Как импортировать массовые данные из CSV в DynamodB
Я пытаюсь импортировать csv данные файла в DynamodB.
пожалуйста, дайте мне предложение к нему.
first_name last_name
sri ram
Rahul Dravid
JetPay Underwriter
Anil Kumar Gurram
18 ответов
На каком языке вы хотите импортировать данные. Я просто пишу функцию в nodejs, которая может импортировать CSV-файл в таблицу DynamodB. Сначала анализируется весь CSV в массив, разбивается массив на куски (25), а затем batchWriteItem в таблицу.
Примечание: DynamoDB допускает от 1 до 25 записей одновременно в batchinsert. Таким образом, мы должны разделить наш массив на куски.
var fs = require('fs');
var parse = require('csv-parse');
var async = require('async');
var csv_filename = "YOUR_CSV_FILENAME_WITH_ABSOLUTE_PATH";
rs = fs.createReadStream(csv_filename);
parser = parse({
columns : true,
delimiter : ','
}, function(err, data) {
var split_arrays = [], size = 25;
while (data.length > 0) {
split_arrays.push(data.splice(0, size));
}
data_imported = false;
chunk_no = 1;
async.each(split_arrays, function(item_data, callback) {
ddb.batchWriteItem({
"TABLE_NAME" : item_data
}, {}, function(err, res, cap) {
console.log('done going next');
if (err == null) {
console.log('Success chunk #' + chunk_no);
data_imported = true;
} else {
console.log(err);
console.log('Fail chunk #' + chunk_no);
data_imported = false;
}
chunk_no++;
callback();
});
}, function() {
// run after loops
console.log('all data imported....');
});
});
rs.pipe(parser);
Обновлен код Javascript 2019 года
Мне не повезло ни с одним из приведенных выше примеров кода Javascript. Начиная с ответа Хасана Сиддика, приведенного выше, я обновил до последней версии API, включил пример кода учетных данных, переместил всю пользовательскую конфигурацию в начало, добавил uuid() при отсутствии и удалил пустые строки.
const fs = require('fs');
const parse = require('csv-parse');
const async = require('async');
const uuid = require('uuid/v4');
const AWS = require('aws-sdk');
// --- start user config ---
const AWS_CREDENTIALS_PROFILE = 'serverless-admin';
const CSV_FILENAME = "./majou.csv";
const DYNAMODB_REGION = 'eu-central-1';
const DYNAMODB_TABLENAME = 'entriesTable';
// --- end user config ---
const credentials = new AWS.SharedIniFileCredentials({
profile: AWS_CREDENTIALS_PROFILE
});
AWS.config.credentials = credentials;
const docClient = new AWS.DynamoDB.DocumentClient({
region: DYNAMODB_REGION
});
const rs = fs.createReadStream(CSV_FILENAME);
const parser = parse({
columns: true,
delimiter: ','
}, function(err, data) {
var split_arrays = [],
size = 25;
while (data.length > 0) {
split_arrays.push(data.splice(0, size));
}
data_imported = false;
chunk_no = 1;
async.each(split_arrays, function(item_data, callback) {
const params = {
RequestItems: {}
};
params.RequestItems[DYNAMODB_TABLENAME] = [];
item_data.forEach(item => {
for (key of Object.keys(item)) {
// An AttributeValue may not contain an empty string
if (item[key] === '')
delete item[key];
}
params.RequestItems[DYNAMODB_TABLENAME].push({
PutRequest: {
Item: {
id: uuid(),
...item
}
}
});
});
docClient.batchWrite(params, function(err, res, cap) {
console.log('done going next');
if (err == null) {
console.log('Success chunk #' + chunk_no);
data_imported = true;
} else {
console.log(err);
console.log('Fail chunk #' + chunk_no);
data_imported = false;
}
chunk_no++;
callback();
});
}, function() {
// run after loops
console.log('all data imported....');
});
});
rs.pipe(parser);
Я создал драгоценный камень для этого.
Теперь вы можете установить его, запустив gem install dynamocli, тогда вы можете использовать команду:
dynamocli import your_data.csv --to your_table
Вот ссылка на исходный код: https://github.com/matheussilvasantos/dynamocli
Как простой разработчик без разрешений для создания конвейера данных, мне пришлось использовать этот javascript. Код Хасана Сидика немного устарел, но у меня это сработало:
var fs = require('fs');
var parse = require('csv-parse');
var async = require('async');
const AWS = require('aws-sdk');
const dynamodbDocClient = new AWS.DynamoDB({ region: "eu-west-1" });
var csv_filename = "./CSV.csv";
rs = fs.createReadStream(csv_filename);
parser = parse({
columns : true,
delimiter : ','
}, function(err, data) {
var split_arrays = [], size = 25;
while (data.length > 0) {
//split_arrays.push(data.splice(0, size));
let cur25 = data.splice(0, size)
let item_data = []
for (var i = cur25.length - 1; i >= 0; i--) {
const this_item = {
"PutRequest" : {
"Item": {
// your column names here will vary, but you'll need do define the type
"Title": {
"S": cur25[i].Title
},
"Col2": {
"N": cur25[i].Col2
},
"Col3": {
"N": cur25[i].Col3
}
}
}
};
item_data.push(this_item)
}
split_arrays.push(item_data);
}
data_imported = false;
chunk_no = 1;
async.each(split_arrays, (item_data, callback) => {
const params = {
RequestItems: {
"tagPerformance" : item_data
}
}
dynamodbDocClient.batchWriteItem(params, function(err, res, cap) {
if (err === null) {
console.log('Success chunk #' + chunk_no);
data_imported = true;
} else {
console.log(err);
console.log('Fail chunk #' + chunk_no);
data_imported = false;
}
chunk_no++;
callback();
});
}, () => {
// run after loops
console.log('all data imported....');
});
});
rs.pipe(parser);Вы можете использовать AWS Data Pipeline для таких вещей. Вы можете загрузить свой csv файл в S3, а затем использовать Data Pipeline для извлечения и заполнения таблицы DynamoDB. У них есть пошаговое руководство.
Я написал инструмент для этого с использованием параллельного выполнения, который не требует никаких зависимостей или инструментов разработчика, установленных на машине (он написан на Go).
