Как сопоставить "что-нибудь до этой последовательности символов" в регулярном выражении?
Возьмите это регулярное выражение: /^[^abc]/, Это будет соответствовать любому отдельному символу в начале строки, кроме a, b или c.
Если вы добавите * после этого - /^[^abc]*/ - регулярное выражение будет продолжать добавлять каждый последующий символ к результату, пока не встретит aили bили c,
Например, с исходной строкой "qwerty qwerty whatever abc hello", выражение будет соответствовать до "qwerty qwerty wh",
Но что, если бы я хотел, чтобы совпадающая строка была "qwerty qwerty whatever "
... Другими словами, как я могу сопоставить все до (но не включая) точную последовательность "abc"?
16 ответов
Вы не указали, какой тип регулярного выражения вы используете, но это будет работать в любом из самых популярных из них, которые можно считать завершенными.
/.+?(?=abc)/
Как это устроено
.+? часть является жадной версией .+ (одно или несколько из чего-либо). Когда мы используем .+ двигатель будет в основном соответствовать всем. Затем, если в регулярном выражении есть что-то еще, он пошагово вернется к следующей части. Это жадное поведение, означающее максимально удовлетворить.
Когда используешь .+? вместо того, чтобы сопоставлять все сразу и возвращаться к другим условиям (если они есть), механизм будет сопоставлять следующие символы шаг за шагом, пока не будет сопоставлена следующая часть регулярного выражения (снова, если есть). Это не жадный, означающий совпадение наименьшего возможного для удовлетворения.
/.+X/ ~ "abcXabcXabcX" /.+/ ~ "abcXabcXabcX"
^^^^^^^^^^^^ ^^^^^^^^^^^^
/.+?X/ ~ "abcXabcXabcX" /.+?/ ~ "abcXabcXabcX"
^^^^ ^
После этого мы имеем (?={contents}), утверждение нулевой ширины, осмотреться. Эта сгруппированная конструкция соответствует своему содержимому, но не считается как сопоставленные символы (нулевая ширина). Возвращается только в случае совпадения или нет (утверждение).
Таким образом, другими словами, регулярное выражение /.+?(?=abc)/ средства:
Подбирайте как можно меньше символов, пока не найдете "abc", не считая "abc".
Если вы хотите захватить все до "abc":
/^(.*?)abc/
Объяснение:
( ) захватить выражение в скобках для доступа с помощью $1, $2, так далее.
^ совпадение начала строки
.* сопоставить что угодно, ? без жадности (соответствует минимальному количеству символов) - [1]
[1] Причина, по которой это необходимо, заключается в том, что в противном случае в следующей строке:
whatever whatever something abc something abc
по умолчанию регулярные выражения являются жадными, что означает, что они будут совпадать в максимально возможной степени. Следовательно /^.*abc/ будет соответствовать "все, что угодно, что-то ABC-то". Добавление не жадного квантификатора ? заставляет регулярное выражение совпадать только "что угодно, что угодно".
Как отметили @Jared Ng и @Issun, ключ для решения такого рода регулярных выражений, как "сопоставление всего до определенного слова или подстроки" или "сопоставление всего после определенного слова или подстроки", называется "косвенным" утверждением нулевой длины, Читайте больше о них, здесь.
В вашем конкретном случае это можно решить путем позитивного взгляда в будущее. Одна картинка стоит тысячи слов. Смотрите подробное объяснение на скриншоте.

Решение
/[\s\S]*?(?=abc)/
Это будет соответствовать
все до (но не включая) точной последовательности
"abc"
как спросил OP, даже если исходная строка содержит символы новой строки и даже если последовательность начинается с . Однако не забудьте включить многострочный флаг
m, если исходная строка может содержать символы новой строки.
Как это работает
означает любой пробельный символ (например, пробел, табуляция, новая строка)
\Sозначает любой непробельный символ; т.е. напротив
\s
Все вместе
[\s\S]означает любой персонаж . Это почти то же самое, за исключением того, что
. не соответствует новой строке.
*означает 0+ вхождений предыдущего токена. Я использовал это вместо
+ в случае, если исходная строка начинается с.
(?=называется позитивным взглядом вперед . Он требует совпадения со строкой в круглых скобках, но останавливается непосредственно перед ней, поэтому означает «до, но не включая, но должен присутствовать в исходной строке».
? между
[\s\S]* а также
(?=abc)означает ленивый (он же не жадный ). т.е. остановимся на первом. Без этого он захватил бы каждый символ до последнего появления if
abc произошло не раз.
То, что вам нужно, это посмотреть на утверждение как .+? (?=abc),
См.: Взгляд вперед и взгляд назад.
Быть в курсе, что [abc] не то же самое, что abc, Внутри скобок это не строка - каждый символ - только одна из возможностей. За скобками он становится строкой.
Соответствие от начала до «Перед ABC» или «Конец строки», если нет ABC
(1) Соответствует всей строке, если строка нигде не содержит ABC
(2) Не соответствует пустой строке
(Не проверяется для строк с разрывами строк)
^.+?(?=ABC|$)
Для регулярных выражений в Java, и я верю также в большинство движков регулярных выражений, если вы хотите включить последнюю часть, это будет работать:
.+?(abc)
Например, в этой строке:
I have this very nice senabctence
выбрать все символы до "abc", а также включить abc
используя наше регулярное выражение, результат будет: I have this very nice senabc
Проверьте это: https://regex101.com/r/mX51ru/1
На питоне:
.+?(?=abc) работает для однострочного случая.
[^]+?(?=abc)не работает, поскольку python не распознает [^] как допустимое регулярное выражение. Чтобы добиться многострочного сопоставления, вам нужно использовать опцию re.DOTALL, например:
re.findall('.+?(?=abc)', data, re.DOTALL)
Я остановился на этом вопросе stackru после поиска помощи, чтобы решить мою проблему, но не нашел ее решения:(
Поэтому мне пришлось импровизировать... через некоторое время мне удалось найти необходимое мне регулярное выражение:
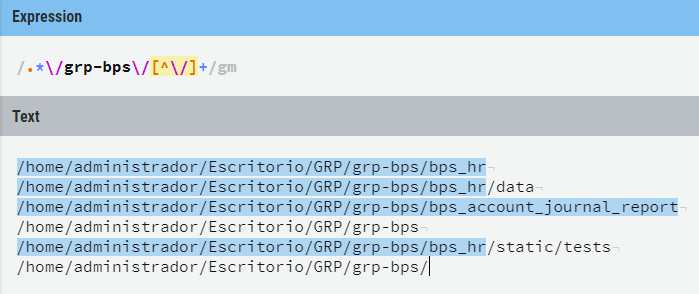
Как видите, мне нужно было до одной папки впереди папки "grp-bps", не включая последнюю черту. И требовалось иметь хотя бы одну папку после папки "grp-bps".
Я хотел бы расширить ответ от @sidyll для версии регулярного выражения без учета регистра .
Если вы хотите сопоставить abc / Abc / ABC ... без учета регистра, что мне нужно было сделать, используйте следующее регулярное выражение.
.+?(?=(?i)abc)
Объяснение:
(?i) - This will make the following abc match case insensitively.
Все остальные объяснения регулярного выражения остаются такими же, как указал @sidyll.
Это будет иметь смысл о регулярных выражениях.
- Точное слово можно получить из следующей команды регулярного выражения:
("(.*?)")/г
Здесь мы можем получить точное слово глобально, которое принадлежит внутри двойных кавычек. Например, если наш поисковый текст
Это пример слова "двойные кавычки"
тогда мы получим "двойные кавычки" из этого предложения.
В вашем вопросе не указано, является ли последующая последовательность символов необязательной или нет, но все остальные ответы предполагают, что последовательность всегда задана. Итак, вот один, если последовательность не является обязательной.
Например, при сопоставлении кода с строковым комментарием, напримерfoo # ...илиfoo // ..., сам строковый комментарий может быть необязательным, но все же может потребоваться соответствие предыдущему коду.
В этом случае я бы использовал^(?:(?!abc).)*(или для строковых комментариев:^(?:(?!#).)*или^(?:(?!\/\/).)*).
Объяснение:
^отмечает начало строки.(?:)является незахватывающей группой, потому что обычная группа дополнительно захватывала бы последнюю совпадающую букву в группе, которая нам не нужна.
Внутри группы мы используем отрицательный просмотр вперед(?!)и., поэтому все совпадает, кроме определенной последовательности. Это повторяется от 0 до неограниченного количества раз с*. Использовать+вместо этого, если вы хотите сопоставить только непустые строки.
.*(\s)*?(?=abc)
Для тех, кто хочет также включать разрывы строк.
Он будет соответствовать всему и всему (включая разрывы строк (независимо от того, сколько или даже если нет разрыва строки)), пока abc находится.
$ отмечает конец строки, поэтому что-то вроде этого должно работать: [[^abc]*]$ где вы ищете что-нибудь, не заканчивающееся в любой итерации abc, но это должно быть в конце
Также, если вы используете язык сценариев с регулярным выражением (например, php или js), у них есть функция поиска, которая останавливается при первом обнаружении шаблона (и вы можете указать начало слева или начало справа, или с помощью php, Вы можете сделать взрыв, чтобы отразить строку).
Я считаю, что вам нужны подвыражения. Если я правильно помню, вы можете использовать обычный () скобки для подвыражений.
Эта часть из руководства grep:
Back References and Subexpressions
The back-reference \n, where n is a single digit, matches the substring
previously matched by the nth parenthesized subexpression of the
regular expression.
Сделать что-то вроде ^[^(abc)] должен сделать свое дело.
Попробуй это
.+?efg
Запрос:
select REGEXP_REPLACE ('abcdefghijklmn','.+?efg', '') FROM dual;
выход:
hijklmn