SQL Server динамический запрос PIVOT?
Мне было поручено придумать способ перевода следующих данных:
date category amount
1/1/2012 ABC 1000.00
2/1/2012 DEF 500.00
2/1/2012 GHI 800.00
2/10/2012 DEF 700.00
3/1/2012 ABC 1100.00
в следующее:
date ABC DEF GHI
1/1/2012 1000.00
2/1/2012 500.00
2/1/2012 800.00
2/10/2012 700.00
3/1/2012 1100.00
Пустые места могут быть NULL или пробелами, либо в порядке, и категории должны быть динамическими. Еще одно возможное предупреждение: мы будем выполнять запрос с ограниченными возможностями, что означает, что временные таблицы отсутствуют. Я пытался исследовать и приземлился на PIVOT но поскольку я никогда не использовал это прежде, я действительно не понимаю этого, несмотря на все мои усилия, чтобы понять это. Может кто-то указать мне верное направление?
10 ответов
Динамический SQL PIVOT:
create table temp
(
date datetime,
category varchar(3),
amount money
)
insert into temp values ('1/1/2012', 'ABC', 1000.00)
insert into temp values ('2/1/2012', 'DEF', 500.00)
insert into temp values ('2/1/2012', 'GHI', 800.00)
insert into temp values ('2/10/2012', 'DEF', 700.00)
insert into temp values ('3/1/2012', 'ABC', 1100.00)
DECLARE @cols AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX);
SET @cols = STUFF((SELECT distinct ',' + QUOTENAME(c.category)
FROM temp c
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')
set @query = 'SELECT date, ' + @cols + ' from
(
select date
, amount
, category
from temp
) x
pivot
(
max(amount)
for category in (' + @cols + ')
) p '
execute(@query)
drop table temp
Результаты:
Date ABC DEF GHI
2012-01-01 00:00:00.000 1000.00 NULL NULL
2012-02-01 00:00:00.000 NULL 500.00 800.00
2012-02-10 00:00:00.000 NULL 700.00 NULL
2012-03-01 00:00:00.000 1100.00 NULL NULL
Динамический SQL PIVOT
Другой подход к созданию строки столбцов
create table #temp
(
date datetime,
category varchar(3),
amount money
)
insert into #temp values ('1/1/2012', 'ABC', 1000.00)
insert into #temp values ('2/1/2012', 'DEF', 500.00)
insert into #temp values ('2/1/2012', 'GHI', 800.00)
insert into #temp values ('2/10/2012', 'DEF', 700.00)
insert into #temp values ('3/1/2012', 'ABC', 1100.00)
DECLARE @cols AS NVARCHAR(MAX)='';
DECLARE @query AS NVARCHAR(MAX)='';
SELECT @cols = @cols + QUOTENAME(category) + ',' FROM (select distinct category from #temp ) as tmp
select @cols = substring(@cols, 0, len(@cols)) --trim "," at end
set @query =
'SELECT * from
(
select date, amount, category from #temp
) src
pivot
(
max(amount) for category in (' + @cols + ')
) piv'
execute(@query)
drop table #temp
Результат
date ABC DEF GHI
2012-01-01 00:00:00.000 1000.00 NULL NULL
2012-02-01 00:00:00.000 NULL 500.00 800.00
2012-02-10 00:00:00.000 NULL 700.00 NULL
2012-03-01 00:00:00.000 1100.00 NULL NULL
Я знаю, что этот вопрос старше, но я искал ответы и думал, что смогу раскрыть "динамическую" часть проблемы и, возможно, кому-нибудь помочь.
Прежде всего, я построил это решение для решения проблемы, возникшей у пары коллег с непостоянными и большими наборами данных, которые необходимо быстро поворачивать.
Это решение требует создания хранимой процедуры, поэтому, если об этом не может быть и речи, перестаньте читать сейчас.