Он может обрабатывать:
- Файлы с разделителями-запятыми (CSV)
- Файлы с разделением табуляцией (TSV)
- Большие файлы
- Локальные файлы
- Файлы на S3
- Параллельный импорт в AWS с использованием AWS Step Functions для импорта> 4 млн строк в минуту
- Нет зависимостей (нет необходимости в.NET, Python, Node.js, Docker, AWS CLI и т. Д.)
Он доступен для MacOS, Linux, Windows и Docker: https://github.com/a-h/ddbimport
Вот результаты моих тестов, показывающие, что с помощью AWS Step Functions параллельный импорт может выполняться намного быстрее.
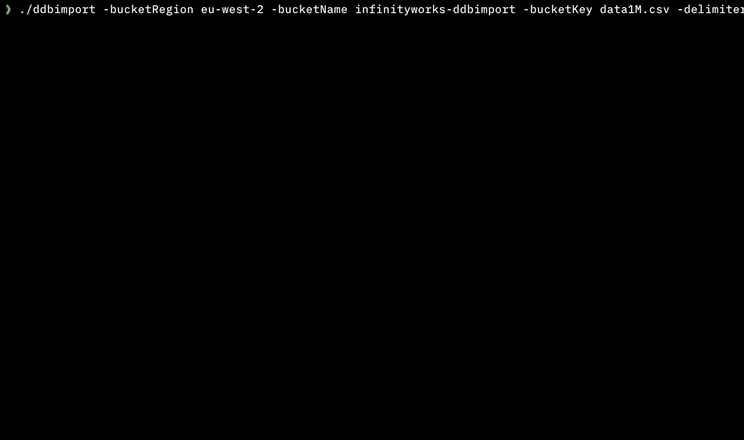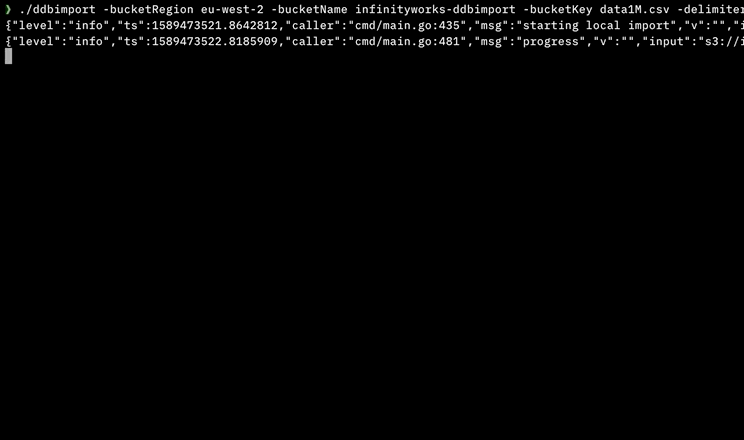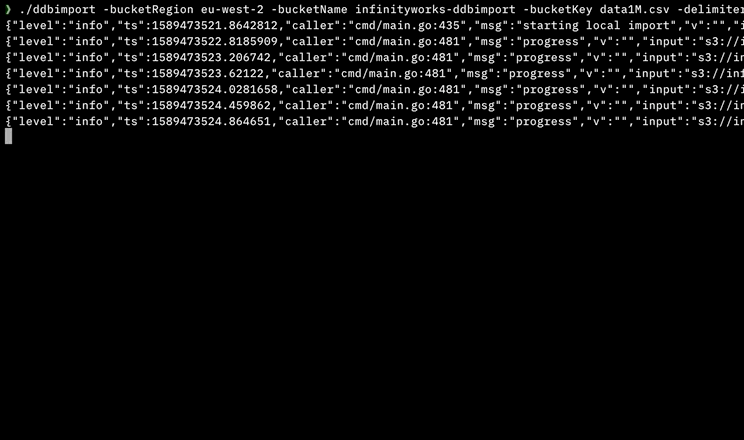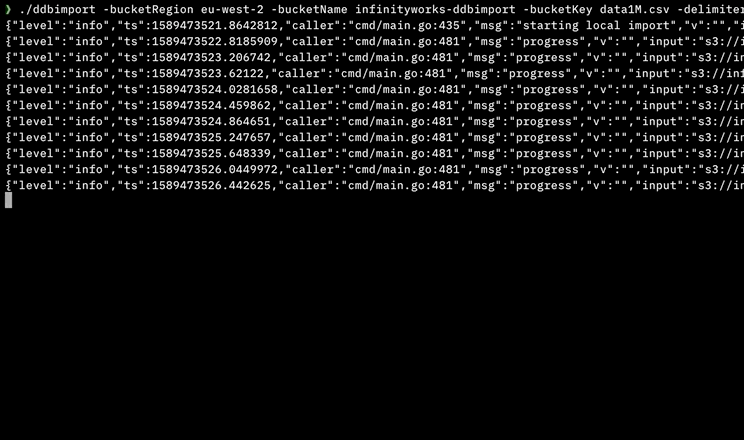
Я описываю инструмент более подробно на AWS Community Summit 15 мая 2020 года в 1155 BST - https://www.twitch.tv/awscomsum
Прежде чем перейти к моему коду, некоторые замечания по тестированию этого локально
Я рекомендую использовать локальную версию DynamoDB, на случай, если вы захотите проверить это, прежде чем начинать платить, а что нет. Я сделал несколько небольших изменений, прежде чем опубликовать это, так что не забудьте протестировать с любыми средствами, которые имеют смысл для вас. Я прокомментировал фиктивное задание на пакетную загрузку, которое вы можете использовать вместо любой службы DynamoDB, удаленной или локальной, чтобы проверить в stdout, что это работает в соответствии с вашими потребностями.
dynamodb-местный
Смотрите Dynamodb-локальный на npmjs или ручной установки
Если вы пошли по пути ручной установки, вы можете запустить DynamodB-Local примерно так:
java -Djava.library.path=<PATH_TO_DYNAMODB_LOCAL>/DynamoDBLocal_lib/\
-jar <PATH_TO_DYNAMODB_LOCAL>/DynamoDBLocal.jar\
-inMemory\
-sharedDb
Маршрут npm может быть проще.
dynamodb-админ
Наряду с этим, смотрите Dynamodb-Admin.
Я установил DynamodB-Admin с npm i -g dynamodb-admin, Затем он может быть запущен с:
dynamodb-admin
Используя их:
DynamoDB-локальный по умолчанию localhost:8000,
Dynamodb-admin - это веб-страница, по умолчанию localhost:8001, После запуска этих двух служб откройте localhost:8001 в вашем браузере для просмотра и управления базой данных.
