Добавление нового столбца в существующий DataFrame в пандах Python
У меня есть следующий индексированный DataFrame с именованными столбцами и строками, не являющимися непрерывными числами:
a b c d
2 0.671399 0.101208 -0.181532 0.241273
3 0.446172 -0.243316 0.051767 1.577318
5 0.614758 0.075793 -0.451460 -0.012493
Я хотел бы добавить новый столбец, 'e', к существующему фрейму данных и не хотят ничего менять в фрейме данных (т. е. новый столбец всегда имеет ту же длину, что и фрейм данных).
0 -0.335485
1 -1.166658
2 -0.385571
dtype: float64
Я пробовал разные версии join, append, merge, но я не получил желаемый результат, только ошибки, самое большее. Как я могу добавить столбец e к приведенному выше примеру?
34 ответа
Используйте оригинальные индексы df1 для создания серии:
df1['e'] = Series(np.random.randn(sLength), index=df1.index)
Редактировать 2015
Некоторые сообщили, чтобы получить SettingWithCopyWarning с этим кодом.
Тем не менее, код по-прежнему отлично работает с текущей версией панды 0.16.1.
>>> sLength = len(df1['a'])
>>> df1
a b c d
6 -0.269221 -0.026476 0.997517 1.294385
8 0.917438 0.847941 0.034235 -0.448948
>>> df1['e'] = p.Series(np.random.randn(sLength), index=df1.index)
>>> df1
a b c d e
6 -0.269221 -0.026476 0.997517 1.294385 1.757167
8 0.917438 0.847941 0.034235 -0.448948 2.228131
>>> p.version.short_version
'0.16.1'
SettingWithCopyWarning стремится сообщить о возможном недействительном присвоении на копии Dataframe. Это не обязательно говорит о том, что вы сделали это неправильно (это может привести к ложным срабатываниям), но из 0.13.0 это дает вам понять, что для этой цели есть более адекватные методы. Затем, если вы получите предупреждение, просто следуйте его совету: попробуйте вместо этого использовать.loc[row_index,col_indexer] = value
>>> df1.loc[:,'f'] = p.Series(np.random.randn(sLength), index=df1.index)
>>> df1
a b c d e f
6 -0.269221 -0.026476 0.997517 1.294385 1.757167 -0.050927
8 0.917438 0.847941 0.034235 -0.448948 2.228131 0.006109
>>>
На самом деле, это в настоящее время более эффективный метод, как описано в pandas docs
Редактировать 2017
Как указано в комментариях и @Alexander, в настоящее время наилучшим методом добавления значений Series в качестве нового столбца DataFrame может быть использование assign:
df1 = df1.assign(e=p.Series(np.random.randn(sLength)).values)
Я хотел бы добавить новый столбец "e" в существующий фрейм данных и ничего не менять в фрейме данных. (Ряд всегда имеет ту же длину, что и кадр данных.)
Я предполагаю, что значения индекса в e сопоставить те, в df1,
Самый простой способ инициировать новый столбец с именем e и присвойте ему значения из вашей серии e:
df['e'] = e.values
назначить (Панды 0.16.0+)
Начиная с Pandas 0.16.0, вы также можете использовать assign, который назначает новые столбцы для DataFrame и возвращает новый объект (копию) со всеми исходными столбцами в дополнение к новым.
df1 = df1.assign(e=e.values)
Согласно этому примеру (который также включает в себя исходный код assign функция), вы также можете включить более одного столбца:
df = pd.DataFrame({'a': [1, 2], 'b': [3, 4]})
>>> df.assign(mean_a=df.a.mean(), mean_b=df.b.mean())
a b mean_a mean_b
0 1 3 1.5 3.5
1 2 4 1.5 3.5
В контексте с вашим примером:
np.random.seed(0)
df1 = pd.DataFrame(np.random.randn(10, 4), columns=['a', 'b', 'c', 'd'])
mask = df1.applymap(lambda x: x <-0.7)
df1 = df1[-mask.any(axis=1)]
sLength = len(df1['a'])
e = pd.Series(np.random.randn(sLength))
>>> df1
a b c d
0 1.764052 0.400157 0.978738 2.240893
2 -0.103219 0.410599 0.144044 1.454274
3 0.761038 0.121675 0.443863 0.333674
7 1.532779 1.469359 0.154947 0.378163
9 1.230291 1.202380 -0.387327 -0.302303
>>> e
0 -1.048553
1 -1.420018
2 -1.706270
3 1.950775
4 -0.509652
dtype: float64
df1 = df1.assign(e=e.values)
>>> df1
a b c d e
0 1.764052 0.400157 0.978738 2.240893 -1.048553
2 -0.103219 0.410599 0.144044 1.454274 -1.420018
3 0.761038 0.121675 0.443863 0.333674 -1.706270
7 1.532779 1.469359 0.154947 0.378163 1.950775
9 1.230291 1.202380 -0.387327 -0.302303 -0.509652
Описание этой новой функции, когда она была впервые представлена, можно найти здесь.
