HTML::TreeBuilder каким-то образом объединяет все элементы таблицы, вложенные в тег BODY?
Я пытался проанализировать содержимое какой-либо веб-страницы, используя HTML::TreeBuilder, а затем выполнить ручную XPath-подобную прогулку.
Но я получил кое-что действительно странное.
Это X-Path, созданный с веб-страницы Chrome Developer Tools:
/html/body/table/tbody/tr/td[1]/table[3]/tbody/tr[1]/td[2]/
table[1]/tbody/tr[1]/td[2]/**table[9]**
Эта последняя внутренняя таблица № 9 - это то, что мне нужно, в частности, ячейка с текстом "кликни для просмотра".
Вот скриншот инструментов разработчика - обратите внимание, что под тегом BODY находится только одна таблица:
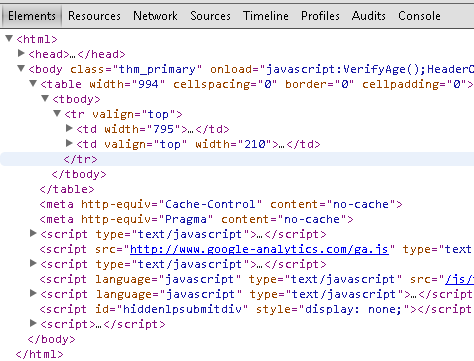
И если вы углубитесь в этот XPath, вы увидите элемент, который я ищу (обратите внимание, что это действительно вложенная таблица в таблице внутри таблицы - я включил элемент TD, который ищу):
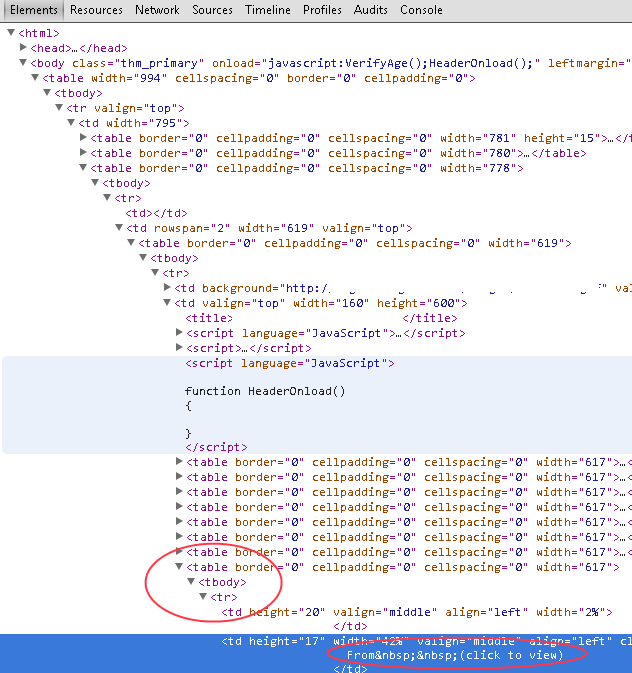
ОДНАКО, это то, что HTML::TreeBuilder производит вместо этого (в основном, <body> тег, содержащий 22 тега под ним, большинство из которых <table> теги:
DB<16> x $tree->tag
0 'body'
DB<17> x map {$_->tag} $tree->content_list
0 'table'
1 'table'
2 'table'
3 'table'
4 'table'
5 'table'
6 'table'
7 'table'
8 'table'
9 'table'
10 'table'
11 'table'
12 'table'
13 'table'
14 'table'
15 'table'
16 'table'
17 'table'
18 'table'
19 'script'
20 'table'
21 'table'
И, как вы можете видеть, восьмая таблица под тегом BODY TAG содержит элемент, который я хочу
DB<37> foreach my $c (0 .. $tree->content_list-1) {
if (($tree->content_list)[$c]->as_HTML =~ /click to view/)
{print $c+1}}
9
1 ответ
Скорее всего, обрабатываемая вами страница содержит недопустимый HTML. В этой ситуации открыт сезон, когда этот контент должен быть представлен, и разное программное обеспечение будет делать разные выборы.
Боюсь, что вы ничего не можете с этим поделать, кроме обработки HTML без помощи парсера, или, возможно, поиска ошибки и ее исправления до того, как вы ее исправите. HTML::TreeBuilder, Ни один из них не очень приятная перспектива.