Сценарий ниже не создает базу данных. использование dynamodb-admin за это.
Кредит идет на...
Код
- Я не так опытен с JS & Node.js, как с другими языками, поэтому, пожалуйста, прости меня за любые ошибки в JS.
- Вы заметите, что каждая группа одновременных пакетов намеренно замедляется на 900 мс. Это было хакерское решение, и я оставляю его здесь в качестве примера (и из-за лени, и из-за того, что вы мне не платите).
- Если вы увеличите MAX_CONCURRENT_BATCHES, вам нужно будет рассчитать соответствующую величину задержки на основе вашего WCU, размера элемента, размера пакета и нового уровня параллелизма.
- Другой подход заключается в том, чтобы включить автоматическое масштабирование и реализовать экспоненциальный откат для каждой неудачной партии. Как я упомянул ниже в одном из комментариев, это действительно не должно быть необходимо с некоторыми вычислениями за пределами конверта, чтобы выяснить, сколько записей вы действительно можете сделать, учитывая ваш лимит WCU и размер данных, и просто код выполняется с предсказуемой скоростью все время.
- Вы можете удивиться, почему я не позволил AWS SDK обрабатывать параллелизм. Хороший вопрос. Вероятно, сделал бы это немного проще. Вы можете поэкспериментировать, применив MAX_CONCURRENT_BATCHES к
maxSocketsпараметр config и изменение кода, который создает массивы пакетов, чтобы он передавал только отдельные пакеты вперед.
/**
* Uploads CSV data to DynamoDB.
*
* 1. Streams a CSV file line-by-line.
* 2. Parses each line to a JSON object.
* 3. Collects batches of JSON objects.
* 4. Converts batches into the PutRequest format needed by AWS.DynamoDB.batchWriteItem
* and runs 1 or more batches at a time.
*/
const AWS = require("aws-sdk")
const chalk = require('chalk')
const fs = require('fs')
const split = require('split2')
const uuid = require('uuid')
const through2 = require('through2')
const { Writable } = require('stream');
const { Transform } = require('stream');
const CSV_FILE_PATH = __dirname + "/../assets/whatever.csv"
// A whitelist of the CSV columns to ingest.
const CSV_KEYS = [
"id",
"name",
"city"
]
// Inadequate WCU will cause "insufficient throughput" exceptions, which in this script are not currently
// handled with retry attempts. Retries are not necessary as long as you consistently
// stay under the WCU, which isn't that hard to predict.
// The number of records to pass to AWS.DynamoDB.DocumentClient.batchWrite
// See https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_BatchWriteItem.html
const MAX_RECORDS_PER_BATCH = 25
// The number of batches to upload concurrently.
// https://docs.aws.amazon.com/sdk-for-javascript/v2/developer-guide/node-configuring-maxsockets.html
const MAX_CONCURRENT_BATCHES = 1
// MAKE SURE TO LAUNCH `dynamodb-local` EXTERNALLY FIRST IF USING LOCALHOST!
AWS.config.update({
region: "us-west-1"
,endpoint: "http://localhost:8000" // Comment out to hit live DynamoDB service.
});
const db = new AWS.DynamoDB()
// Create a file line reader.
var fileReaderStream = fs.createReadStream(CSV_FILE_PATH)
var lineReaderStream = fileReaderStream.pipe(split())
var linesRead = 0
// Attach a stream that transforms text lines into JSON objects.
var skipHeader = true
var csvParserStream = lineReaderStream.pipe(
through2(
{
objectMode: true,
highWaterMark: 1
},
function handleWrite(chunk, encoding, callback) {
// ignore CSV header
if (skipHeader) {
skipHeader = false
callback()
return
}
linesRead++
// transform line into stringified JSON
const values = chunk.toString().split(',')
const ret = {}
CSV_KEYS.forEach((keyName, index) => {
ret[keyName] = values[index]
})
ret.line = linesRead
console.log(chalk.cyan.bold("csvParserStream:",
"line:", linesRead + ".",
chunk.length, "bytes.",
ret.id
))
callback(null, ret)
}
)
)
// Attach a stream that collects incoming json lines to create batches.
// Outputs an array (<= MAX_CONCURRENT_BATCHES) of arrays (<= MAX_RECORDS_PER_BATCH).
var batchingStream = (function batchObjectsIntoGroups(source) {
var batchBuffer = []
var idx = 0
var batchingStream = source.pipe(
through2.obj(
{
objectMode: true,
writableObjectMode: true,
highWaterMark: 1
},
function handleWrite(item, encoding, callback) {
var batchIdx = Math.floor(idx / MAX_RECORDS_PER_BATCH)
if (idx % MAX_RECORDS_PER_BATCH == 0 && batchIdx < MAX_CONCURRENT_BATCHES) {
batchBuffer.push([])
}
batchBuffer[batchIdx].push(item)
if (MAX_CONCURRENT_BATCHES == batchBuffer.length &&
MAX_RECORDS_PER_BATCH == batchBuffer[MAX_CONCURRENT_BATCHES-1].length)
{
this.push(batchBuffer)
batchBuffer = []
idx = 0
} else {
idx++
}
callback()
},
function handleFlush(callback) {
if (batchBuffer.length) {
this.push(batchBuffer)
}
callback()
}
)
)
return (batchingStream);
})(csvParserStream)
// Attach a stream that transforms batch buffers to collections of DynamoDB batchWrite jobs.
var databaseStream = new Writable({
objectMode: true,
highWaterMark: 1,
write(batchBuffer, encoding, callback) {
console.log(chalk.yellow(`Batch being processed.`))
// Create `batchBuffer.length` batchWrite jobs.
var jobs = batchBuffer.map(batch =>
buildBatchWriteJob(batch)
)
// Run multiple batch-write jobs concurrently.
Promise
.all(jobs)
.then(results => {
console.log(chalk.bold.red(`${batchBuffer.length} batches completed.`))
})
.catch(error => {
console.log( chalk.red( "ERROR" ), error )
callback(error)
})
.then( () => {
console.log( chalk.bold.red("Resuming file input.") )
setTimeout(callback, 900) // slow down the uploads. calculate this based on WCU, item size, batch size, and concurrency level.
})
// return false
}
})
batchingStream.pipe(databaseStream)
// Builds a batch-write job that runs as an async promise.
function buildBatchWriteJob(batch) {
let params = buildRequestParams(batch)
// This was being used temporarily prior to hooking up the script to any dynamo service.
// let fakeJob = new Promise( (resolve, reject) => {
// console.log(chalk.green.bold( "Would upload batch:",
// pluckValues(batch, "line")
// ))
// let t0 = new Date().getTime()
// // fake timing
// setTimeout(function() {
// console.log(chalk.dim.yellow.italic(`Batch upload time: ${new Date().getTime() - t0}ms`))
// resolve()
// }, 300)
// })
// return fakeJob
let promise = new Promise(
function(resolve, reject) {
let t0 = new Date().getTime()
let printItems = function(msg, items) {
console.log(chalk.green.bold(msg, pluckValues(batch, "id")))
}
let processItemsCallback = function (err, data) {
if (err) {
console.error(`Failed at batch: ${pluckValues(batch, "line")}, ${pluckValues(batch, "id")}`)
console.error("Error:", err)
reject()
} else {
var params = {}
params.RequestItems = data.UnprocessedItems
var numUnprocessed = Object.keys(params.RequestItems).length
if (numUnprocessed != 0) {
console.log(`Encountered ${numUnprocessed}`)
printItems("Retrying unprocessed items:", params)
db.batchWriteItem(params, processItemsCallback)
} else {
console.log(chalk.dim.yellow.italic(`Batch upload time: ${new Date().getTime() - t0}ms`))
resolve()
}
}
}
db.batchWriteItem(params, processItemsCallback)
}
)
return (promise)
}
// Build request payload for the batchWrite
function buildRequestParams(batch) {
var params = {
RequestItems: {}
}
params.RequestItems.Provider = batch.map(obj => {
let item = {}
CSV_KEYS.forEach((keyName, index) => {
if (obj[keyName] && obj[keyName].length > 0) {
item[keyName] = { "S": obj[keyName] }
}
})
return {
PutRequest: {
Item: item
}
}
})
return params
}
function pluckValues(batch, fieldName) {
var values = batch.map(item => {
return (item[fieldName])
})
return (values)
}
Вот мое решение. Я полагался на тот факт, что был какой-то тип заголовка, указывающий, что столбец сделал, что. Просто и прямо. Нет конвейера ерунды для быстрой загрузки..
import os, json, csv, yaml, time
from tqdm import tqdm
# For Database
import boto3
# Variable store
environment = {}
# Environment variables
with open("../env.yml", 'r') as stream:
try:
environment = yaml.load(stream)
except yaml.YAMLError as exc:
print(exc)
# Get the service resource.
dynamodb = boto3.resource('dynamodb',
aws_access_key_id=environment['AWS_ACCESS_KEY'],
aws_secret_access_key=environment['AWS_SECRET_KEY'],
region_name=environment['AWS_REGION_NAME'])
# Instantiate a table resource object without actually
# creating a DynamoDB table. Note that the attributes of this table
# are lazy-loaded: a request is not made nor are the attribute
# values populated until the attributes
# on the table resource are accessed or its load() method is called.
table = dynamodb.Table('data')
# Header
header = []
# Open CSV
with open('export.csv') as csvfile:
reader = csv.reader(csvfile,delimiter=',')
# Parse Each Line
with table.batch_writer() as batch:
for index,row in enumerate(tqdm(reader)):
if index == 0:
#save the header to be used as the keys
header = row
else:
if row == "":
continue
# Create JSON Object
# Push to DynamoDB
data = {}
# Iterate over each column
for index,entry in enumerate(header):
data[entry.lower()] = row[index]
response = batch.put_item(
Item=data
)
# Repeat
Другой быстрый обходной путь - сначала загрузить CSV в RDS или любой другой экземпляр mysql, что довольно легко сделать ( https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html), а затем использовать DMS. (Служба миграции баз данных AWS) для загрузки всех данных в DynamodB. Вам нужно будет создать роль для DMS, прежде чем вы сможете загрузить данные. Но это прекрасно работает без запуска каких-либо сценариев.
Я использовал https://github.com/GorillaStack/dynamodb-csv-export-import. Это очень просто и работает как шарм. Я просто выполнил инструкции в README:
# Install globally
npm i -g @gorillastack/dynamodb-csv-export-import
# Set AWS region
export AWS_DEFAULT_REGION=us-east-1
# Use it for your CSV and dynamo table
dynamodb-csv-export-import my-exported-file.csv MyDynamoDbTableName
Я испробовал все эти подходы, и все они мне не помогли. Для этого я создал минимальный скрипт Python.
(1 файл, 40 строк)
git clone https://github.com/alramalho/csv-into-dynamodb
python csv-into-dynamodb/run.py --file file.csv --table table_name
Не стесняйтесь внести свой вклад.
Самым простым решением, вероятно, является использование шаблона / решения, созданного AWS:
Реализация массового приема CSV в Amazon DynamoDB https://aws.amazon.com/blogs/database/implementing-bulk-csv-ingestion-to-amazon-dynamodb/
При таком подходе вы используете предоставленный шаблон для создания стека CloudFormation, включая корзину S3, функцию Lambda и новую таблицу DynamoDB. Лямбда запускается при загрузке в корзину S3 и вставляется в таблицу партиями.
В моем случае я хотел вставить в существующую таблицу, поэтому я просто изменил переменную среды лямбда-функции после создания стека.
Теперь вы можете выполнять массовый импорт в DynamoDB в форматах CSV, DynamoDB JSON или Amazon Ion. Это требует, чтобы ваши данные присутствовали в корзине S3. Код не требуется.
документы — https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/S3DataImport.HowItWorks.html
Ключевые соображения при использовании этой встроенной функции, особенно для данных CSV:
- Вы можете указать ключ раздела (PK)/ключ сортировки (SK) таблицы и их типы данных, а также все другие
CreateTableпараметры - В настоящее время функция поддерживает только импорт в новую таблицу каждый раз
- Данные с одинаковыми PK и SK будут перезаписаны (аналогично
PutItemоперация) - За исключением PK и SK, все остальные поля в CSV будут считаться строками DynamoDB. Если это нежелательно, вы можете преобразовать данные в формат DynamoDB JSON/Amazon Ion перед импортом с явными типами данных.