Супер простое назначение столбцов
Фрейм данных pandas реализован в виде упорядоченного набора столбцов.
Это означает, что __getitem__[] может быть использован не только для получения определенного столбца, но __setitem__[] = может использоваться для назначения нового столбца.
Например, к этому фрейму данных можно добавить столбец, просто используя [] сбруя
size name color
0 big rose red
1 small violet blue
2 small tulip red
3 small harebell blue
df['protected'] = ['no', 'no', 'no', 'yes']
size name color protected
0 big rose red no
1 small violet blue no
2 small tulip red no
3 small harebell blue yes
Обратите внимание, что это работает, даже если индекс датафрейма выключен.
df.index = [3,2,1,0]
df['protected'] = ['no', 'no', 'no', 'yes']
size name color protected
3 big rose red no
2 small violet blue no
1 small tulip red no
0 small harebell blue yes
[] = это путь, но будьте осторожны!
Однако, если у вас есть pd.Series и попытайтесь назначить его на фрейм данных, где индексы отключены, вы столкнетесь с проблемами. Смотрите пример:
df['protected'] = pd.Series(['no', 'no', 'no', 'yes'])
size name color protected
3 big rose red yes
2 small violet blue no
1 small tulip red no
0 small harebell blue no
Это потому что pd.Series по умолчанию имеет индекс, перечисляемый от 0 до n. И панды [] = метод пытается быть "умным"
Что на самом деле происходит.
Когда вы используете [] = Метод pandas тихо выполняет внешнее соединение или внешнее объединение, используя индекс левого кадра данных и индекс правого ряда. df['column'] = series
Примечание
Это быстро вызывает когнитивный диссонанс, так как []= Метод пытается сделать много разных вещей в зависимости от ввода, и результат не может быть предсказан, если вы просто не знаете, как работает панда. Поэтому я бы посоветовал против []= в базах кода, но при исследовании данных в блокноте это нормально.
Обойти проблему
Если у тебя есть pd.Series и хотите, чтобы он был назначен сверху вниз, или если вы кодируете производительный код, и вы не уверены в порядке индексации, стоит того, чтобы защитить его от подобных проблем.
Вы могли бы опустить pd.Series к np.ndarray или list, это сделает свое дело.
df['protected'] = pd.Series(['no', 'no', 'no', 'yes']).values
или же
df['protected'] = list(pd.Series(['no', 'no', 'no', 'yes']))
Но это не очень явно.
Может прийти какой-нибудь кодер и сказать: "Эй, это выглядит излишним, я просто оптимизирую это".
Явный способ
Установка индекса pd.Series быть индексом df явный
df['protected'] = pd.Series(['no', 'no', 'no', 'yes'], index=df.index)
Или, более реалистично, у вас, вероятно, есть pd.Series уже доступно.
protected_series = pd.Series(['no', 'no', 'no', 'yes'])
protected_series.index = df.index
3 no
2 no
1 no
0 yes
Теперь можно назначить
df['protected'] = protected_series
size name color protected
3 big rose red no
2 small violet blue no
1 small tulip red no
0 small harebell blue yes
Альтернативный способ с df.reset_index()
Поскольку диссонанс индекса является проблемой, если вы чувствуете, что индекс фрейма данных не должен диктовать что-то, вы можете просто отбросить индекс, это должно быть быстрее, но это не очень чисто, поскольку ваша функция теперь, вероятно, выполняет две вещи.