Эта процедура будет использовать ключевые переменные оператора сводки для динамического создания операторов сводки для переменных таблиц, имен столбцов и агрегатов. Столбец Static используется в качестве столбца group by / identity для сводной таблицы (это может быть удалено из кода, если в этом нет необходимости, но он довольно распространен в операторах сводной таблицы и был необходим для решения исходной проблемы), в столбце сводной таблицы расположен конечные результирующие имена столбцов будут сгенерированы, а столбец значений - это то, к чему будет применяться агрегат. Параметр Table - это имя таблицы, включая схему (schema.tablename), которую эта часть кода может использовать с любовью, потому что она не так чиста, как хотелось бы. Это работало для меня, потому что мое использование не было публично, и инъекция sql не была проблемой. Параметр Aggregate будет принимать любой стандартный SQL-агрегат "AVG", "SUM", "MAX" и т. Д. Код по умолчанию также имеет значение MAX, так как агрегат не требуется, но аудитория, для которой он был изначально создан, не понимала сводки и обычно была используя Макс в качестве совокупности.
Давайте начнем с кода для создания хранимой процедуры. Этот код должен работать во всех версиях SSMS 2005 и выше, но я не проверял его в 2005 или 2016 году, но не могу понять, почему он не будет работать.
create PROCEDURE [dbo].[USP_DYNAMIC_PIVOT]
(
@STATIC_COLUMN VARCHAR(255),
@PIVOT_COLUMN VARCHAR(255),
@VALUE_COLUMN VARCHAR(255),
@TABLE VARCHAR(255),
@AGGREGATE VARCHAR(20) = null
)
AS
BEGIN
SET NOCOUNT ON;
declare @AVAIABLE_TO_PIVOT NVARCHAR(MAX),
@SQLSTRING NVARCHAR(MAX),
@PIVOT_SQL_STRING NVARCHAR(MAX),
@TEMPVARCOLUMNS NVARCHAR(MAX),
@TABLESQL NVARCHAR(MAX)
if isnull(@AGGREGATE,'') = ''
begin
SET @AGGREGATE = 'MAX'
end
SET @PIVOT_SQL_STRING = 'SELECT top 1 STUFF((SELECT distinct '', '' + CAST(''[''+CONVERT(VARCHAR,'+ @PIVOT_COLUMN+')+'']'' AS VARCHAR(50)) [text()]
FROM '+@TABLE+'
WHERE ISNULL('+@PIVOT_COLUMN+','''') <> ''''
FOR XML PATH(''''), TYPE)
.value(''.'',''NVARCHAR(MAX)''),1,2,'' '') as PIVOT_VALUES
from '+@TABLE+' ma
ORDER BY ' + @PIVOT_COLUMN + ''
declare @TAB AS TABLE(COL NVARCHAR(MAX) )
INSERT INTO @TAB EXEC SP_EXECUTESQL @PIVOT_SQL_STRING, @AVAIABLE_TO_PIVOT
SET @AVAIABLE_TO_PIVOT = (SELECT * FROM @TAB)
SET @TEMPVARCOLUMNS = (SELECT replace(@AVAIABLE_TO_PIVOT,',',' nvarchar(255) null,') + ' nvarchar(255) null')
SET @SQLSTRING = 'DECLARE @RETURN_TABLE TABLE ('+@STATIC_COLUMN+' NVARCHAR(255) NULL,'+@TEMPVARCOLUMNS+')
INSERT INTO @RETURN_TABLE('+@STATIC_COLUMN+','+@AVAIABLE_TO_PIVOT+')
select * from (
SELECT ' + @STATIC_COLUMN + ' , ' + @PIVOT_COLUMN + ', ' + @VALUE_COLUMN + ' FROM '+@TABLE+' ) a
PIVOT
(
'+@AGGREGATE+'('+@VALUE_COLUMN+')
FOR '+@PIVOT_COLUMN+' IN ('+@AVAIABLE_TO_PIVOT+')
) piv
SELECT * FROM @RETURN_TABLE'
EXEC SP_EXECUTESQL @SQLSTRING
END
Далее мы подготовим наши данные для примера. Я взял пример данных из принятого ответа с добавлением пары элементов данных для использования в этом доказательстве концепции, чтобы показать различные результаты совокупного изменения.
create table temp
(
date datetime,
category varchar(3),
amount money
)
insert into temp values ('1/1/2012', 'ABC', 1000.00)
insert into temp values ('1/1/2012', 'ABC', 2000.00) -- added
insert into temp values ('2/1/2012', 'DEF', 500.00)
insert into temp values ('2/1/2012', 'DEF', 1500.00) -- added
insert into temp values ('2/1/2012', 'GHI', 800.00)
insert into temp values ('2/10/2012', 'DEF', 700.00)
insert into temp values ('2/10/2012', 'DEF', 800.00) -- addded
insert into temp values ('3/1/2012', 'ABC', 1100.00)
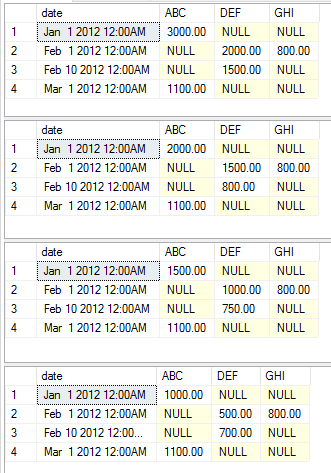
В следующих примерах показаны различные операторы выполнения, показывающие различные агрегаты в качестве простого примера. Я не решил менять столбцы static, pivot и value, чтобы сделать пример простым. Вы должны быть в состоянии просто скопировать и вставить код, чтобы начать возиться с ним самостоятельно
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','sum'
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','max'
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','avg'
exec [dbo].[USP_DYNAMIC_PIVOT] 'date','category','amount','dbo.temp','min'
Это выполнение возвращает следующие наборы данных соответственно.
Обновленная версия для SQL Server 2017, использующая функцию STRING_AGG для построения списка сводных столбцов:
create table temp
(
date datetime,
category varchar(3),
amount money
);
insert into temp values ('20120101', 'ABC', 1000.00);
insert into temp values ('20120201', 'DEF', 500.00);
insert into temp values ('20120201', 'GHI', 800.00);
insert into temp values ('20120210', 'DEF', 700.00);
insert into temp values ('20120301', 'ABC', 1100.00);
DECLARE @cols AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX);
SET @cols = (SELECT STRING_AGG(category,',') FROM (SELECT DISTINCT category FROM temp WHERE category IS NOT NULL)t);
set @query = 'SELECT date, ' + @cols + ' from
(
select date
, amount
, category
from temp
) x
pivot
(
max(amount)
for category in (' + @cols + ')
) p ';
execute(@query);
drop table temp;
Вы можете добиться этого, используя динамический TSQL (не забудьте использовать QUOTENAME, чтобы избежать атак с использованием SQL-инъекций):
Сводки с динамическими столбцами в SQL Server 2005
SQL Server - динамическая таблица PIVOT - инъекция SQL
Обязательная ссылка на Проклятие и благословения динамического SQL
Вот мое решение, очищающее ненужные нулевые значения
DECLARE @cols AS NVARCHAR(MAX),
@maxcols AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX)
select @cols = STUFF((SELECT ',' + QUOTENAME(CodigoFormaPago)
from PO_FormasPago
order by CodigoFormaPago
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')
select @maxcols = STUFF((SELECT ',MAX(' + QUOTENAME(CodigoFormaPago) + ') as ' + QUOTENAME(CodigoFormaPago)
from PO_FormasPago
order by CodigoFormaPago
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')
set @query = 'SELECT CodigoProducto, DenominacionProducto, ' + @maxcols + '
FROM
(
SELECT
CodigoProducto, DenominacionProducto,
' + @cols + ' from
(
SELECT
p.CodigoProducto as CodigoProducto,
p.DenominacionProducto as DenominacionProducto,
fpp.CantidadCuotas as CantidadCuotas,
fpp.IdFormaPago as IdFormaPago,
fp.CodigoFormaPago as CodigoFormaPago
FROM
PR_Producto p
LEFT JOIN PR_FormasPagoProducto fpp
ON fpp.IdProducto = p.IdProducto
LEFT JOIN PO_FormasPago fp
ON fpp.IdFormaPago = fp.IdFormaPago
) xp
pivot
(
MAX(CantidadCuotas)
for CodigoFormaPago in (' + @cols + ')
) p
) xx
GROUP BY CodigoProducto, DenominacionProducto'
t @query;
execute(@query);
Приведенный ниже код предоставляет результаты, которые заменяют NULL на ноль в выходных данных.
