Как изменить критерии разделения (Джини / энтропия) в алгоритме дерева решений в Scikit-Learn?
Я работаю с алгоритмом дерева решений по проблеме двоичной классификации, и цель состоит в том, чтобы минимизировать ложные срабатывания (максимизировать positive predicted value) классификации (стоимость диагностического инструмента очень высока).
Есть ли способ ввести weight в критериях расщепления Джини / энтропии, чтобы оштрафовать за ложноположительные ошибочные классификации?
Вот например, модифицированный индекс Джини дается как:

Поэтому мне интересно, есть ли способ реализовать это в Scikit-learn?
РЕДАКТИРОВАТЬ
Играть с class_weight дал следующие результаты:
from sklearn import datasets as dts
iris_data = dts.load_iris()
X, y = iris_data.features, iris_data.targets
# take only classes 1 and 2 due to less separability
X = X[y>0]
y = y[y>0]
y = y - 1 # make binary labels
# define the decision tree classifier with only two levels at most and no class balance
dt = tree.DecisionTreeClassifier(max_depth=2, class_weight=None)
# fit the model, no train/test for simplicity
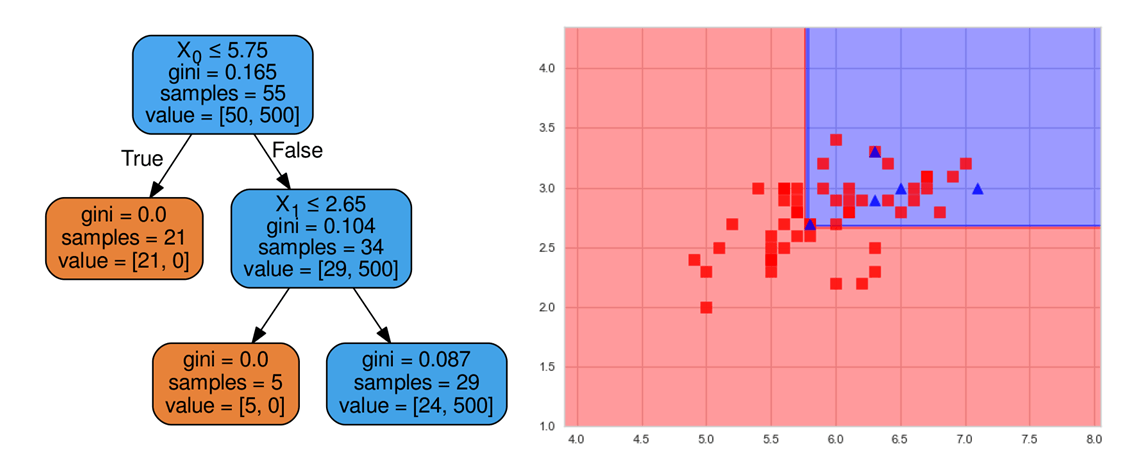
dt.fit(X[:55,:2], y[:55])
Построить границы решения и дерево Blue положительно (1):

При перевесе меньшинства (или более ценного):
dt_100 = tree.DecisionTreeClassifier (max_depth = 2, class_weight = {1: 100})
1 ответ
Классификаторы дерева решений поддерживают class_weight аргумент.
В двух классовых задачах это может точно решить вашу проблему. Обычно это используется для неуравновешенных проблем. Для более чем двух классов невозможно предоставить отдельные метки (насколько я знаю)