Как измерить время многопоточного процесса в многозадачной среде?
Поскольку я выполняю тесты оценки производительности моей многопоточной программы в многозадачной многозадачной среде (с вытесняющим упором), процесс может периодически заменяться. Я хочу вычислить задержку, т.е. только продолжительность, когда процесс был активен. Это позволит мне экстраполировать то, как производительность будет в не многозадачной среде, т. Е. Где работает только одна программа (большую часть времени) или при разных рабочих нагрузках.
Обычно измеряются два вида времени:
- Время настенных часов (т.е. время с начала процесса), но оно включает время, когда процесс был заменен.
- Время процессора (т. Е. Общая сумма времени процессора, используемого всеми потоками), но это не полезно для вычисления задержки процесса.
Я считаю, что мне нужно время выполнения отдельных потоков, которое может отличаться от максимального времени ЦП, используемого любым потоком, из-за структуры зависимостей задач между потоками. Например, в процессе с 2 потоками поток 1 сильно загружен в первые две трети времени выполнения (для времени ЦП t), в то время как поток 2 загружен в последние две трети времени выполнения процесса (опять же, для времени процессора т). В этом случае:
- время настенных часов вернет 3t/2 + время переключения контекста + время, используемое другими процессами между ними,
- максимальное время процессора всех потоков вернет значение, близкое к t, и
- общее время процессора близко к 2т.
- То, что я надеюсь получить в качестве результата измерения, - это рабочий диапазон, т. Е. 3t/2.
Кроме того, многопоточность сама по себе приносит неопределенность. Эту проблему, вероятно, можно решить, выполнив тест несколько раз и суммировав результаты.
Более того, задержка также зависит от того, как ОС планирует потоки; все усложняется, если некоторые потоки процесса ожидают ЦП, а другие работают. Но давайте забудем об этом.
Есть ли эффективный способ вычислить / приблизить это время выполнения? Для предоставления примеров кода, пожалуйста, используйте любой язык программирования, но предпочтительно C или C++ на Linux.
PS: я понимаю, что это определение makepan отличается от того, что используется при планировании задач. Определение, используемое в задачах планирования, похоже на время настенных часов.
1 ответ
Переформулировка вопроса
Я написал многопоточное приложение, выполнение которого на моей машине с K-ядром занимает X секунд.
Как оценить, сколько времени займет выполнение программы на одноядерном компьютере?
Эмпирически
Очевидное решение состоит в том, чтобы получить компьютер с одним ядром, запустить приложение и использовать время настенных часов и / или процессорное время, как вы пожелаете.
... Ой, подождите, у вашего компьютера уже есть одно ядро (у него также есть некоторые другие, но нам не нужно их использовать).
Как это сделать, будет зависеть от операционной системы, но один из первых результатов, которые я нашел от Google, объясняет несколько подходов для Windows XP и Vista.
http://masolution.blogspot.com/2008/01/how-to-use-only-one-core-of-multi-core.html
После этого вы можете:
- Присвойте процесс вашего Приложения единству ядра. (вы также можете сделать это в своем коде).
- Запустите свою операционную систему, зная только об одном из ваших ядер. (а затем переключитесь обратно)
Независимый параллелизм
Аналитическая оценка этого требует знания вашей программы, метода параллелизма и т. Д.
В качестве простого примера, предположим, я пишу многопоточную программу, которая вычисляет десятимиллиардную десятичную цифру числа пи и десятимиллиардную десятичную цифру числа е.
Мой код выглядит так:
public static int main()
{
Task t1 = new Task( calculatePiDigit );
Task t2 = new Task( calculateEDigit );
t1.Start();
t2.Start();
Task.waitall( t1, t2 );
}
И график "происходит до" выглядит так:
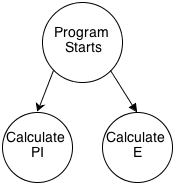
Очевидно, что они независимы.
В этом случае
- Время рассчитывает PiDigit() само по себе.
- Время рассчитывает EDigit() само по себе.
- Добавьте время вместе.
2-этапный трубопровод
Когда задачи не являются независимыми, вы не сможете просто добавить отдельные моменты времени вместе.
В этом следующем примере я создаю многопоточное приложение, чтобы: взять 10 изображений, преобразовать их в оттенки серого, а затем запустить алгоритм обнаружения линий. По какой-то внешней причине все изображения не могут быть обработаны не по порядку. Из-за этого я создаю шаблон конвейера.
Мой код выглядит примерно так:
ConcurrentQueue<Image> originalImages = new ConcurrentQueue<Image>();
ConcurrentQueue<Image> grayscaledImages = new ConcurrentQueue<Image>();
ConcurrentQueue<Image> completedImages = new ConcurrentQueue<Image>();
public static int main()
{
PipeLineStage p1 = new PipeLineStage(originalImages, grayScale, grayscaledImages);
PipeLineStage p2 = new PipeLineStage(grayscaledImages, lineDetect, completedImages);
p1.Start();
p2.Start();
originalImages.add( image1 );
originalImages.add( image2 );
//...
originalImages.add( image10 );
originalImages.add( CancellationToken );
Task.WaitAll( p1, p2 );
}
График, ориентированный на данные, происходит до:
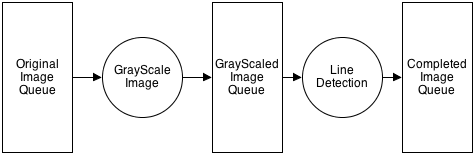
Если бы эта программа изначально была спроектирована как последовательная программа, по причинам кеширования было бы более эффективно брать каждое изображение по одному и перемещать их к завершенному, прежде чем переходить к следующему изображению.
В любом случае, мы знаем, что GrayScale() будет вызываться 10 раз, а LineDetection() будет вызываться 10 раз, поэтому мы можем просто рассчитать время независимо друг от друга, а затем умножить их на 10.
Но как насчет затрат на отправку / прослушивание / опрос ConcurrentQueues?
Если предположить, что изображения большие, это время будет незначительным.
Если существуют миллионы маленьких изображений с большим количеством потребителей на каждом этапе, вы, вероятно, обнаружите, что издержки на ожидание блокировок, мьютексов и т. Д. Очень малы, когда программа запускается последовательно (при условии, что объем работы, выполненной в критические секции малы, например, в параллельной очереди).
Затраты на переключение контекста?
Посмотрите на этот вопрос:
Как оценить издержки переключения контекста потока?
По сути, у вас будут переключатели контекста в многоядерных средах и в одноядерных средах.
Затраты на переключение контекста довольно малы, но они также происходят очень много раз в секунду.
Опасность заключается в том, что кеш полностью разрушается между переключениями контекста.
Например, в идеале:
- image1 загружается в кеш в результате выполнения GrayScale
- LineDetection будет работать намного быстрее на image1, так как он находится в кеше
Однако это может произойти:
- image1 загружается в кеш в результате выполнения GrayScale
- image2 загружается в кеш в результате выполнения GrayScale
- теперь этап 2 конвейера запускает LineDetection для image1, но image1 больше не находится в кэше.
Заключение
Ничто не сравнится по времени в той же среде, в которой оно будет запущено.
Далее лучше всего смоделировать эту среду, насколько это возможно.
Независимо от этого, понимание дизайна вашей программы должно дать вам представление о том, чего ожидать в новой среде.