df.reset_index(drop=True)
protected_series.reset_index(drop=True)
df['protected'] = protected_series
size name color protected
0 big rose red no
1 small violet blue no
2 small tulip red no
3 small harebell blue yes
Обратите внимание на df.assign
В то время как df.assign сделайте более ясным то, что вы делаете, на самом деле все те же проблемы, что и выше []=
df.assign(protected=pd.Series(['no', 'no', 'no', 'yes']))
size name color protected
3 big rose red yes
2 small violet blue no
1 small tulip red no
0 small harebell blue no
Просто остерегайтесь с df.assign что ваша колонка не называется self, Это приведет к ошибкам. Это делает df.assign вонючий, так как в функции есть такие артефакты.
df.assign(self=pd.Series(['no', 'no', 'no', 'yes'])
TypeError: assign() got multiple values for keyword argument 'self'
Вы можете сказать: "Ну, я просто не буду использовать self then". Но кто знает, как эта функция изменится в будущем для поддержки новых аргументов. Возможно, имя вашего столбца станет аргументом в новом обновлении pandas, что вызовет проблемы с обновлением.
Похоже, что в последних версиях Pandas можно использовать df.assign:
df1 = df1.assign(e=np.random.randn(sLength))
Не производит SettingWithCopyWarning,
Делать это напрямую через NumPy будет наиболее эффективным:
df1['e'] = np.random.randn(sLength)
Обратите внимание, мое оригинальное (очень старое) предложение было использовать map (что намного медленнее):
df1['e'] = df1['a'].map(lambda x: np.random.random())
Самые простые способы: -
data ['new_col'] = list_of_values
data.loc [:, 'new_col'] = list_of_values
Если вы хотите установить для всего нового столбца начальное базовое значение (например, None), вы можете сделать это: df1['e'] = None
Это на самом деле назначило бы тип "объект" для ячейки. Так что позже вы можете свободно помещать сложные типы данных, такие как список, в отдельные ячейки.
Я получил страшный SettingWithCopyWarningи это не было исправлено с помощью синтаксиса iloc. Мой DataFrame был создан read_sql из источника ODBC. Используя предложение lowtech выше, у меня сработало следующее:
df.insert(len(df.columns), 'e', pd.Series(np.random.randn(sLength), index=df.index))
Это работало нормально, чтобы вставить столбец в конце. Я не знаю, является ли это наиболее эффективным, но мне не нравятся предупреждающие сообщения. Я думаю, что есть лучшее решение, но я не могу найти его, и я думаю, что это зависит от некоторого аспекта индекса.
Примечание То, что это работает только один раз и выдаст сообщение об ошибке, если попытаться перезаписать существующий столбец.
Примечание. Как и выше, с 0.16.0 назначить является лучшим решением. См. Документацию http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.assign.html Хорошо работает для типа потока данных, где вы не перезаписываете свои промежуточные значения.
- Сначала создайте список python list_of_e, который имеет соответствующие данные.
- Используйте это: df['e'] = list_of_e
Если столбец, который вы пытаетесь добавить, является переменной серии, тогда просто:
df["new_columns_name"]=series_variable_name #this will do it for you
Это хорошо работает, даже если вы заменяете существующий столбец. Просто введите имя нового столбца, совпадающее с именем столбца, который вы хотите заменить. Он просто перезапишет данные существующего столбца данными новой серии.
