Как отобразить коэффициенты в научной записи с Stargazer
Я хочу сравнить результаты различных моделей (lm, glm, plm, pglm) в таблице в R, используя stargazer или аналогичный инструмент. Однако я не могу найти способ отобразить коэффициенты в научной записи. Это своего рода проблема, потому что перехват довольно большой (около миллиона), в то время как другие коэффициенты малы (около е-7), что приводит к множеству бесполезных нулей, затрудняющих чтение таблицы.
Я нашел похожий вопрос здесь: отформатируйте отображение модели в texreg или stargazer R как научное. Но результаты там требуют перемасштабирования переменных, и поскольку я использую данные подсчета, я бы не хотел их перемасштабировать.
Я благодарен за любые предложения.
1 ответ
Вот воспроизводимый пример:
m1 <- lm(Sepal.Length ~ Petal.Length*Sepal.Width,
transform(iris, Sepal.Length = Sepal.Length+1e6,
Petal.Length=Petal.Length*10, Sepal.Width=Sepal.Width*100))
# Coefficients:
# (Intercept) Petal.Length Sepal.Width Petal.Length:Sepal.Width
# 1.000e+06 7.185e-02 8.500e-03 -7.701e-05
Я не верю stargazer имеет легкую поддержку для этого. Вы можете попробовать другие альтернативы, такие как xtable или любой из многих вариантов здесь (я не пробовал их все)
library(xtable)
xtable(m1, display=rep('g', 5)) # or there's `digits` too; see `?xtable`
Или если вы используете knitr или же pandoc Мне очень нравится pander, которая уже имеет автоматическое научное обозначение (примечание: это вывод pandoc, который выглядит как уценка, а не вывод tex, а затем вы вяжете или pandoc в latex/pdf):
library(pander)
pander(m1)
Еще один надежный способ получить научную нотацию с помощью звездочета - это взломать digit.separatorпараметр. Эта опция позволяет пользователю указать символ, разделяющий десятичные дроби (обычно точка.в большинстве регионов). Мы можем использовать этот параметр, чтобы вставить однозначно идентифицируемую строку в любое число, которое мы хотим найти с помощью регулярного выражения. Преимущество поиска чисел таким способом заключается в том, что мы найдем только числа, соответствующие числовым значениям в выводе stargazer. Т.е. нет возможности также сопоставить числа, которые являются частью имен переменных (например, X_12345) или которые являются частью кода форматирования латекса (например,\hline \\[-1.8ex]). Далее я использую строку::::, но подойдет любая уникальная символьная строка (например, хеш), которую мы не найдем в другом месте таблицы. Вероятно, лучше избегать использования каких-либо специальных символов регулярного выражения в метке идентификатора, поскольку это немного усложнит ситуацию.
На примере модели m1из этого другого ответа.
mark = '::::'
star = stargazer(m1, header = F, decimal.mark = mark, digit.separator = '')
replace_numbers = function(x, low=0.01, high=1e3, digits = 3, scipen=-7, ...) {
x = gsub(mark,'.',x)
x.num = as.numeric(x)
ifelse(
(x.num >= low) & (x.num < high),
round(x.num, digits = digits),
prettyNum(x.num, digits=digits, scientific = scipen, ...)
)
}
reg = paste0("([0-9.\\-]+", mark, "[0-9.\\-]+)")
cat(gsubfn(reg, ~replace_numbers(x), star), sep='\n')
Обновить
Если вы хотите, чтобы конечные нули сохранялись в экспоненциальном представлении, мы можем использоватьsprintf вместо prettyNum.
Нравится
replace_numbers = function(x, low=0.01, high=1e3, digits = 3) {
x = gsub(mark,'.',x)
x.num = as.numeric(x)
form = paste0('%.', digits, 'e')
ifelse(
(abs(x.num) >= low) & (abs(x.num) < high),
round(x.num, digits = digits),
sprintf(form, x.num)
)
}

Вероятно, стоит обратиться к сопровождающему пакета с просьбой о включении этой опции.
Тем временем вы можете автоматически заменить числа в выводе научным представлением. При замене номеров следует соблюдать осторожность. Важно не переформатировать числа, которые являются частью латексного кодирования. Также будьте осторожны, чтобы не заменять символы, которые являются частью имен переменных. Например,. в Sepal.Widthможно легко принять за число с помощью регулярного выражения. Следующий код предназначен для наиболее распространенных ситуаций. Но, если кто-то, например, называет свою переменнуюX_123456789 он может переименовать это в X_1.23e+09в зависимости от настройки scipen. Таким образом, необходима некоторая осторожность, и, вероятно, потребуется реализовать более надежное решение в пакете stargazer.
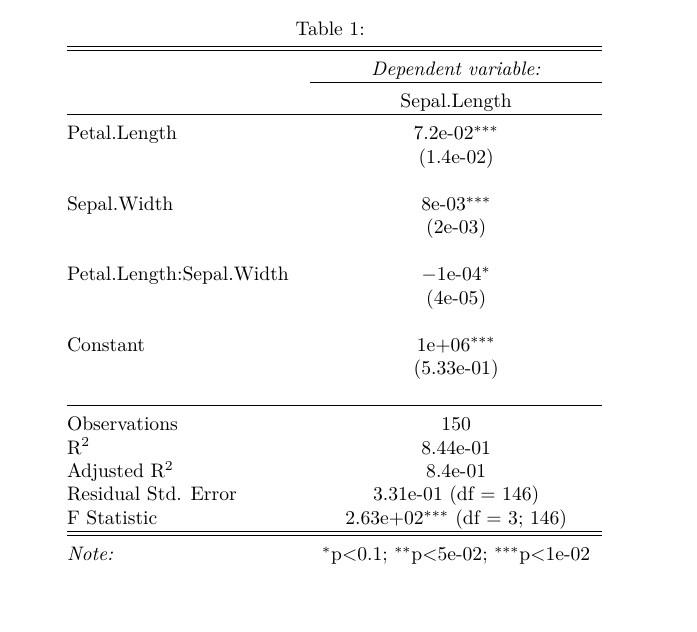
вот примерная таблица звездочета для демонстрации (бесстыдно скопирована из @ Mathematical.coffee):
library(stargazer)
library(gsubfn)
m1 <- lm(Sepal.Length ~ Petal.Length*Sepal.Width,
transform(iris, Sepal.Length = Sepal.Length+1e6,
Petal.Length=Petal.Length*10, Sepal.Width=Sepal.Width*100))
star = stargazer(m1, header = F, digit.separator = '')
Теперь вспомогательная функция для переформатирования чисел. Вы можете поиграть с параметрами digits и scipen для управления форматом вывода. Если вы хотите использовать научный формат чаще, используйте меньший (более негативный) scipen. В противном случае мы можем сделать так, чтобы он автоматически использовал научный формат только для очень маленьких или больших чисел, используя более крупныйscipen. Вcutoff Параметр предназначен для предотвращения переформатирования чисел, представленных всего несколькими символами.
replace_numbers = function(x, cutoff=4, digits=3, scipen=-7) {
ifelse(nchar(x) < cutoff, x, prettyNum(as.numeric(x), digits=digits, scientific=scipen))
}
И примените это к выводу звездочета, используя gsubfn::gsubfn
gsubfn("([0-9.]+)", ~replace_numbers(x), star)