Где находится Apache Kafka в теореме PACELC
Я начинаю узнавать об Apache Kafka. В этой https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka статье говорится, что Kafka - это система CA внутри CAP-теоремы. Поэтому основное внимание уделяется согласованности между репликами, а также общей доступности.
Недавно я слышал о расширении CAP-теоремы под названием PACELC ( https://en.wikipedia.org/wiki/PACELC_theorem). Эта теорема может быть визуализирована так:
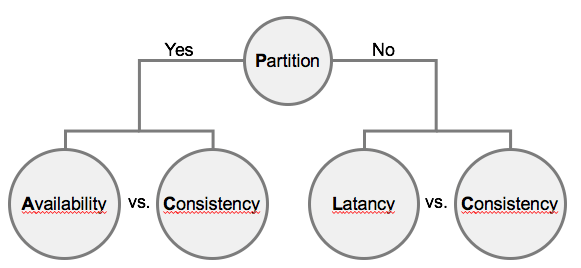
Мой вопрос в том, как можно описать Apache Kafka в PACELC. Я думаю, что Kafka сосредотачивается на согласованности, когда возникает раздел, но что иначе, если раздел не возникает? Сосредоточен ли он на низкой латентности или сильной последовательности?
Спасибо!
1 ответ
Это будет зависеть от вашей конфигурации.
Kafka поддерживается CP ZooKeeper для операций, которые требуют строгой согласованности, таких как выбор контроллера (который определяет лидеров разделов), регистрация брокера, динамические конфигурации, acl-s и т. Д.
Что касается даты, которую вы отправляете в kafka - гарантии настраиваются на уровне производителя, для каждой темы или / и меняются настройки брокера по умолчанию.
Из коробки с конфигурацией по умолчанию (min.insync.replicas=1, default.replication.factor=1) вы получаете систему AP (максимум один раз).
Если вы хотите достичь CP, вы можете установить min.insync.replicas=2 и коэффициент репликации темы 3 - затем производит сообщение с acks=all будет гарантировать установку CP (по крайней мере, один раз), но (как и ожидалось) будет блокироваться в тех случаях, когда недостаточно реплик (<2), доступных для конкретной пары тема / раздел. (см. design_ha, документы по конфигурации производителя)
Трубопровод Кафка может быть дополнительно настроен в одном направлении.
CAP и PACELC
Что касается PACELC, некоторые решения по улучшению задержки уже приняты по умолчанию. Например кафка по умолчанию не fsync Каждое сообщение на диск - оно записывает в pagecache и позволяет ОС справиться с сбросом. По умолчанию предпочитают использовать репликацию для долговечности. Его также можно настроить - смотрите flush.messages, flush.ms Конфигурации брокера / темы.
Из-за общего характера сообщений, которые он получает (это просто поток сообщений) - он не может выполнять слияние после раздела или использовать приемы CRDT, чтобы гарантировать доступность во время раздела и в конечном итоге восстановить согласованность.
Я не вижу / не знаю как ты можешь give up постоянство латентности во время normal operation в случае общего потока Кафки. Вы можете отказаться от строгой согласованности (линеаризуемости) и попытаться добиться " большей согласованности " (охватывающей чуть больше сценариев отказов или уменьшить размер потери данных), но это эффективно настраивает систему AP для более высокой согласованности, а не настраивает CP для более низкой задержки,
Вы могли бы видеть, что компромиссы и конфигурации AP/CP будут представлены как, по крайней мере, один раз, по крайней мере, один раз, по сравнению с единственным.
тестирование
Чтобы понять, как эти параметры влияют на задержку, я думаю, что лучший способ - это проверить вашу настройку с разными параметрами. Следующая команда сгенерирует 1 Гб данных:
kafka-producer-perf-test --topic test --num-records 1000000 --record-size 100 --throughput 10000000 --producer-props bootstrap.servers=kafka:9092 acks=all`
Затем попробуйте использовать разные параметры производителя:
acks=1
acks=all
acks=1 batch.size=1000000 linger.ms=1000
acks=all batch.size=1000000 linger.ms=1000
Легко запустить кластер и запустить / остановить / убить узлы для тестирования некоторых сценариев отказа, например, с помощью compose.
Ссылки и ссылки
Вы можете проверить (к сожалению, устаревший, но все еще актуальный для темы) тест jepsen и последующее наблюдение, просто чтобы добавить контекст того, как это развивалось с течением времени.
Я настоятельно рекомендую проверить некоторые документы, которые дадут немного больше перспективы:
Критика теоремы CAP. Мартин Клеппманн
CAP Двенадцать лет спустя: как изменились "Правила". Эрик Брюер