Как реализовать UnitOfWork с Entity Framework (и другими ORM). Некоторые данные в БД, некоторые в памяти
Изменено с: "Проверка доменной модели с Entity Framework (и другими ORM). Некоторые данные в БД, некоторые в памяти".
Изначально я думал, что реализация UoW с EF - это простая задача. Но оказалось, что это намного сложнее.
Когда бизнес-логика (где бы она ни находилась) запрашивает у хранилища сущность, она должна искать не только в базе данных, но и в локальном кеше. Хранилище не должно возвращать сущность, если она помечена для удаления в текущем UoW, но все еще существует в хранилище.
Частичная материализация графа приносит сложность. Нет сомнений в том, что мы забываем о постоянстве и делаем вид, что все живет в памяти: загружаем все, меняем его по своему усмотрению и затем записываем результирующие изменения в db Как легко, как это возможно.
Чтобы добавить больше деталей:
Обработчик сообщения аутентификации устанавливает Принципал.
Где-то в глубине моего BL мне нужно проверить, может ли текущий аутентифицированный пользователь выполнить действие.
У каждой роли есть действия, связанные с ней. Поэтому мне нужно найти все роли с действием и проверить, что пользователь в роли. Однако есть вероятность, что во время обработки запроса пользователь был удален из роли. Эта информация об удалении (или добавлении) хранится в UoW, но еще не сохранена. Поэтому, если моя логика проверки запрашивает только БД, она может получить ответ, который не согласуется с рабочим процессом.
Вероятно, я неправильно устанавливаю границу UoW, и она не должна пересекать отдельную операцию BL:
- Удалить пользователя из роли - изменения пошли в БД
- Проверить роли пользователя - получить состояние из БД
Хотя BL может иметь вложенные вызовы при каждой записи в БД. Поэтому я чувствую, что можно позволить клиенту определить "размер" UoW.
Фаулер, описывающий UoF, говорит:
Вы можете изменять базу данных при каждом изменении вашей объектной модели, но это может привести к множеству очень маленьких обращений к базе данных, которые в итоге оказываются очень медленными. Кроме того, требуется, чтобы у вас была открытая транзакция для всего взаимодействия, что нецелесообразно, если у вас есть бизнес-транзакция, охватывающая несколько запросов. Ситуация еще хуже, если вам нужно отслеживать объекты, которые вы прочитали, чтобы избежать непоследовательного чтения.
Но поведение может потребовать последовательности изменений объекта. И каждое изменение должно знать о текущем состоянии - состоянии после предыдущих изменений, которые еще не были сохранены в БД.
Оригинальная формулировка вопроса:
Я немного запутался с шаблоном Repository и Unit of Work, реализованным в Entity Framework.
Во-первых, я позволяю моей модели находиться в недопустимом состоянии до фазы Commit() в UnitOfWork.
Простейший пример того, почему это полезно, - это семантика перемещения и переименования файлов.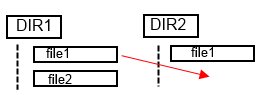
Если дело вам нужно переехать file1 в Dir2 и переименуйте его в file2 Нет простого способа сделать это, если у вас есть транзакционно раздельные операции перемещения и переименования.
Существует конфликт имен Dir1 или же Dir2,
Поэтому я считаю разумным разрешить модели временно иметь недопустимое состояние.
Теперь суть моей проблемы:
В моей бизнес-модели есть правило, которое требует анализа всех связанных объектов.
Я поместил логику проверки в родительскую сущность, которая логически содержит все эти элементы и, таким образом, отвечает за наложение и проверку ограничений. И я также хотел бы проверить ограничения уникальности.
Это может показаться немного параноидальным, но в этом случае я могу легко проверить свою логику с помощью модульных тестов, даже не используя базу данных.
Однако в тот момент, когда EF начинает процесс проверки, "будущее" состояние системы определяется как текущим контекстом (Добавленный, Удаленный, Измененный итемент), так и частью, которая не материализовалась в памяти и осталась в БД (не говоря уже о параллелизме). (Нет абсолютно никакой необходимости загружать все объекты в память).
Это требует, чтобы мой репозиторий был достаточно сложным, чтобы принять во внимание факт распределенного состояния. Я обнаружил, что это совсем не тривиальная задача.
Я хотел бы знать, как другие люди решили это. Может быть, есть лучшие подходы к этой проблеме.
2 ответа
На самом деле DDD очень прост. Это просто означает: моделировать понятия, поведение домена и варианты использования в коде. ORM или ЛЮБЫЕ данные о постоянстве (db) здесь не имеют места. Когда вы делаете DDD, БД не существует. Когда вы хотите что-то сохранить, вы отправляете это в хранилище. Когда вам нужно что-то из хранилища, вы просите репозиторий получить его.