Если фрейм данных и объект Series имеют одинаковый индекс, pandas.concat также работает здесь:
import pandas as pd
df
# a b c d
#0 0.671399 0.101208 -0.181532 0.241273
#1 0.446172 -0.243316 0.051767 1.577318
#2 0.614758 0.075793 -0.451460 -0.012493
e = pd.Series([-0.335485, -1.166658, -0.385571])
e
#0 -0.335485
#1 -1.166658
#2 -0.385571
#dtype: float64
# here we need to give the series object a name which converts to the new column name
# in the result
df = pd.concat([df, e.rename("e")], axis=1)
df
# a b c d e
#0 0.671399 0.101208 -0.181532 0.241273 -0.335485
#1 0.446172 -0.243316 0.051767 1.577318 -1.166658
#2 0.614758 0.075793 -0.451460 -0.012493 -0.385571
Если они не имеют одинаковый индекс:
e.index = df.index
df = pd.concat([df, e.rename("e")], axis=1)
Защищенное:
df.loc[:, 'NewCol'] = 'New_Val'
Пример:
df = pd.DataFrame(data=np.random.randn(20, 4), columns=['A', 'B', 'C', 'D'])
df
A B C D
0 -0.761269 0.477348 1.170614 0.752714
1 1.217250 -0.930860 -0.769324 -0.408642
2 -0.619679 -1.227659 -0.259135 1.700294
3 -0.147354 0.778707 0.479145 2.284143
4 -0.529529 0.000571 0.913779 1.395894
5 2.592400 0.637253 1.441096 -0.631468
6 0.757178 0.240012 -0.553820 1.177202
7 -0.986128 -1.313843 0.788589 -0.707836
8 0.606985 -2.232903 -1.358107 -2.855494
9 -0.692013 0.671866 1.179466 -1.180351
10 -1.093707 -0.530600 0.182926 -1.296494
11 -0.143273 -0.503199 -1.328728 0.610552
12 -0.923110 -1.365890 -1.366202 -1.185999
13 -2.026832 0.273593 -0.440426 -0.627423
14 -0.054503 -0.788866 -0.228088 -0.404783
15 0.955298 -1.430019 1.434071 -0.088215
16 -0.227946 0.047462 0.373573 -0.111675
17 1.627912 0.043611 1.743403 -0.012714
18 0.693458 0.144327 0.329500 -0.655045
19 0.104425 0.037412 0.450598 -0.923387
df.drop([3, 5, 8, 10, 18], inplace=True)
df
A B C D
0 -0.761269 0.477348 1.170614 0.752714
1 1.217250 -0.930860 -0.769324 -0.408642
2 -0.619679 -1.227659 -0.259135 1.700294
4 -0.529529 0.000571 0.913779 1.395894
6 0.757178 0.240012 -0.553820 1.177202
7 -0.986128 -1.313843 0.788589 -0.707836
9 -0.692013 0.671866 1.179466 -1.180351
11 -0.143273 -0.503199 -1.328728 0.610552
12 -0.923110 -1.365890 -1.366202 -1.185999
13 -2.026832 0.273593 -0.440426 -0.627423
14 -0.054503 -0.788866 -0.228088 -0.404783
15 0.955298 -1.430019 1.434071 -0.088215
16 -0.227946 0.047462 0.373573 -0.111675
17 1.627912 0.043611 1.743403 -0.012714
19 0.104425 0.037412 0.450598 -0.923387
df.loc[:, 'NewCol'] = 0
df
A B C D NewCol
0 -0.761269 0.477348 1.170614 0.752714 0
1 1.217250 -0.930860 -0.769324 -0.408642 0
2 -0.619679 -1.227659 -0.259135 1.700294 0
4 -0.529529 0.000571 0.913779 1.395894 0
6 0.757178 0.240012 -0.553820 1.177202 0
7 -0.986128 -1.313843 0.788589 -0.707836 0
9 -0.692013 0.671866 1.179466 -1.180351 0
11 -0.143273 -0.503199 -1.328728 0.610552 0
12 -0.923110 -1.365890 -1.366202 -1.185999 0
13 -2.026832 0.273593 -0.440426 -0.627423 0
14 -0.054503 -0.788866 -0.228088 -0.404783 0
15 0.955298 -1.430019 1.434071 -0.088215 0
16 -0.227946 0.047462 0.373573 -0.111675 0
17 1.627912 0.043611 1.743403 -0.012714 0
19 0.104425 0.037412 0.450598 -0.923387 0
Чтобы вставить новый столбец в заданном месте (0 <= loc <= количество столбцов) во фрейме данных, просто используйте Dataframe.insert:
DataFrame.insert(loc, column, value)
Поэтому, если вы хотите добавить столбец e в конце фрейма данных с именем df, вы можете использовать:
e = [-0.335485, -1.166658, -0.385571]
DataFrame.insert(loc=len(df.columns), column='e', value=e)
значение может быть Series, целым числом (в этом случае все ячейки заполняются этим одним значением) или структурой, подобной массиву
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.insert.html
Однако следует отметить, что если вы делаете
df1['e'] = Series(np.random.randn(sLength), index=df1.index)
фактически это будет левое соединение с df1.index. Поэтому, если вы хотите получить эффект внешнего соединения, моё, вероятно, несовершенное решение - создать фрейм данных со значениями индекса, охватывающими всю совокупность ваших данных, а затем использовать приведенный выше код. Например,
data = pd.DataFrame(index=all_possible_values)
df1['e'] = Series(np.random.randn(sLength), index=df1.index)
Позвольте мне добавить это, как и для hum3, .loc не решить SettingWithCopyWarning и мне пришлось прибегнуть к df.insert(), В моем случае ложное срабатывание было сгенерировано "фиктивной" цепной индексацией dict['a']['e'], где 'e' это новый столбец, и dict['a'] это датафрейм из словаря
Также обратите внимание, что если вы знаете, что делаете, вы можете переключить предупреждение с помощьюpd.options.mode.chained_assignment = Noneи чем использовать одно из других решений, приведенных здесь.
