Office.context.document.getFileAsync выдает ошибки
Я получаю очень странную проблему, из-за которой при попытке извлечь текстовый документ в виде сжатого файла для обработки в моем приложении MS Word Task Pane MVC в третий раз, он взорвется.
Вот код:
Office.context.document.getFileAsync(Office.FileType.Compressed, function (result) {
if (result.status == "succeeded") {
var file = result.value;
file.getSliceAsync(0, function (resultSlice) {
//DO SOMETHING
});
} else {
//TODO: Service fault handling?
}
});
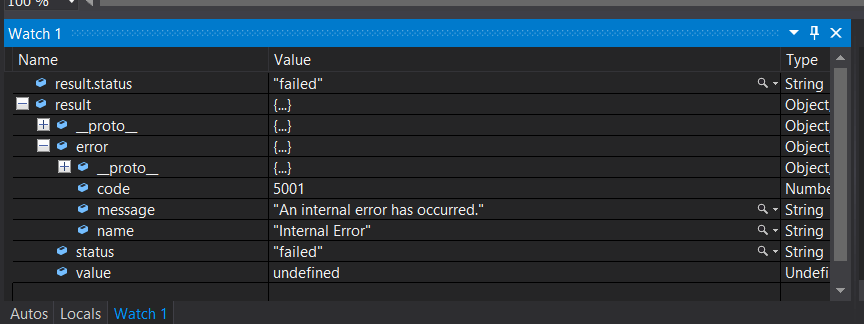
Появляется код ошибки 5001. Я не уверен, как это исправить.
Пожалуйста, дайте мне знать, если у вас есть какие-либо мысли по этому поводу.
Дополнительные детали:
4 ответа
Из MSDN:
В памяти должно быть не более двух документов; в противном случае
getFileAsyncоперация не удастся. ИспользоватьFile.closeAsyncспособ закрыть файл, когда вы закончите работу с ним.
Убедитесь, что вы звоните File.closeAsync прежде чем вы снова прочитаете файл - это может объяснить проблему, с которой вы столкнулись.
Больше на: https://msdn.microsoft.com/en-us/library/office/jj715284.aspx
У меня есть пример того, как правильно использовать этот API. На самом деле текущий пример в MSDN не очень правильный. Этот код проверен в Word.
// Usually we encode the data in base64 format before sending it to server.
function encodeBase64(docData) {
var s = "";
for (var i = 0; i < docData.length; i++)
s += String.fromCharCode(docData[i]);
return window.btoa(s);
}
// Call getFileAsync() to start the retrieving file process.
function getFileAsyncInternal() {
Office.context.document.getFileAsync("compressed", { sliceSize: 10240 }, function (asyncResult) {
if (asyncResult.status == Office.AsyncResultStatus.Failed) {
document.getElementById("log").textContent = JSON.stringify(asyncResult);
}
else {
getAllSlices(asyncResult.value);
}
});
}
// Get all the slices of file from the host after "getFileAsync" is done.
function getAllSlices(file) {
var sliceCount = file.sliceCount;
var sliceIndex = 0;
var docdata = [];
var getSlice = function () {
file.getSliceAsync(sliceIndex, function (asyncResult) {
if (asyncResult.status == "succeeded") {
docdata = docdata.concat(asyncResult.value.data);
sliceIndex++;
if (sliceIndex == sliceCount) {
file.closeAsync();
onGetAllSlicesSucceeded(docdata);
}
else {
getSlice();
}
}
else {
file.closeAsync();
document.getElementById("log").textContent = JSON.stringify(asyncResult);
}
});
};
getSlice();
}
// Upload the docx file to server after obtaining all the bits from host.
function onGetAllSlicesSucceeded(docxData) {
$.ajax({
type: "POST",
url: "Handler.ashx",
data: encodeBase64(docxData),
contentType: "application/json; charset=utf-8",
}).done(function (data) {
document.getElementById("documentXmlContent").textContent = data;
}).fail(function (jqXHR, textStatus) {
});
}
Вы можете найти больше информации здесь: https://github.com/pkkj/AppForOfficeSample/tree/master/GetFileAsync
Надеюсь, это может помочь.
В дополнение к ответу Кейджинга Пэна (который я нашел очень полезным, спасибо!), Я подумал, что поделюсь вариацией на encodeBase64, которую вы не хотите делать, если вы загружаете через REST в SharePoint. В этом случае вы хотите преобразовать байтовый массив в массив Uint8Array. Только тогда я смогу поместить его в библиотеку SharePoint без повреждения файла.
var uArray = new Uint8Array(docdata);
Надеюсь, что это кому-то поможет, не смог найти эту информацию где-либо еще в Интернете...
Смотрите эту ссылку http://msdn.microsoft.com/en-us/library/office/jj715284(v=office.1501401).aspx
он содержит этот пример метода:
var i = 0;
var slices = 0;
function getDocumentAsPDF() {
Office.context.document.getFileAsync("pdf",{sliceSize: 2097152}, function (result) {
if (result.status == "succeeded") {
// If the getFileAsync call succeeded, then
// result.value will return a valid File Object.
myFile = result.value;
slices = myFile.sliceCount;
document.getElementById("result").innerText = " File size:" + myFile.size + " #Slices: " + slices;
// Iterate over the file slices.
for ( i = 0; i < slices; i++) {
var slice = myFile.getSliceAsync(i, function (result) {
if (result.status == "succeeded") {
doSomethingWithChunk(result.value.data);
if (slices == i) // Means it's done traversing...
{
SendFileComplete();
}
}
else
document.getElementById("result").innerText = result.error.message;
});
}
myFile.closeAsync();
}
else
document.getElementById("result2").innerText = result.error.message;
});
}
измените "pdf" на "сжатый" и вызов метода doSomethingWithChunk() должен быть создан и, вероятно, должен сделать что-то вроде этого:
function base64Encode(str) {
return btoa(encodeURIComponent(str).replace(/%([0-9A-F]{2})/g, function (match, p1) {
return String.fromCharCode('0x' + p1);
}));
}
Я использую эту технику для успешного сохранения в хранилище BLOB-объектов Azure.
Очевидно, вы должны также переименовать метод.