Как определить текстовый (строковый) язык в iOS?
Например, с учетом следующих строк:
let textEN = "The quick brown fox jumps over the lazy dog"
let textES = "El zorro marrón rápido salta sobre el perro perezoso"
let textAR = "الثعلب البني السريع يقفز فوق الكلب الكسول"
let textDE = "Der schnelle braune Fuchs springt über den faulen Hund"
Я хочу обнаружить используемый язык в каждой объявленной строке.
Предположим, что подпись для реализованной функции:
func detectedLangauge<T: StringProtocol>(_ forString: T) -> String?
возвращает необязательную строку в случае отсутствия обнаруженного языка.
таким образом, соответствующий результат будет:
let englishDetectedLangauge = detectedLangauge(textEN) // => English
let spanishDetectedLangauge = detectedLangauge(textES) // => Spanish
let arabicDetectedLangauge = detectedLangauge(textAR) // => Arabic
let germanDetectedLangauge = detectedLangauge(textDE) // => German
Есть ли простой способ добиться этого?
2 ответа
Быстрый ответ:
Начиная с iOS 11+, вы можете достичь этого с помощью NSLinguisticTagger. Реализация желаемой функции следующим образом:
func detectedLangauge<T: StringProtocol>(_ forString: T) -> String? {
guard let languageCode = NSLinguisticTagger.dominantLanguage(for: String(forString)) else {
return nil
}
let detectedLangauge = Locale.current.localizedString(forIdentifier: languageCode)
return detectedLangauge
}
должен достичь того, что вы просите.
Описанный ответ:
Прежде всего, вы должны знать, о чем вы спрашиваете, в основном это относится к миру обработки естественного языка (NLP).
Поскольку НЛП - это больше, чем просто определение языка текста, остальная часть ответа не будет содержать конкретной информации НЛП.
Очевидно, что реализовать такую функциональность не так просто, особенно когда начинаешь заботиться о деталях процесса, таких как разбиение на предложения и даже на слова, после этого распознавание имен и знаков препинания и т. Д. болезненный процесс! даже самому не логично это делать "; К счастью, iOS поддерживает NLP (фактически API-интерфейсы NLP доступны для всех платформ Apple, не только для iOS), чтобы сделать то, к чему вы стремитесь, простым в реализации. Основной компонент, с которым вы будете работать, NSLinguisticTagger:
Анализируйте текст на естественном языке, чтобы пометить часть речи и лексический класс, определить имена, выполнить лемматизацию и определить язык и сценарий.
NSLinguisticTaggerобеспечивает единый интерфейс для различных функций обработки естественного языка с поддержкой множества различных языков и сценариев. Вы можете использовать этот класс для сегментирования текста на естественном языке на абзацы, предложения или слова и помечать информацию об этих сегментах, такую как часть речи, лексический класс, лемма, сценарий и язык.
Как упомянуто в документации класса, метод, который вы ищете - в разделе " Определение доминирующего языка и орфографии" - dominantLanguage(for:):
Возвращает доминирующий язык для указанной строки.
,
,
Возвращаемое значение
Тег BCP-47, идентифицирующий доминирующий язык строки, или тег "und", если конкретный язык не может быть определен.
Вы можете заметить, что NSLinguisticTagger существует еще с iOS 5. Однако dominantLanguage(for:) Метод поддерживается только для iOS 11 и выше, потому что он был разработан поверх Core ML Framework:
,,,
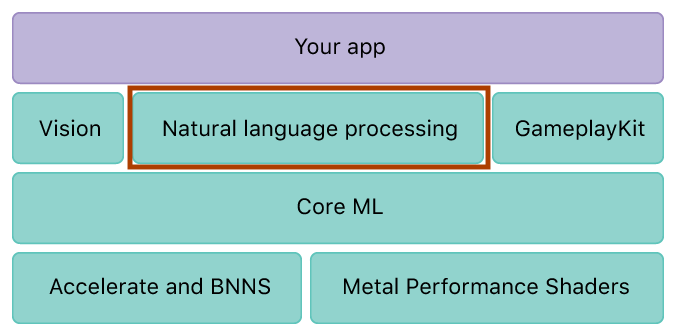
Core ML является основой для доменных структур и функциональности. Core ML поддерживает Vision для анализа изображений, Фонд для обработки естественного языка (например,
NSLinguisticTaggerкласс), и GameplayKit для оценки изученных деревьев решений. Само ядро ML построено поверх низкоуровневых примитивов, таких как Accelerate и BNNS, а также шейдеров Metal Performance.
На основе возвращенного значения от вызова dominantLanguage(for:) мимоходом "Быстрая коричневая лиса перепрыгивает через ленивую собаку":
NSLinguisticTagger.dominantLanguage(for: "The quick brown fox jumps over the lazy dog")
будет "en" необязательная строка. Однако, пока это не является желаемым результатом, ожидание должно вместо этого получить "английский"! Ну, это именно то, что вы должны получить, позвонив localizedString(forLanguageCode:) метод из Locale Structure и передача полученного языкового кода:
Locale.current.localizedString(forIdentifier: "en") // English
Собираем все вместе:
Как упомянуто во фрагменте кода "Быстрый ответ", функция будет:
func detectedLangauge<T: StringProtocol>(_ forString: T) -> String? {
guard let languageCode = NSLinguisticTagger.dominantLanguage(for: String(forString)) else {
return nil
}
let detectedLangauge = Locale.current.localizedString(forIdentifier: languageCode)
return detectedLangauge
}
Выход:
Это было бы как ожидалось:
let englishDetectedLangauge = detectedLangauge(textEN) // => English
let spanishDetectedLangauge = detectedLangauge(textES) // => Spanish
let arabicDetectedLangauge = detectedLangauge(textAR) // => Arabic
let germanDetectedLangauge = detectedLangauge(textDE) // => German
Обратите внимание, что:
Есть еще случаи, когда не получается имя языка для данной строки, например:
let textUND = "SdsOE"
let undefinedDetectedLanguage = detectedLangauge(textUND) // => Unknown language
Или это может быть даже nil:
let rabish = "000747322"
let rabishDetectedLanguage = detectedLangauge(rabish) // => nil
Все еще находите это неплохим результатом для обеспечения полезного результата...
Более того:
О NSLinguisticTagger:
Хотя я не буду углубляться в NSLinguisticTagger использование, я хотел бы отметить, что в нем есть несколько действительно интересных функций, а не просто определение языка для данного текста; В качестве довольно простого примера: использование леммы при перечислении тегов было бы очень полезно при работе с поиском информации, поскольку вы могли бы распознать слово "ведущий", передавая слово "привод".
Официальные ресурсы
Видео сессии Apple:
- Подробнее об обработке естественного языка и о том, как
NSLinguisticTaggerРаботает: Обработка естественного языка и ваши приложения.
Также для ознакомления с CoreML:
Вы можете использовать метод tagAt NSLinguisticTagger. Это поддерживает iOS 5 и позже.
func detectLanguage<T: StringProtocol>(for text: T) -> String? {
let tagger = NSLinguisticTagger.init(tagSchemes: [.language], options: 0)
tagger.string = String(text)
guard let languageCode = tagger.tag(at: 0, scheme: .language, tokenRange: nil, sentenceRange: nil) else { return nil }
return Locale.current.localizedString(forIdentifier: languageCode)
}
detectLanguage(for: "The quick brown fox jumps over the lazy dog") // English
detectLanguage(for: "El zorro marrón rápido salta sobre el perro perezoso") // Spanish
detectLanguage(for: "الثعلب البني السريع يقفز فوق الكلب الكسول") // Arabic
detectLanguage(for: "Der schnelle braune Fuchs springt über den faulen Hund") // German
Я старался NSLinguisticTagger с коротким вводом текста, как helloЭто всегда признается итальянским. К счастью, Apple недавно добавила NLLanguageRecognizer, доступный на iOS 12, и кажется, что он более точный:D
import NaturalLanguage
if #available(iOS 12.0, *) {
let languageRecognizer = NLLanguageRecognizer()
languageRecognizer.processString(text)
let code = languageRecognizer.dominantLanguage!.rawValue
let language = Locale.current.localizedString(forIdentifier: code)
}