Как оптимизировать случайный разлив в приложении Apache Spark
Я запускаю потоковое приложение Spark с двумя рабочими. Приложение имеет операции объединения и объединения.
Все партии успешно завершаются, но заметили, что метрики случайного разлива не соответствуют размеру входных или выходных данных (объем разлива превышает 20 раз).
Пожалуйста, найдите детали стадии искры на изображении ниже: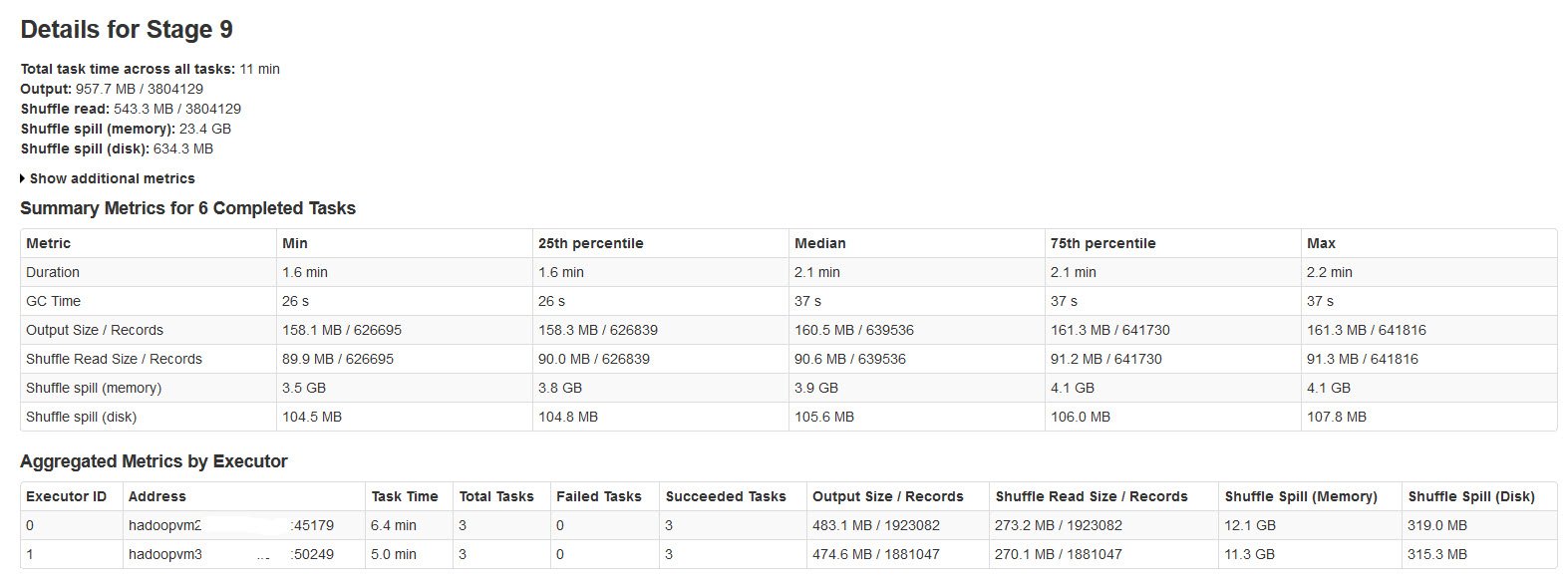
Изучив это, обнаружил, что
Случайный разлив происходит, когда не хватает памяти для случайных данных.
Shuffle spill (memory) - размер десериализованной формы данных в памяти на момент пролива
shuffle spill (disk) - размер сериализованной формы данных на диске после разлива
Поскольку десериализованные данные занимают больше места, чем сериализованные данные. Итак, Shuffle spill (память) больше.
Заметил, что этот объем памяти разлива невероятно большой с большими входными данными.
Мои запросы:
Влияет ли это проливание на производительность?
Как оптимизировать этот разлив как памяти, так и диска?
Существуют ли какие-либо свойства искр, которые могут уменьшить / контролировать этот огромный разлив?
1 ответ
Обучение настройке производительности Spark требует немало исследований и обучения. Есть несколько хороших ресурсов, включая это видео. Spark 1.4 имеет улучшенную диагностику и визуализацию в интерфейсе, которая может вам помочь.
Таким образом, вы получите, когда размер разделов RDD в конце этапа превысит объем памяти, доступный для буфера перемешивания.
Вы можете:
- Вручную
repartition()ваш предыдущий этап, так что у вас есть меньшие разделы от ввода. - Увеличьте буфер перемешивания, увеличив память в ваших процессорах-исполнителях (
spark.executor.memory) - Увеличьте буфер перемешивания, увеличив долю памяти, выделяемой для него (
spark.shuffle.memoryFraction) по умолчанию 0,2. Вы должны вернутьspark.storage.memoryFraction, - Увеличение буфера перемешивания на поток за счет уменьшения соотношения рабочих потоков (
SPARK_WORKER_CORES) памяти исполнителя
Если есть опытный слушатель, я хотел бы узнать больше о том, как взаимодействуют настройки памяти и их разумный диапазон.
Чтобы добавить к приведенному выше ответу, вы также можете рассмотреть возможность увеличения числа разделов по умолчанию (spark.sql.shuffle.partitions) с 200 (при случайном перемешивании) до числа, которое приведет к разделам размером, близким к размеру блока hdfs (т.е. от 128 МБ до 256 МБ)
Если ваши данные искажены, попробуйте уловки вроде "соления ключей" для увеличения параллелизма.
Прочтите это, чтобы понять управление искровой памятью:
https://0x0fff.com/spark-memory-management/
https://www.tutorialdocs.com/article/spark-memory-management.html