Перед назначением нового столбца, если вы проиндексировали данные, вам нужно отсортировать индекс. По крайней мере, в моем случае мне пришлось:
data.set_index(['index_column'], inplace=True)
"if index is unsorted, assignment of a new column will fail"
data.sort_index(inplace = True)
data.loc['index_value1', 'column_y'] = np.random.randn(data.loc['index_value1', 'column_x'].shape[0])
Чтобы добавить новый столбец 'e' в существующий фрейм данных
df1.loc[:,'e'] = Series(np.random.randn(sLength))
Я искал общий способ добавления столбца numpy.nanс кадром данных, не получая немой SettingWithCopyWarning,
Из следующего:
- ответы здесь
- этот вопрос о передаче переменной в качестве аргумента ключевого слова
- этот метод для генерации
numpyмассив NaNs в линии
Я придумал это:
col = 'column_name'
df = df.assign(**{col:numpy.full(len(df), numpy.nan)})
Если вам просто нужно создать новый пустой столбец, самое короткое решение:
df.loc[:, 'e'] = pd.Series()
4 способа вставить новый столбец в фрейм данных pandas
using simple assignment, insert(), assign() and Concat() methods.
import pandas as pd
df = pd.DataFrame({
'col_a':[True, False, False],
'col_b': [1, 2, 3],
})
print(df)
col_a col_b
0 True 1
1 False 2
2 False 3
Использование простого присваивания
ser = pd.Series(['a', 'b', 'c'], index=[0, 1, 2])
print(ser)
0 a
1 b
2 c
dtype: object
df['col_c'] = pd.Series(['a', 'b', 'c'], index=[1, 2, 3])
print(df)
col_a col_b col_c
0 True 1 NaN
1 False 2 a
2 False 3 b
Использование присваивания()
e = pd.Series([1.0, 3.0, 2.0], index=[0, 2, 1])
ser = pd.Series(['a', 'b', 'c'], index=[0, 1, 2])
df.assign(colC=s.values, colB=e.values)
col_a col_b col_c
0 True 1.0 a
1 False 3.0 b
2 False 2.0 c
Использование вставки()
df.insert(len(df.columns), 'col_c', ser.values)
print(df)
col_a col_b col_c
0 True 1 a
1 False 2 b
2 False 3 c
Использование конкат()
ser = pd.Series(['a', 'b', 'c'], index=[10, 20, 30])
df = pd.concat([df, ser.rename('colC')], axis=1)
print(df)
col_a col_b col_c
0 True 1.0 NaN
1 False 2.0 NaN
2 False 3.0 NaN
10 NaN NaN a
20 NaN NaN b
30 NaN NaN c
Ради полноты - еще одно решение с использованием метода DataFrame.eval():
Данные:
In [44]: e
Out[44]:
0 1.225506
1 -1.033944
2 -0.498953
3 -0.373332
4 0.615030
5 -0.622436
dtype: float64
In [45]: df1
Out[45]:
a b c d
0 -0.634222 -0.103264 0.745069 0.801288
4 0.782387 -0.090279 0.757662 -0.602408
5 -0.117456 2.124496 1.057301 0.765466
7 0.767532 0.104304 -0.586850 1.051297
8 -0.103272 0.958334 1.163092 1.182315
9 -0.616254 0.296678 -0.112027 0.679112
Решение:
In [46]: df1.eval("e = @e.values", inplace=True)
In [47]: df1
Out[47]:
a b c d e
0 -0.634222 -0.103264 0.745069 0.801288 1.225506
4 0.782387 -0.090279 0.757662 -0.602408 -1.033944
5 -0.117456 2.124496 1.057301 0.765466 -0.498953
7 0.767532 0.104304 -0.586850 1.051297 -0.373332
8 -0.103272 0.958334 1.163092 1.182315 0.615030
9 -0.616254 0.296678 -0.112027 0.679112 -0.622436
Если мы хотим присвоить значение масштабирования, например: 10, для всех строк нового столбца в df:
df = df.assign(new_col=lambda x:10) # x is each row passed in to the lambda func
У df теперь будет новый столбец new_col со значением =10 во всех строках.
Вот что я сделал... Но я довольно новичок в пандах и вообще в Python, так что никаких обещаний.
df = pd.DataFrame([[1, 2], [3, 4], [5,6]], columns=list('AB'))
newCol = [3,5,7]
newName = 'C'
values = np.insert(df.values,df.shape[1],newCol,axis=1)
header = df.columns.values.tolist()
header.append(newName)
df = pd.DataFrame(values,columns=header)
Если вы получите SettingWithCopyWarningлегко исправить, скопировав DataFrame, в который вы пытаетесь добавить столбец.
df = df.copy()
df['col_name'] = values
x=pd.DataFrame([1,2,3,4,5])
y=pd.DataFrame([5,4,3,2,1])
z=pd.concat([x,y],axis=1)

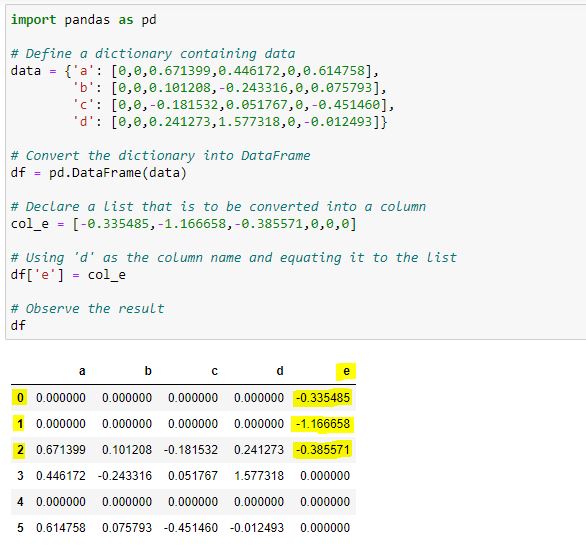
import pandas as pd
# Define a dictionary containing data
data = {'a': [0,0,0.671399,0.446172,0,0.614758],
'b': [0,0,0.101208,-0.243316,0,0.075793],
'c': [0,0,-0.181532,0.051767,0,-0.451460],
'd': [0,0,0.241273,1.577318,0,-0.012493]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# Declare a list that is to be converted into a column
col_e = [-0.335485,-1.166658,-0.385571,0,0,0]
df['e'] = col_e
# add column 'e'
df['e'] = col_e
# Observe the result
df
e = [ -0.335485, -1.166658, -0.385571]
Простой и легкий способ
df['e'] = e
Это особый случай добавления нового столбца в фреймворк pandas. Здесь я добавляю новую функцию / столбец на основе данных существующего столбца фрейма данных.
Итак, пусть в нашем фрейме данных есть столбцы "feature_1", "feature_2", "possible_score", и мы должны добавить новый_column "predicted_class" на основе данных в столбце "вероятность_score".
Я буду использовать функцию map() из Python, а также определю свою собственную функцию, которая будет реализовывать логику того, как присвоить конкретный class_label каждой строке в моем фрейме данных.
data = pd.read_csv('data.csv')
def myFunction(x):
//implement your logic here
if so and so:
return a
return b
variable_1 = data['probability_score']
predicted_class = variable_1.map(myFunction)
data['predicted_class'] = predicted_class
// check dataFrame, new column is included based on an existing column data for each row
data.head()