Парсер LR1 и Эпсилон
Я пытаюсь понять, как работают парсеры LR1, но у меня возникла странная проблема: что если грамматика содержит эпсилоны? Например: если у меня есть грамматика:
S -> A
A -> a A | B
B -> a
Понятно как начать:
S -> .A
A -> .a A
A -> .B
... и так далее
но я не знаю, как это сделать для такой грамматики:
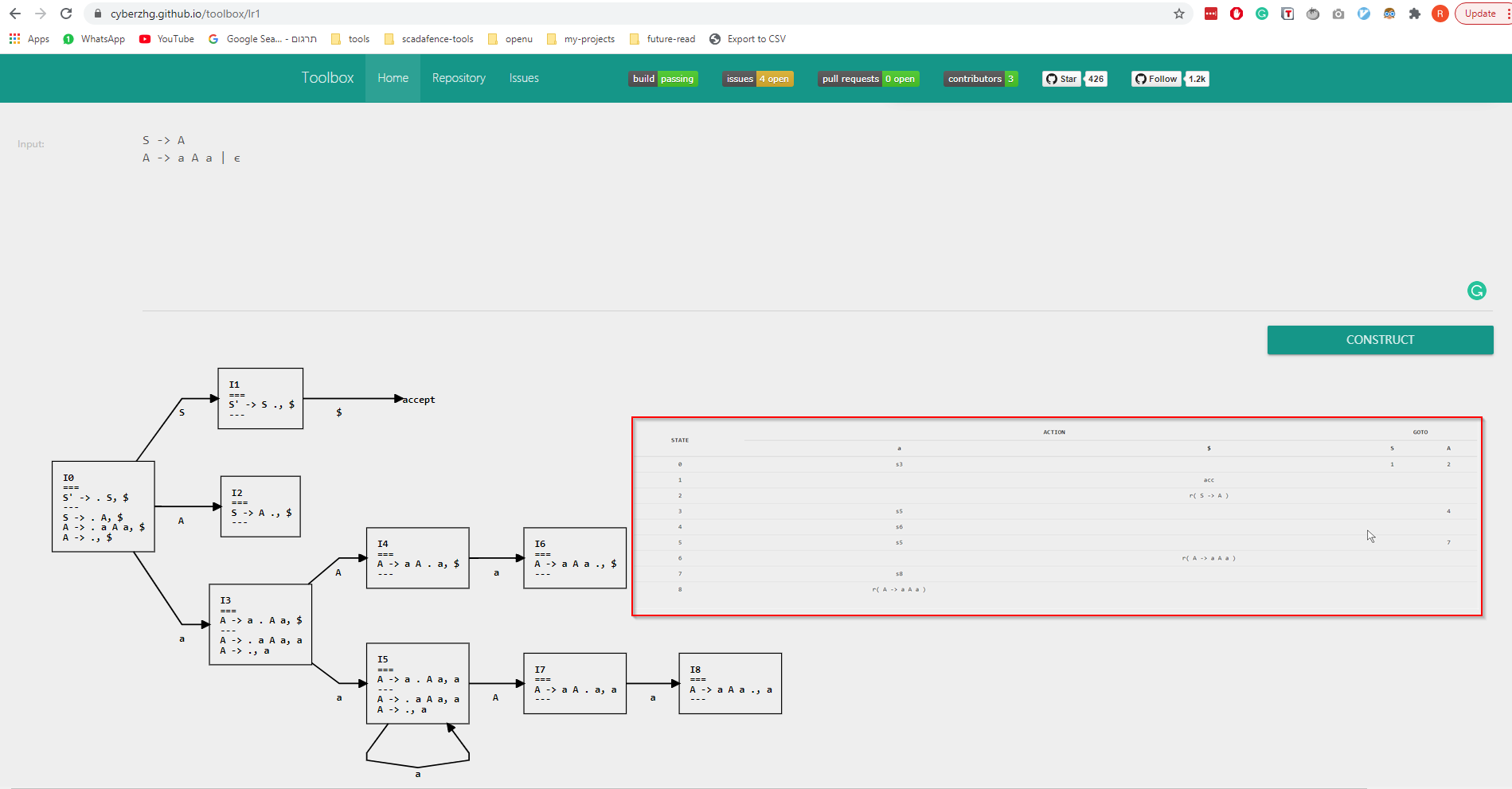
S -> A
A -> a A a | \epsilon
Это правильно сделать:
S -> .A
A -> .a A a
( A -> .\epsilon )
А потом сделать это государство в ДФА принимает?
Любая помощь будет принята с благодарностью!
2 ответа
Да, именно так (думайте о эпсилоне как о пустом месте, где нет двух точек для точки по бокам).
В автомате LR(0) вы можете принять состояние и уменьшить его до A. Однако из-за A->a A a производство, был бы конфликт сдвига / уменьшения.
В автомате LR(1) вы будете определять, сдвигать или уменьшать, используя прогнозирование (a -> сдвиг, что-нибудь в FOLLOW(A) -> уменьшить)
Вы можете использовать этот сайт для вычисления этого: https://cyberzhg.github.io/toolbox/lr1
Посмотрите результаты: