Производительность класса StringTokenizer против метода String.split в Java
В моем программном обеспечении мне нужно разбить строку на слова. В настоящее время у меня есть более 19 000 000 документов, каждый из которых содержит более 30 слов.
Какой из следующих двух способов является лучшим способом сделать это (с точки зрения производительности)?
StringTokenizer sTokenize = new StringTokenizer(s," ");
while (sTokenize.hasMoreTokens()) {
или же
String[] splitS = s.split(" ");
for(int i =0; i < splitS.length; i++)
10 ответов
Если ваши данные уже есть в базе данных, вам нужно проанализировать строку слов, я бы предложил использовать indexOf повторно. Это во много раз быстрее, чем любое решение.
Тем не менее, получение данных из базы данных все еще, вероятно, намного дороже.
StringBuilder sb = new StringBuilder();
for (int i = 100000; i < 100000 + 60; i++)
sb.append(i).append(' ');
String sample = sb.toString();
int runs = 100000;
for (int i = 0; i < 5; i++) {
{
long start = System.nanoTime();
for (int r = 0; r < runs; r++) {
StringTokenizer st = new StringTokenizer(sample);
List<String> list = new ArrayList<String>();
while (st.hasMoreTokens())
list.add(st.nextToken());
}
long time = System.nanoTime() - start;
System.out.printf("StringTokenizer took an average of %.1f us%n", time / runs / 1000.0);
}
{
long start = System.nanoTime();
Pattern spacePattern = Pattern.compile(" ");
for (int r = 0; r < runs; r++) {
List<String> list = Arrays.asList(spacePattern.split(sample, 0));
}
long time = System.nanoTime() - start;
System.out.printf("Pattern.split took an average of %.1f us%n", time / runs / 1000.0);
}
{
long start = System.nanoTime();
for (int r = 0; r < runs; r++) {
List<String> list = new ArrayList<String>();
int pos = 0, end;
while ((end = sample.indexOf(' ', pos)) >= 0) {
list.add(sample.substring(pos, end));
pos = end + 1;
}
}
long time = System.nanoTime() - start;
System.out.printf("indexOf loop took an average of %.1f us%n", time / runs / 1000.0);
}
}
печать
StringTokenizer took an average of 5.8 us
Pattern.split took an average of 4.8 us
indexOf loop took an average of 1.8 us
StringTokenizer took an average of 4.9 us
Pattern.split took an average of 3.7 us
indexOf loop took an average of 1.7 us
StringTokenizer took an average of 5.2 us
Pattern.split took an average of 3.9 us
indexOf loop took an average of 1.8 us
StringTokenizer took an average of 5.1 us
Pattern.split took an average of 4.1 us
indexOf loop took an average of 1.6 us
StringTokenizer took an average of 5.0 us
Pattern.split took an average of 3.8 us
indexOf loop took an average of 1.6 us
Стоимость открытия файла составит около 8 мс. Поскольку файлы настолько малы, ваш кэш может повысить производительность в 2-5 раз. Тем не менее, его открытие займет около 10 часов. Стоимость использования split против StringTokenizer намного меньше, чем 0,01 мс каждый. Для анализа 19 миллионов x 30 слов * 8 букв на слово должно занять около 10 секунд (примерно 1 ГБ за 2 секунды)
Если вы хотите улучшить производительность, я предлагаю вам иметь гораздо меньше файлов. например, использовать базу данных. Если вы не хотите использовать базу данных SQL, я предлагаю использовать один из этих http://nosql-database.org/
Split в Java 7 просто вызывает indexOf для этого ввода, см. Источник. Разделение должно быть очень быстрым, близким к повторным вызовам indexOf.
Спецификация Java API рекомендует использовать split, Смотрите документациюStringTokenizer,
Насколько я заметил, еще одна важная вещь, недокументированная, заключается в том, что запрос StringTokenizer вернуть разделители вместе со строкой токена (с помощью конструктора StringTokenizer(String str, String delim, boolean returnDelims)) также сокращает время обработки. Итак, если вы ищете производительность, я бы порекомендовал использовать что-то вроде:
private static final String DELIM = "#";
public void splitIt(String input) {
StringTokenizer st = new StringTokenizer(input, DELIM, true);
while (st.hasMoreTokens()) {
String next = getNext(st);
System.out.println(next);
}
}
private String getNext(StringTokenizer st){
String value = st.nextToken();
if (DELIM.equals(value))
value = null;
else if (st.hasMoreTokens())
st.nextToken();
return value;
}
Несмотря на накладные расходы, вызванные методом getNext(), который отбрасывает разделители для вас, он все еще на 50% быстрее согласно моим оценкам.
Используйте сплит.
StringTokenizer - это устаревший класс, который сохраняется по соображениям совместимости, хотя его использование не рекомендуется в новом коде. Рекомендуется всем, кто ищет эту функцию, использовать метод split.
Что должны делать там 19 000 000 документов? Нужно ли разделять слова во всех документах на регулярной основе? Или это проблема с одним выстрелом?
Если вы отображаете / запрашиваете один документ за раз, содержащий всего 30 слов, это настолько крошечная проблема, что любой метод будет работать.
Если вам нужно обрабатывать все документы за раз, используя всего 30 слов, это настолько крошечная проблема, что вы все равно с большей вероятностью будете связаны с IO.
Во время выполнения микро (и в данном случае даже нано) тестов многое влияет на ваши результаты. JIT-оптимизация и сборка мусора - это лишь некоторые из них.
Чтобы получить значимые результаты из микро-тестов, посмотрите библиотеку jmh. В нем содержатся отличные примеры того, как проводить хорошие тесты.
Независимо от его статуса наследства, я бы ожидал StringTokenizer быть значительно быстрее, чем String.split() для этой задачи, потому что он не использует регулярные выражения: он просто сканирует ввод непосредственно, как вы сами через indexOf(), по факту String.split() приходится компилировать регулярное выражение каждый раз, когда вы его вызываете, так что это даже не так эффективно, как непосредственное использование регулярного выражения.
Мудрый по производительности StringTokeniser намного лучше, чем сплит. Проверьте код ниже,
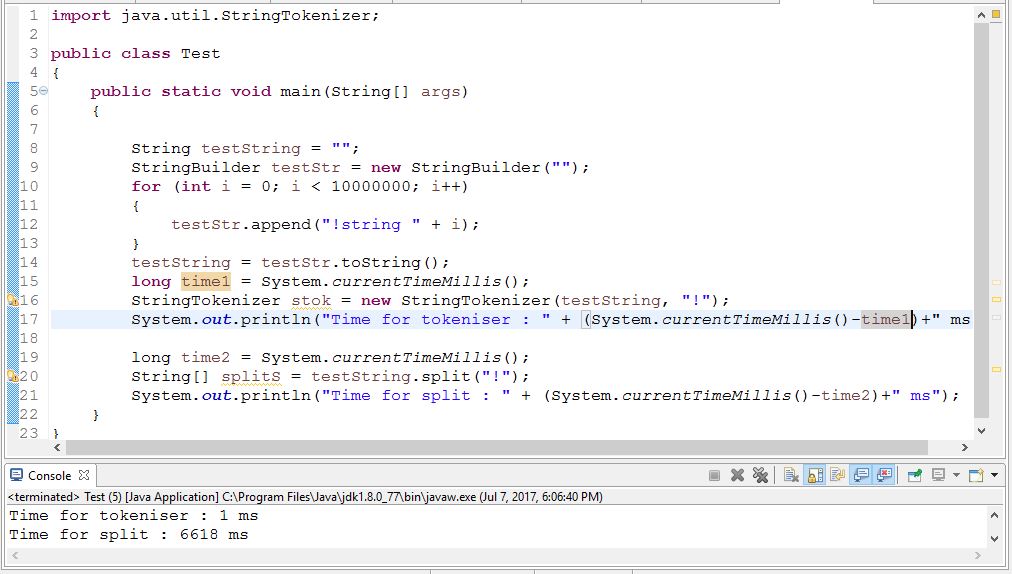
Но согласно Java документам его использование не рекомендуется. Проверьте здесь
Это может быть разумным сравнительным тестированием с использованием 1.6.0
http://www.javamex.com/tutorials/regular_expressions/splitting_tokenisation_performance.shtml#.V6-CZvnhCM8