В Sublime Text, как найти и заменить все некодированные веб-адреса отформатированными и связанными URL-адресами?
Как найти и заменить все некодированные веб-адреса отформатированными и связанными URL-адресами?
Фиктивный текст в приведенном ниже примере может представлять абзацы различной длины.
Пример:
`ДО:
Dummy text. website.dk/info
Dummy text (website.com) Dummy text.
Dummy text. website.dk
Dummy text. www.website.com
ПОСЛЕ:
Dummy text. <em><a href="http://website.dk/info" target="blank">website.dk/info</a></em>
Dummy text (<em><a href="http://website.com" target="blank">website.com</a></em>) dummy text.
Dummy text. <em><a href="http://website.dk" target="blank">website.dk</a></em>
Dummy text. <em><a href="http://website.com" target="blank">www.website.com</a></em>`
2 ответа
Предполагая, что "до" это только список URL-адресов:
- Найти> Заменить...
- Нажмите
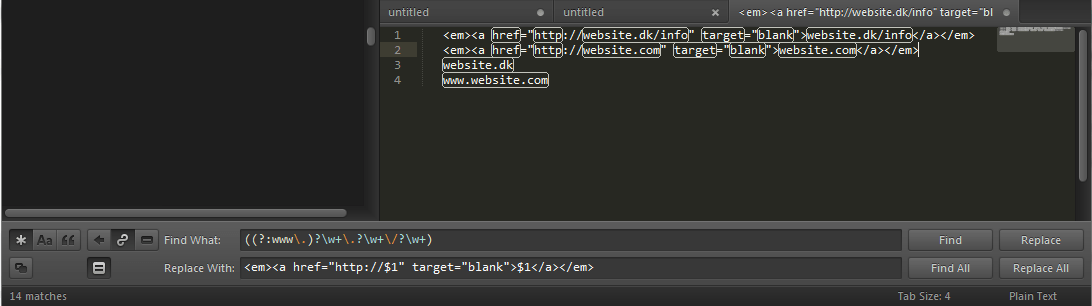
.*включить регулярное выражение - Войти
(.+)в "Найти что" - Войти
<em><a href="http://\1" target="blank">\1</a></em>в "Заменить на" - Нажмите "Заменить все"
Если "до" не все URL, "Найти что" будет сложнее.
Согласно комментариям, здесь есть (хакерский) подход Python.
file.html
<html>
<body>
<p>
Dummy text. website.dk/info
Dummy text (website.com) Dummy text.
Dummy text. website.dk
Dummy text. www.website.com
</p>
<p>
Dummy text. <em><a href="http://website.dk/info" target="blank">website.dk/info</a></em>
Dummy text (<em><a href="http://website.com" target="blank">website.com</a></em>) dummy text.
Dummy text. <em><a href="http://website.dk" target="blank">website.dk</a></em>
Dummy text. <em><a href="http://website.com" target="blank">www.website.com</a></em>
</p>
</body>
</html>
link_links.py
import re;
def link_links(m):
# Link all links.
return re.sub(
# Experiment with this pattern; e.g., search for "URL regex".
r'(?<=\W)((?:www\.)?\w+\.\w+(?:\/\S+)*)',
'<em><a href="http://\\1" target="blank">\1</a></em>',
m.group(0)
)
with open("file.html", "r") as html:
match_non_html_re = re.compile(r'''
(?<=>) # After a closing HTML tag
[^<]+ # Match all non-HTML
(?=<) # Ensure it is followed by an opening HTML tag (since we cannot use atomic grouping)
(?!<\/a>) # Ensure we were not within a link tag already
''', re.VERBOSE)
print re.sub(match_non_html_re, link_links, html.read())
Предполагая, что у вас есть больше текста, который не является ссылками, вы можете использовать регулярное выражение, например:
((?:www\.)?\w+\.?\w+\/?\w+)
С этой строкой замены
<em><a href="http://$1" target="blank">$1</a></em>