DDD - это образ мышления, в котором основное внимание уделяется бизнесу, а не техническим деталям. Репозиторий - это "постоянство" с точки зрения домена. Конечно, Домен определяет только интерфейс репо (абстракцию), в то время как реализация репозитория находится в другом месте, обычно на уровне постоянства. Но вы можете иметь более одной реализации. При тестировании или простой разработке гораздо проще иметь хранилище в памяти (быстрое для записи), достаточно хорошее, чтобы действовать как "временный" БД, но без использования реального БД. Конечно, Doamin на самом деле не заботится о том, как реализован репо, и не должен, потому что цель репозитория состоит в том, чтобы отделить домен от деталей персистентности.
Так что EF, Nhibernate, NoSql и т. Д. Все это не имеет значения, домен знает только об интерфейсе репозитория. Реализация репо будет использовать все эти инструменты, но Домен не узнает об этом.
Более того, валидация доменной модели осуществляется Доменом. Репозиторий не выполняет проверку, он просто сохраняет / загружает данные из БД. Если вы имеете в виду проверку пользовательского ввода, это должно быть сделано до того, как данные поступят в домен, поскольку речь идет о форматировании данных. Однако все, что связано с бизнес-правилами, обеспечивается только Доменом.
Теперь я считаю, что нет общего способа реализации репозитория.
Каждый случай требует своего рассмотрения.
Рассмотрим этот кусок кода:
public TEntity FirstOrDefault(Expression<Func<TEntity, bool>> filter)
{
var compiledFilter = filter.Compile();
var entity = DbSet.Local.SingleOrDefault(compiledFilter); // first, look in local storage
if (entity != null)
{
return entity;
}
// Now we ask the database.
entity = DbSet.SingleOrDefault(filter);
// Entity from database can be already 'deleted' or changed locally.
// Modified local entity may not pass the filter so we should check this explicitly.
if (entity != null && !MatchesLocal(entity, compiledFilter))
{
entity = null;
}
return entity;
}
private bool MatchesLocal(TEntity entity, Func<TEntity, bool> filter)
{
Contract.Requires<ArgumentNullException>(entity != null);
Contract.Requires<ArgumentNullException>(filter != null);
var entry = Context.Entry(entity);
var deleted = entry.State == EntityState.Deleted;
var result = !deleted && filter(entity);
return result;
}
Это несколько соответствует диаграмме последовательности репозитория Фаулера.
Увы, есть предостережения. Если фильтрующее выражение использует свойства навигации и Lazy Load отключено, вполне вероятно, что получится исключение NullReferenceException. Если поиск выполняется по свойствам, отсутствующим в БД, будет другое исключение.
Возможно, преобразование выражений с помощью специального посетителя позволяет решить эту проблему, но это не простая задача.
Следующий момент - производительность. Когда нам просто нужно что-то проверить, нет смысла собирать кучу объектов.
Вот пример:
public bool VendorExistsWithName(string vendorName)
{
vendorName = vendorName.ToLower();
// look among local objects
var matchedLocalVendors = DbSet.Local
.Where(
vendor =>
vendor.Name.ToLower() == vendorName)
.ToList();
if (matchedLocalVendors.Count >= 0)
{
return true;
}
var deletedVendorIds = new HashSet<int>(GetDeleted().Select(vendor => vendor.VendorId));
var modifiedVendors = GetModified().ToDictionary(vendor => vendor.VendorId);
// ReSharper disable ReplaceWithSingleCallToAny
var exists = DbSet.Where(vendor => vendor.Name.ToLower() == vendorName)
.Select(vendor => vendor.VendorId)
.AsEnumerable()
.Where(id => !deletedVendorIds.Contains(id)) // not deleted
.Where(
id =>
!modifiedVendors.ContainsKey(id) ||
modifiedVendors[id].Name.ToLower() == vendorName)
.Any(); // matches even if modified
// ReSharper restore ReplaceWithSingleCallToAny
return exists;
}
Здесь мы получаем только идентификаторы вместо крупных объектов. Метод может быть обобщен, однако это требует усилий, чтобы получить и сгруппировать сущности по ключам, какими бы они ни были (простые или составные).
Все упомянутые функциональные возможности могут быть предоставлены Entity Framework из коробки. К сожалению, это не так.
И последнее, но не менее важное, - это ситуации, когда агрегатные функции следует, но нельзя использовать. Без надлежащего "слияния" состояния в памяти с состоянием БД это практически невозможно. С другой стороны, я не могу вспомнить случай, когда я хотел использовать агрегатные функции в моей бизнес-логике.
Подводя итог, я хотел бы сказать, что хотя реализация хорошего и согласованного репозитория с EF требует усилий, это не так страшно, как мне первоначально казалось.