- Любые глобальные вторичные индексы, созданные как часть операции, будут заполняться бесплатно. Стоимость импорта зависит от размера несжатых исходных данных.
- GSI, созданные во время импорта, также будут отображать типы данных в соответствии с исходными данными. Однако все неключевые атрибуты по-прежнему будут считаться строками DynamoDB.
-
ImportTableне потребляет емкость записи в таблице, поэтому вы можете создать таблицу с 1 WCU, а производительность импорта будет такой же, как у ImportTable, выполненного для таблицы со 100 000 WCU.
Один из способов импорта / экспорта материалов:
"""
Batch-writes data from a file to a dynamo-db database.
"""
import json
import boto3
# Get items from DynamoDB table like this:
# aws dynamodb scan --table-name <table-name>
# Create dynamodb client.
client = boto3.client(
'dynamodb',
aws_access_key_id='',
aws_secret_access_key=''
)
with open('', 'r') as file:
data = json.loads(file.read())['Items']
# Execute write-data request for each item.
for item in data:
client.put_item(
TableName='',
Item=item
)
Вот более простое решение. И с этим решением вам не нужно удалять пустые строковые атрибуты.
require('./env'); //contains aws secret/access key
const parse = require('csvtojson');
const AWS = require('aws-sdk');
// --- start user config ---
const CSV_FILENAME = __dirname + "/002_subscribers_copy_from_db.csv";
const DYNAMODB_TABLENAME = '002-Subscribers';
// --- end user config ---
//You could add your credentials here or you could
//store it in process.env like I have done aws-sdk
//would detect the keys in the environment
AWS.config.update({
region: process.env.AWS_REGION
});
const db = new AWS.DynamoDB.DocumentClient({
convertEmptyValues: true
});
(async ()=>{
const json = await parse().fromFile(CSV_FILENAME);
//this is efficient enough if you're processing small
//amounts of data. If your data set is large then I
//suggest using dynamodb method .batchWrite() and send
//in data in chunks of 25 (the limit) and find yourself
//a more efficient loop if there is one
for(var i=0; i<json.length; i++){
console.log(`processing item number ${i+1}`);
let query = {
TableName: DYNAMODB_TABLENAME,
Item: json[i]
};
await db.put(query).promise();
/**
* Note: If "json" contains other nested objects, you would have to
* loop through the json and parse all child objects.
* likewise, you would have to convert all children into their
* native primitive types because everything would be represented
* as a string.
*/
}
console.log('\nDone.');
})();
Следуйте инструкциям в следующей ссылке, чтобы импортировать данные в существующие таблицы в DynamoDB:
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SampleData.LoadData.html
Обратите внимание, названия таблиц - это то, что вы должны найти здесь: https://console.aws.amazon.com/dynamodbv2/home
И имя таблицы используется внутри файла json, имя самого файла json значения не имеет. Например, у меня есть таблица как
Country-kdezpod7qrap7nhpjghjj-staging, то для импорта данных в эту таблицу я должен создать такой файл json:
{
"Country-kdezpod7qrap7nhpjghjj-staging": [
{
"PutRequest": {
"Item": {
"id": {
"S": "ir"
},
"__typename": {
"S": "Country"
},
"createdAt": {
"S": "2021-01-04T12:32:09.012Z"
},
"name": {
"S": "Iran"
},
"self": {
"N": "1"
},
"updatedAt": {
"S": "2021-01-04T12:32:09.012Z"
}
}
}
}
]
}
Если вы не знаете, как создавать элементы для каждого PutRequest, вы можете создать элемент в своей БД с мутацией, а затем попытаться продублировать его, тогда он покажет вам структуру одного элемента:
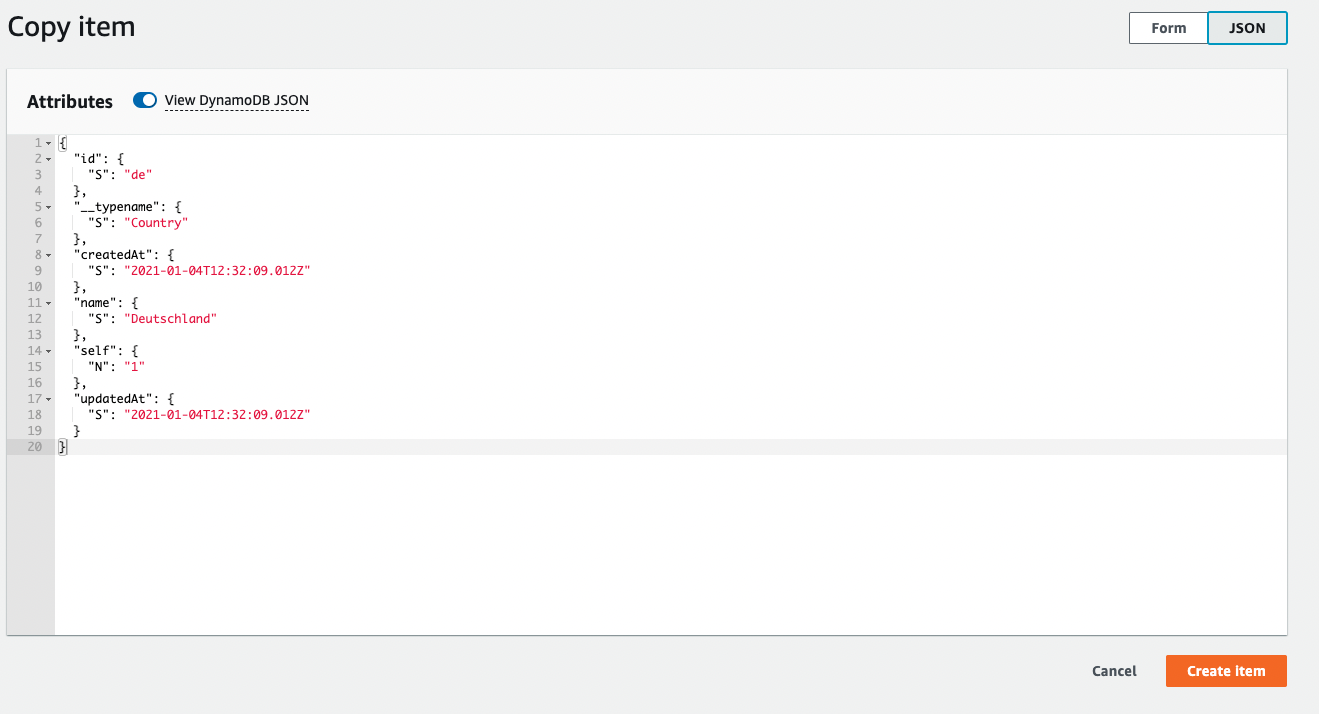
Если у вас есть огромный список элементов в вашем CSV-файле, вы можете использовать следующий инструмент npm для создания json-файла:
https://www.npmjs.com/package/json-dynamo-putrequest
Затем мы можем использовать следующую команду для импорта данных:
aws dynamodb batch-write-item --request-items file://Country.json
Если он успешно импортирует данные, вы должны увидеть следующий вывод:
{
"UnprocessedItems": {}
}
Также обратите внимание, что с помощью этого метода у вас может быть только 25
PutRequestэлементы в вашем массиве. Итак, если вы хотите протолкнуть 100 элементов, вам нужно создать 4 файла.
Вы можете попробовать использовать пакетную запись и многопроцессорную обработку для ускорения массового импорта.
import csv
import time
import boto3
from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool(4)
current_milli_time = lambda: int(round(time.time() * 1000))
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('table_name')
def add_users_in_batch(data):
with table.batch_writer() as batch:
for item in data:
batch.put_item(Item = item)
def run_batch_migration():
start = current_milli_time()
row_count = 0
batch = []
batches = []
with open(CSV_PATH, newline = '') as csvfile:
reader = csv.reader(csvfile, delimiter = '\t', quotechar = '|')
for row in reader:
row_count += 1
item = {
'email': row[0],
'country': row[1]
}
batch.append(item)
if row_count % 25 == 0:
batches.append(batch)
batch = []
batches.append(batch)
pool.map(add_users_in_batch, batches)
print('Number of rows processed - ', str(row_count))
end = current_milli_time()
print('Total time taken for migration : ', str((end - start) / 1000), ' secs')
if __name__ == "__main__":
run_batch_migration()