Искра: java.io.FileNotFoundException: файл не существует в copyMerge
Я пытаюсь объединить все файлы искровых деталей в каталог и создать один файл в Scala.
Вот мой код:
import org.apache.spark.sql.functions.input_file_name
import org.apache.spark.sql.functions.regexp_extract
def merge(srcPath: String, dstPath: String): Unit = {
val hadoopConfig = new Configuration()
val hdfs = FileSystem.get(hadoopConfig)
FileUtil.copyMerge(hdfs, new Path(srcPath), hdfs, new Path(dstPath), true, hadoopConfig, null)
// the "true" setting deletes the source files once they are merged into the new output
}
И затем, на последнем шаге, я пишу вывод данных, как показано ниже.
dfMainOutputFinalWithoutNull.repartition(10).write.partitionBy("DataPartition","StatementTypeCode")
.format("csv")
.option("nullValue", "")
.option("header", "true")
.option("codec", "gzip")
.mode("overwrite")
.save(outputfile)
merge(mergeFindGlob, mergedFileName )
dfMainOutputFinalWithoutNull.unpersist()
Когда я запускаю это, я получаю ниже исключения
java.io.FileNotFoundException: File does not exist: hdfs:/user/zeppelin/FinancialLineItem/temp_FinancialLineItem
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1309)
Вот как я получаю свой вывод
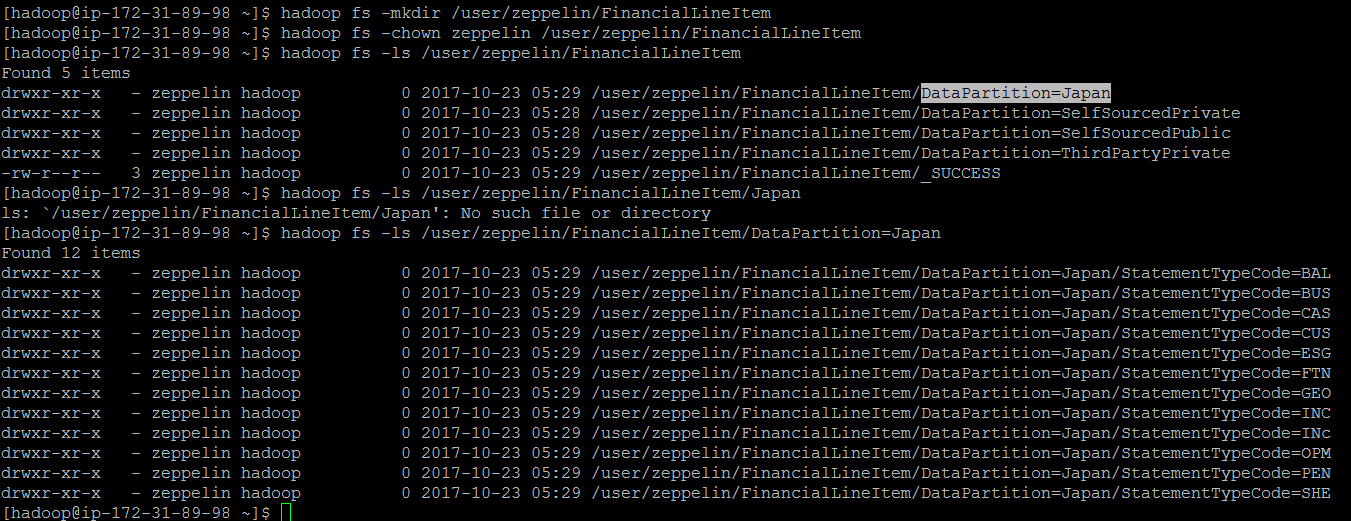
Вместо папки я хочу объединить все файлы внутри папки и создать один файл.
1 ответ
В Hadoop 2 есть API-интерфейс copyMerge: https://hadoop.apache.org/docs/r2.7.1/api/src-html/org/apache/hadoop/fs/FileUtil.html
К сожалению, это будет устаревшим и удалено в Hadoop 3.0.
Вот повторная реализация copyMerge (хотя в PySpark), которую мне пришлось написать, так как мы не смогли найти лучшего решения: https://github.com/Tagar/stuff/blob/master/copyMerge.py
Надеюсь, это поможет кому-то еще.