Создание таблицы и вставка данных:
create table test_table
(
date nvarchar(10),
category char(3),
amount money
)
insert into test_table values ('1/1/2012','ABC',1000.00)
insert into test_table values ('2/1/2012','DEF',500.00)
insert into test_table values ('2/1/2012','GHI',800.00)
insert into test_table values ('2/10/2012','DEF',700.00)
insert into test_table values ('3/1/2012','ABC',1100.00)
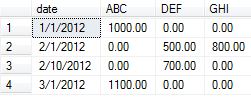
Запрос для получения точных результатов, который также заменяет NULL нулями:
DECLARE @DynamicPivotQuery AS NVARCHAR(MAX),
@PivotColumnNames AS NVARCHAR(MAX),
@PivotSelectColumnNames AS NVARCHAR(MAX)
--Get distinct values of the PIVOT Column
SELECT @PivotColumnNames= ISNULL(@PivotColumnNames + ',','')
+ QUOTENAME(category)
FROM (SELECT DISTINCT category FROM test_table) AS cat
--Get distinct values of the PIVOT Column with isnull
SELECT @PivotSelectColumnNames
= ISNULL(@PivotSelectColumnNames + ',','')
+ 'ISNULL(' + QUOTENAME(category) + ', 0) AS '
+ QUOTENAME(category)
FROM (SELECT DISTINCT category FROM test_table) AS cat
--Prepare the PIVOT query using the dynamic
SET @DynamicPivotQuery =
N'SELECT date, ' + @PivotSelectColumnNames + '
FROM test_table
pivot(sum(amount) for category in (' + @PivotColumnNames + ')) as pvt';
--Execute the Dynamic Pivot Query
EXEC sp_executesql @DynamicPivotQuery
ВЫХОД:
Версия ответа Тарин с улучшениями производительности:
Данные
CREATE TABLE dbo.Temp
(
[date] datetime NOT NULL,
category nchar(3) NOT NULL,
amount money NOT NULL,
INDEX [CX dbo.Temp date] CLUSTERED ([date]),
INDEX [IX dbo.Temp category] NONCLUSTERED (category)
);
INSERT dbo.Temp
([date], category, amount)
VALUES
({D '2012-01-01'}, N'ABC', $1000.00),
({D '2012-01-02'}, N'DEF', $500.00),
({D '2012-01-02'}, N'GHI', $800.00),
({D '2012-02-10'}, N'DEF', $700.00),
({D '2012-03-01'}, N'ABC', $1100.00);
Динамический поворот
DECLARE
@Delimiter nvarchar(4000) = N',',
@DelimiterLength bigint,
@Columns nvarchar(max),
@Query nvarchar(max);
SET @DelimiterLength = LEN(REPLACE(@Delimiter, SPACE(1), N'#'));
-- Before SQL Server 2017
SET @Columns =
STUFF
(
(
SELECT
[text()] = @Delimiter,
[text()] = QUOTENAME(T.category)
FROM dbo.Temp AS T
WHERE T.category IS NOT NULL
GROUP BY T.category
ORDER BY T.category
FOR XML PATH (''), TYPE
)
.value(N'text()[1]', N'nvarchar(max)'),
1, @DelimiterLength, SPACE(0)
);
-- Alternative for SQL Server 2017+ and database compatibility level 110+
SELECT @Columns =
STRING_AGG(CONVERT(nvarchar(max), QUOTENAME(T.category)), N',')
WITHIN GROUP (ORDER BY T.category)
FROM
(
SELECT T2.category
FROM dbo.Temp AS T2
WHERE T2.category IS NOT NULL
GROUP BY T2.category
) AS T;
IF @Columns IS NOT NULL
BEGIN
SET @Query =
N'SELECT [date], ' +
@Columns +
N'
FROM
(
SELECT [date], amount, category
FROM dbo.Temp
) AS S
PIVOT
(
MAX(amount)
FOR category IN (' +
@Columns +
N')
) AS P;';
EXECUTE sys.sp_executesql @Query;
END;
Планы выполнения
Полученные результаты
Полностью общий способ, который будет работать в нетрадиционных средах MS SQL (например, бессерверные SQL-пулы Azure Synapse Analytics) — он находится в SPROC, но его не нужно использовать как таковой...
-- DROP PROCEDURE IF EXISTS
if object_id('dbo.usp_generic_pivot') is not null
DROP PROCEDURE dbo.usp_generic_pivot
GO;
CREATE PROCEDURE dbo.usp_generic_pivot (
@source NVARCHAR (100), -- table or view object name
@pivotCol NVARCHAR (100), -- the column to pivot
@pivotAggCol NVARCHAR (100), -- the column with the values for the pivot
@pivotAggFunc NVARCHAR (20), -- the aggregate function to apply to those values
@leadCols NVARCHAR (100) -- comma seprated list of other columns to keep and order by
)
AS
BEGIN
DECLARE @pivotedColumns NVARCHAR(MAX)
DECLARE @tsql NVARCHAR(MAX)
SET @tsql = CONCAT('SELECT @pivotedColumns = STRING_AGG(qname, '','') FROM (SELECT DISTINCT QUOTENAME(', @pivotCol,') AS qname FROM ',@source, ') AS qnames')
EXEC sp_executesql @tsql, N'@pivotedColumns nvarchar(max) out', @pivotedColumns out
SET @tsql = CONCAT ( 'SELECT ', @leadCols, ',', @pivotedColumns,' FROM ',' ( SELECT ',@leadCols,',',
@pivotAggCol,',', @pivotCol, ' FROM ', @source, ') as t ',
' PIVOT (', @pivotAggFunc, '(', @pivotAggCol, ')',' FOR ', @pivotCol,
' IN (', @pivotedColumns,')) as pvt ',' ORDER BY ', @leadCols)
EXEC (@tsql)
END
GO;
-- TEST EXAMPLE
EXEC dbo.usp_generic_pivot
@source = '[your_db].[dbo].[form_answers]',
@pivotCol = 'question',
@pivotAggCol = 'answer',
@pivotAggFunc = 'MAX',
@leadCols = 'candidate_id, candidate_name'
GO;
CREATE TABLE #PivotExample(
[ID] [nvarchar](50) NULL,
[Description] [nvarchar](50) NULL,
[ClientId] [smallint] NOT NULL,
)
GO
INSERT #PivotExample ([ID],[Description], [ClientId]) VALUES ('ACI1','ACI1Desc1',1008)
INSERT #PivotExample ([ID],[Description], [ClientId]) VALUES ('ACI1','ACI1Desc2',2000)
INSERT #PivotExample ([ID],[Description], [ClientId]) VALUES ('ACI1','ACI1Desc3',3000)
INSERT #PivotExample ([ID],[Description], [ClientId]) VALUES ('ACI1','ACI1Desc4',4000)
INSERT #PivotExample ([ID],[Description], [ClientId]) VALUES ('ACI2','ACI2Desc1',5000)
INSERT #PivotExample ([ID],[Description], [ClientId]) VALUES ('ACI2','ACI2Desc2',6000)
INSERT #PivotExample ([ID],[Description], [ClientId]) VALUES ('ACI2','ACI2Desc3', 7000)
SELECT * FROM #PivotExample
--Declare necessary variables
DECLARE @SQLQuery AS NVARCHAR(MAX)
DECLARE @PivotColumns AS NVARCHAR(MAX)
--Get unique values of pivot column
SELECT @PivotColumns= COALESCE(@PivotColumns + ',','') + QUOTENAME([Description])
FROM (SELECT DISTINCT [Description] FROM [dbo].#PivotExample) AS PivotExample
--SELECT @PivotColumns
--Create the dynamic query with all the values for
--pivot column at runtime
SET @SQLQuery =
N' -- Your pivoted result comes here
SELECT ID, ' + @PivotColumns + '
FROM
(
-- Source table should in a inner query
SELECT ID,[Description],[ClientId]
FROM #PivotExample
)AS P
PIVOT
(
-- Select the values from derived table P
SUM(ClientId)
FOR [Description] IN (' + @PivotColumns + ')
)AS PVTTable'
--SELECT @SQLQuery
--Execute dynamic query
EXEC sp_executesql @SQLQuery
Drop table #PivotExample