Как мне сопоставить любой символ в нескольких строках регулярного выражения?
Например, это регулярное выражение
(.*)<FooBar>
будет соответствовать:
abcde<FooBar>
Но как мне сделать так, чтобы он совпадал по нескольким строкам?
abcde
fghij<FooBar>
26 ответов
Это зависит от языка, но должен быть модификатор, который вы можете добавить к шаблону регулярных выражений. В PHP это так:
/(.*)<FooBar>/s
Символ s в конце приводит к тому, что точка соответствует всем символам, включая символы новой строки.
Попробуй это:
((.|\n)*)<FooBar>
Это в основном говорит, что "любой символ или перевод строки" повторяется ноль или более раз.
Вопрос в том, может . шаблон соответствует любому персонажу? Ответ варьируется от двигателя к двигателю. Основное различие заключается в том, используется ли шаблон библиотекой регулярных выражений POSIX или не-POSIX.
Особое примечание о шаблонах lua: они не считаются регулярными выражениями, но . соответствует любому символу там, так же как движки на основе POSIX.
Еще одно примечание о Matlab и октаве: . соответствует любому символу по умолчанию ( демо): str = "abcde\n fghij<Foobar>"; expression = '(.*)<Foobar>*'; [tokens,matches] = regexp(str,expression,'tokens','match'); (tokens содержать abcde\n fghij вещь).
Кроме того, во всех грамматиках регулярных выражений boost точка соответствует разрывам строк по умолчанию. ECMAScript грамматика Boost позволяет отключить это с regex_constants::no_mod_m ( источник).
Что касается оракула (он основан на POSIX), используйте n опция ( демо): select regexp_substr('abcde' || chr(10) ||' fghij<Foobar>', '(.*)<Foobar>', 1, 1, 'n', 1) as results from dual
Двигатели на базе POSIX:
tcl ( демо), postgresql ( демо), r (TRE, базовый R по умолчанию движок без perl=TRUE для базы R с perl=TRUE или для шаблонов stringr / stringi используйте (?s) встроенный модификатор) ( демо). Просто . уже соответствует переносу строк, нет необходимости использовать какие-либо модификаторы.
Двигатели без POSIX:
- PHP - Использование
sмодификатор PCRE_DOTALL модификатор:preg_match('~(.*)<Foobar>~s', $s, $m)( демо) - C# - Использование
RegexOptions.Singlelineфлаг ( демо):
-var result = Regex.Match(s, @"(.*)<Foobar>", RegexOptions.Singleline).Groups[1].Value;
-var result = Regex.Match(s, @"(?s)(.*)<Foobar>").Groups[1].Value; - powershell - Использование
(?s)встроенный вариант:$s = "abcde`nfghij<FooBar>"; $s -match "(?s)(.*)<Foobar>"; $matches[1] - Perl - Использование
sмодификатор (или(?s)встроенная версия в начале) ( демо):/(.*)<FooBar>/s - Python - Использование
re.DOTALL(или жеre.S) флаги или(?s)встроенный модификатор ( демо):m = re.search(r"(.*)<FooBar>", s, flags=re.S)(а потомif m:,print(m.group(1))) - Java - Использование
Pattern.DOTALLмодификатор (или встроенный(?s)флаг) ( демо):Pattern.compile("(.*)<FooBar>", Pattern.DOTALL) - groovy - Использование
(?s)модификатор in-pattern ( демо):regex = /(?s)(.*)<FooBar>/ - Скала - Использование
(?s)модификатор ( демо):"(?s)(.*)<Foobar>".r.findAllIn("abcde\n fghij<Foobar>").matchData foreach { m => println(m.group(1)) } - JavaScript - Использование
[^]или обходные пути[\d\D]/[\w\W]/[\s\S]( демо):s.match(/([\s\S]*)<FooBar>/)[1] - с ++ (
std::regex) Используйте[\s\S]или обходные пути JS ( демо):regex rex(R"(([\s\S]*)<FooBar>)"); - vba - использовать тот же подход, что и в JavaScript,
([\s\S]*)<Foobar>, - ruby - использовать
/mМодификатор MULTILINE ( демо):s[/(.*)<Foobar>/m, 1] -
 go - использовать встроенный модификатор
go - использовать встроенный модификатор (?s)в начале ( демо):re: = regexp.MustCompile(`(?s)(.*)<FooBar>`) - swift - Использование
dotMatchesLineSeparatorsили (легче) передать(?s)встроенный модификатор в шаблон:let rx = "(?s)(.*)<Foobar>" - target-c - такой же, как Swift,
(?s)работает проще всего, но вот как эта опция может быть использована:NSRegularExpression* regex = [NSRegularExpression regularExpressionWithPattern:pattern options:NSRegularExpressionDotMatchesLineSeparators error:®exError]; - re2,
 /questions/tagged/google-apps-script - использовать
/questions/tagged/google-apps-script - использовать (?s)модификатор ( демо):"(?s)(.*)<Foobar>"(в таблицах Google,=REGEXEXTRACT(A2,"(?s)(.*)<Foobar>"))
ЗАМЕЧАНИЯ ПО (?s):
В большинстве не POSIX двигателей, (?s) встроенный модификатор (или встроенный параметр флага) может быть использован для обеспечения соблюдения . чтобы соответствовать разрывам строк.
Если поместить в начале шаблона, (?s) меняет поведение всех . в шаблоне. Если (?s) находится где-то после начала, только те . будут затронуты, которые расположены справа от него, если это не шаблон, переданный в Python re, В питоне re, независимо от (?s) расположение, весь шаблон . находятся под влиянием. (?s) эффект прекращается с помощью (?-s), Модифицированная группа может использоваться, чтобы влиять только на указанный диапазон шаблона регулярных выражений (например, Delim1(?s:.*?)\nDelim2.* сделаю первый .*? матч через переводы строк и второй .* будет соответствовать только остальной части линии).
POSIX примечание:
В двигателях без регулярных выражений, чтобы соответствовать любому символу, [\s\S] / [\d\D] / [\w\W] конструкции могут быть использованы.
В POSIX, [\s\S] не соответствует ни одному символу (как в JavaScript или любом не-POSIX-движке), потому что escape-последовательности regex не поддерживаются внутри скобочных выражений. [\s\S] анализируется как выражения в скобках, которые соответствуют одному символу, \ или же s или же S,
Если вы используете поиск Eclipse, вы можете включить опцию "DOTALL", чтобы сделать '.' соответствует любому символу, включая разделители строк: просто добавьте "(?s)" в начале строки поиска. Пример:
(?s).*<FooBar>
([\s\S]*)<FooBar>
Точка соответствует всем кроме новых строк (\r\n). Поэтому используйте \s\S, который будет соответствовать ВСЕМ символам.
Мы также можем использовать
(.*?\n)*?
чтобы соответствовать всем, включая перевод строки без жадных
Это сделает новую строку необязательной
(.*?|\n)*?
В Ruby Ruby вы можете использовать m опция (многострочная):
/YOUR_REGEXP/m
См. Документацию Regexp на ruby-doc.org для получения дополнительной информации.
"." обычно не соответствует переводу строки. Большинство двигателей регулярных выражений позволяет добавлять S-флаг (также называется DOTALL а также SINGLELINE) делать "." также соответствуйте новым строкам. Если это не поможет, вы можете сделать что-то вроде [\S\s],
Для Eclipse сработало следующее выражение:
Foo
Джададжада Бар "
Регулярные выражения:
Foo[\S\s]{1,10}.*Bar*
Это работает для меня и является самым простым:
(\X*)<FooBar>
В блокноте ++ вы можете использовать это
<table (.|\r\n)*</table>
Он будет соответствовать всей таблице, начиная с
строки и столбцыВы можете сделать его жадным, используя следующее, таким образом он будет соответствовать первой, второй и так далее таблицам, а не всем сразу
<table (.|\r\n)*?</table>
Обратите внимание, что (.|\n)* может быть менее эффективным, чем (например) [\s\S]* (если регулярные выражения вашего языка поддерживают такие побеги) и чем найти, как указать модификатор, который делает. также соответствуйте новым строкам. Или вы можете пойти с POSIXy альтернативами, такими как [[:space:][:^space:]]*,
Используйте RegexOptions.Singleline, это меняет значение. включить переводы строки
Regex.Replace(content, searchText, replaceText, RegexOptions.Singleline);
/(.*)<FooBar>/s
s заставляет Dot (.) соответствовать возврату каретки
В регулярном выражении на основе Java вы можете использовать [\s\S]
В общем-то. не соответствует переводу строки, поэтому попробуйте ((.|\n)*)<foobar>
Решение:
Используйте модификатор шаблона sU, чтобы получить желаемое совпадение в PHP.
пример:
preg_match('/(.*)/sU',$content,$match);
Источник:
http://dreamluverz.com/developers-tools/regex-match-all-including-new-line http://php.net/manual/en/reference.pcre.pattern.modifiers.php
В Javascript вы можете использовать [^]* для поиска от нуля до бесконечных символов, включая разрывы строк.
