UndefinedMetricWarning: F-оценка плохо определена и установлена на 0,0 в метках без прогнозируемых выборок
Я получаю эту странную ошибку classification.py:1113: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.
'precision', 'predicted', average, warn_for) но затем он также печатает f-партитуру при первом запуске metrics.f1_score(y_test, y_pred, average='weighted'), Во второй раз я запускаю счет без ошибок. Это почему?
>>> y_pred = test.predict(X_test)
>>> y_test
array([ 1, 10, 35, 9, 7, 29, 26, 3, 8, 23, 39, 11, 20, 2, 5, 23, 28,
30, 32, 18, 5, 34, 4, 25, 12, 24, 13, 21, 38, 19, 33, 33, 16, 20,
18, 27, 39, 20, 37, 17, 31, 29, 36, 7, 6, 24, 37, 22, 30, 0, 22,
11, 35, 30, 31, 14, 32, 21, 34, 38, 5, 11, 10, 6, 1, 14, 12, 36,
25, 8, 30, 3, 12, 7, 4, 10, 15, 12, 34, 25, 26, 29, 14, 37, 23,
12, 19, 19, 3, 2, 31, 30, 11, 2, 24, 19, 27, 22, 13, 6, 18, 20,
6, 34, 33, 2, 37, 17, 30, 24, 2, 36, 9, 36, 19, 33, 35, 0, 4,
1])
>>> y_pred
array([ 1, 10, 35, 7, 7, 29, 26, 3, 8, 23, 39, 11, 20, 4, 5, 23, 28,
30, 32, 18, 5, 39, 4, 25, 0, 24, 13, 21, 38, 19, 33, 33, 16, 20,
18, 27, 39, 20, 37, 17, 31, 29, 36, 7, 6, 24, 37, 22, 30, 0, 22,
11, 35, 30, 31, 14, 32, 21, 34, 38, 5, 11, 10, 6, 1, 14, 30, 36,
25, 8, 30, 3, 12, 7, 4, 10, 15, 12, 4, 22, 26, 29, 14, 37, 23,
12, 19, 19, 3, 25, 31, 30, 11, 25, 24, 19, 27, 22, 13, 6, 18, 20,
6, 39, 33, 9, 37, 17, 30, 24, 9, 36, 39, 36, 19, 33, 35, 0, 4,
1])
>>> metrics.f1_score(y_test, y_pred, average='weighted')
C:\Users\Michael\Miniconda3\envs\snowflakes\lib\site-packages\sklearn\metrics\classification.py:1113: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.
'precision', 'predicted', average, warn_for)
0.87282051282051276
>>> metrics.f1_score(y_test, y_pred, average='weighted')
0.87282051282051276
>>> metrics.f1_score(y_test, y_pred, average='weighted')
0.87282051282051276
Кроме того, почему есть трейлинг 'precision', 'predicted', average, warn_for) сообщение об ошибке? Открытой скобки нет, так почему же она заканчивается закрывающей скобкой? Я запускаю sklearn 0.18.1 с использованием Python 3.6.0 в среде conda на Windows 10.
Я также посмотрел здесь, и я не знаю, если это та же ошибка.
Это сообщение не имеет решения.
10 ответов
Как упоминалось в комментариях, некоторые ярлыки в y_true не отображаются в y_pred. В частности, в этом случае метка "2" никогда не прогнозируется:
>>> set(y_test) - set(y_pred)
{2}
Это означает, что для этой метки не рассчитывается F-оценка, и, таким образом, F-оценка для этого случая считается равной 0,0. Так как вы запросили среднее значение для оценки, вы должны принять во внимание, что оценка 0 была включена в расчет, и именно поэтому scikit-learn показывает вам это предупреждение.
Это приводит меня к тому, что вы не видите ошибку во второй раз. Как я уже упоминал, это предупреждение, которое трактуется иначе, чем ошибка в python. Поведение по умолчанию в большинстве сред - показывать конкретное предупреждение только один раз. Это поведение можно изменить:
import warnings
warnings.filterwarnings('always') # "error", "ignore", "always", "default", "module" or "once"
Если вы установите это перед импортом других модулей, вы увидите предупреждение при каждом запуске кода.
Нет способа избежать появления этого предупреждения в первый раз, кроме настройки warnings.filterwarnings('ignore'), Что вы можете сделать, это решить, что вас не интересуют оценки меток, которые не были спрогнозированы, а затем явно указать интересующие вас метки (которые являются метками, которые были спрогнозированы хотя бы один раз):
>>> metrics.f1_score(y_test, y_pred, average='weighted', labels=np.unique(y_pred))
0.91076923076923078
Предупреждение не отображается в этом случае.
Та же проблема случилась и со мной, когда я тренировал свою модель классификации. Причина, вызвавшая эту проблему, заключается в том, что в предупреждающем сообщении говорилось, что "в метках без предполагаемых выборок", это приведет к нулевому делению при вычислении f1-score. Я нашел другое решение, когда прочитал документ sklearn.metrics.f1_score, есть следующее примечание:
Когда истинно положительное + ложное положительное == 0, точность не определена; Когда истинно положительный + ложноотрицательный == 0, отзыв не определен. В таких случаях по умолчанию метрика будет установлена на 0, как и f-score, и будет увеличено UndefinedMetricWarning. Это поведение можно изменить с помощью zero_division
в zero_division значение по умолчанию "warn", вы можете установить его на 0 или 1 избегать UndefinedMetricWarning. у меня это работает;) подождите, есть еще одна проблема, когда я используюzero_division, мой отчет sklearn, что нет такого аргумента ключевого слова при использовании scikit-learn 0.21.3. Просто обновите свой sklearn до последней версии, запустивpip install scikit-learn -U
Я оказался здесь с той же ошибкой, но, прочитав ответ @Shovalt, я понял, что у меня был довольно низкий уровень в моем тестовом / поездном сплите. Для начала у меня был большой набор данных, но я разбил его на части, и одна группа оказалась довольно маленькой. Увеличив размер выборки, это предупреждение исчезло, и я получил свой результат f1. Из этого
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=0)
к этому
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
В качестве альтернативы вы можете использовать следующие строки кода
from sklearn.metrics import f1_score
metrics.f1_score(y_test, y_pred, labels=np.unique(y_pred))
Это должно удалить ваше предупреждение и дать вам результат, который вы хотели
Как я заметил, эта ошибка возникает при двух обстоятельствах:
- Если вы использовали train_test_split() для разделения данных, вы должны убедиться, что вы сбросили индекс данных (особенно, если он был взят с использованием объекта серии pandas): y_train, индексы y_test должны быть сброшены. Проблема в том, что вы пытаетесь использовать одну из оценок из sklearn.metrics, например: precision_score, это попытается сопоставить перетасованные индексы y_test, которые вы получили от train_test_split().
поэтому используйте либо np.array(y_test) для y_true в оценках, либо y_test.reset_index(drop=True)
- Опять же, у вас все еще может быть эта ошибка, если ваш прогноз "Истинные положительные результаты" равен 0, который используется для точности, отзыва и f1_scores. Вы можете визуализировать это с помощью confusion_matrix. Если классификация является многозначной и вы установили param: average='weighted'/micro/macro, вы получите ответ, если диагональная линия в матрице не равна 0
Надеюсь это поможет.
Принятый ответ уже хорошо объясняет, почему происходит предупреждение. Если вы просто хотите контролировать предупреждения, можно использовать precision_recall_fscore_support, Он предлагает (полуофициальный) аргумент warn_for это может быть использовано для отключения предупреждений.
(_, _, f1, _) = metrics.precision_recall_fscore_support(y_test, y_pred,
average='weighted',
warn_for=tuple())
Как уже упоминалось в некоторых комментариях, используйте это с осторожностью.
Я проверил, как предложил user4983290 , разницу между наборами значений истинности и предсказаний в случае с несколькими метками, но это не помогло мне решить мою проблему.
Итак, я просмотрел исходный код sklearn.metrics.precision_recall_fscore_support (который вызывается f1_score), чтобы проверить, как он работает.
Код, вызывающий предупреждение, следующий:
precision = _prf_divide(
tp_sum, pred_sum, "precision", "predicted", average, warn_for, zero_division
)
recall = _prf_divide(
tp_sum, true_sum, "recall", "true", average, warn_for, zero_division
)
-
tpsumсоответствует TP (True Positives) -
pred_sumсоответствует TP + FP (ложные срабатывания) -
true_sumсоответствует TP + FN (ложноотрицательные результаты) - первый параметр - числитель деления
- второй параметр
_prf_divideявляется знаменателем деления
Как только pred_sum или true_sum становится равным 0, выдается предупреждение, потому что деление на 0 запрещено.
Чтобы получить эти разные значения, используйте sklearn.metrics.multilabel_confusion_matrix . В результате получается трехмерный массив. Вы можете увидеть его в виде списка матриц 2x2, где каждая матрица представляет истинно отрицательные (TN), ложные положительные (FP), ложные отрицательные (FP) и истинные положительные (TP) для каждой из ваших меток, структурированные следующим образом:
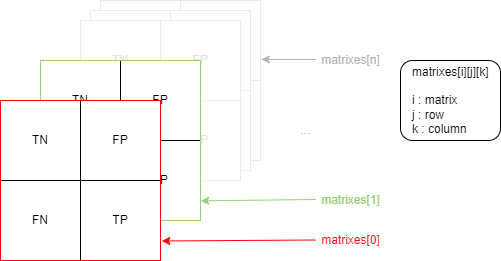
На мой взгляд, проблема должна заключаться в неспособности модели предсказывать некоторые метки из-за плохого обучения или отсутствия выборок.
Эта команда работает для меня
sklearn.metrics.f1_score(y_true, y_pred,average='weighted',zero_division=0)
Та же причина моей проблемы, но проблема в матрице путаницы. Я хочу, чтобы матрица путаницы правильно выводила истинные отрицательные и истинные положительные моменты. Я согласен с тем, что все баллы Precision, Recall и F1 равны 0 для класса 0. Предполагается, что они равны 0, поскольку для этого класса нет прогнозов. Кто-нибудь знает, как предотвратить истинные положительные и истинные отрицательные стороны матрицы путаницы от 0???
Как говорится в сообщении об ошибке, метод, используемый для получения оценки F, взят из части "Классификация" sklearn - таким образом, речь идет о "метках".
У вас есть проблема регрессии? Sklearn предоставляет метод "F Score" для регрессии в группе "Выбор объектов": http://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.f_regression.html
Если у вас есть проблема с классификацией, ответ @Shovalt мне кажется правильным.