите выбросы, используя стандартные отклонения
stds = 1.0
outliers = df[['G1', 'G2', 'Value']].groupby(['G1','G2']).transform(
lambda group: (group - group.mean()).abs().div(group.std())) > stds
Определите значения отфильтрованных данных и выбросы:
dfv = df[outliers.Value == False]
dfo = df[outliers.Value == True]
Распечатать результат:
print '\n'*5, 'All values with decimal 1 are non-outliers. In the other hand, all values with 6 in the decimal are.'
print '\nDef DATA:\n%s\n\nFiltred Values with %s stds:\n%s\n\nOutliers:\n%s' %(df, stds, dfv, dfo)
Я предпочитаю обрезать, а не уронить. следующее будет закреплено на 2-м и 98-м пестиле.
df_list = list(df)
minPercentile = 0.02
maxPercentile = 0.98
for _ in range(numCols):
df[df_list[_]] = df[df_list[_]].clip((df[df_list[_]].quantile(minPercentile)),(df[df_list[_]].quantile(maxPercentile)))
Моя функция отбрасывать выбросы
def drop_outliers(df, field_name):
distance = 1.5 * (np.percentile(df[field_name], 75) - np.percentile(df[field_name], 25))
df.drop(df[df[field_name] > distance + np.percentile(df[field_name], 75)].index, inplace=True)
df.drop(df[df[field_name] < np.percentile(df[field_name], 25) - distance].index, inplace=True)
Если в вашем фрейме данных есть выбросы, есть много способов справиться с этими выбросами:
Большинство из них упоминаются в моих статьях: Прочтите это.
Найдите код здесь: Ноутбук
Удаление и удаление выбросов, которые я считаю статистически неправильными. Это отличает данные от исходных данных. Также делает данные неравномерной формы и, следовательно, лучший способ состоит в том, чтобы уменьшить или избежать влияния выбросов путем лог-преобразования данных. Это сработало для меня:
np.log(data.iloc[:, :])