$("#find_and_replace").click(function() {
var text = $("#textarea").val();
search_term = new RegExp("[^]*<Foobar>", "gi");;
replace_term = "Replacement term";
var new_text = text.replace(search_term, replace_term);
$("#textarea").val(new_text);
});<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>
<button id="find_and_replace">Find and replace</button>
<br>
<textarea ID="textarea">abcde
fghij<Foobar></textarea>Пытаться: .*\n*.*<FooBar>предполагая, что вы также разрешаете пустые символы новой строки. Поскольку вы разрешаете любому персонажу, не включая ничего до<FooBar>.
В контексте использования в языках регулярные выражения действуют на строки, а не на строки. Таким образом, вы сможете нормально использовать регулярные выражения, предполагая, что входная строка имеет несколько строк.
В этом случае данное регулярное выражение будет соответствовать всей строке, поскольку присутствует "
Основанное на строке регулярное выражение обычно используется для таких вещей, как egrep.
У меня была та же проблема, и я решил ее, вероятно, не лучшим образом, но она работает. Я заменил все разрывы строк, прежде чем я сделал свой реальный матч:
mystring= Regex.Replace(mystring, "\r\n", "")
Я манипулирую HTML, поэтому разрывы строк не имеют для меня большого значения в этом случае.
Я попробовал все предложения выше без удачи, я использую.Net 3.5 FYI
Обычно при поиске трех последовательных строк в Powershell это выглядит так:
$file = get-content file.txt -raw
$pattern = 'lineone\r\nlinetwo\r\nlinethree\r\n' # "windows" text
$pattern = 'lineone\nlinetwo\nlinethree\n' # "unix" text
$pattern = 'lineone\r?\nlinetwo\r?\nlinethree\r?\n' # both
$file -match $pattern
# output
True
Как ни странно, это будет текст unix в приглашении, но текст Windows в файле:
$pattern = 'lineone
linetwo
linethree
'
Вот способ распечатать окончания строк:
'lineone
linetwo
linethree
' -replace "`r",'\r' -replace "`n",'\n'
# output
lineone\nlinetwo\nlinethree\n
Я хотел, чтобы соответствовать конкретный, если блок в Java
...
...
if(isTrue){
doAction();
}
...
...
}
Если я использую regExp
if \(isTrue(.|\n)*}
он включал закрывающую скобку для блока метода, поэтому я использовал
if \(!isTrue([^}.]|\n)*}
чтобы исключить закрывающую скобку из совпадения с подстановочными знаками.
Часто нам нужно изменить подстроку с несколькими ключевыми словами, разбросанными по строкам, предшествующим подстроке. Рассмотрим элемент xml:
<TASK>
<UID>21</UID>
<Name>Architectural design</Name>
<PercentComplete>81</PercentComplete>
</TASK>
Предположим, что мы хотим изменить 81, на другое значение, скажем, 40. Сначала определите .UID.21..UID., затем пропустите все символы, включая \n до .PercentCompleted., Шаблон регулярного выражения и спецификация замены:
String hw = new String("<TASK>\n <UID>21</UID>\n <Name>Architectural design</Name>\n <PercentComplete>81</PercentComplete>\n</TASK>");
String pattern = new String ("(<UID>21</UID>)((.|\n)*?)(<PercentComplete>)(\\d+)(</PercentComplete>)");
String replaceSpec = new String ("$1$2$440$6");
//note that the group (<PercentComplete>) is $4 and the group ((.|\n)*?) is $2.
String iw = hw.replaceFirst(pattern, replaceSpec);
System.out.println(iw);
<TASK>
<UID>21</UID>
<Name>Architectural design</Name>
<PercentComplete>40</PercentComplete>
</TASK>
Подгруппа (.|\n) вероятно пропавшая группа $3, Если мы сделаем это без захвата (?:.|\n) тогда $3 является (<PercentComplete>), Так что картина и replaceSpec так же может быть:
pattern = new String("(<UID>21</UID>)((?:.|\n)*?)(<PercentComplete>)(\\d+)(</PercentComplete>)");
replaceSpec = new String("$1$2$340$5")
и замена работает правильно, как и раньше.
Опция 1
Один из способов - использовать s флаг (как в принятом ответе):
/(.*)<FooBar>/s
Демо 1
Вариант 2
Второй способ - использовать m (многострочный) флаг и любой из следующих шаблонов:
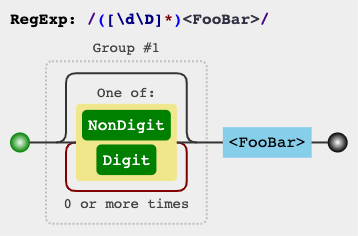
/([\s\S]*)<FooBar>/m
или
/([\d\D]*)<FooBar>/m
или
/([\w\W]*)<FooBar>/m
Демо 2
Цепь RegEx
jex.im визуализирует регулярные выражения: