Алгоритм поиска блоков трендов
Допустим, у меня есть 24 строки данных, так что каждая строка представляет час в день. Чего я хочу добиться, так это реализовать алгоритм, который может обнаруживать тренды в данных и делить их на 2 блока - "хороший" блок и "плохой" блок. например, на прикрепленном изображении вы можете видеть, что в строке 6 хороший блок начинается и заканчивается в строке 19. строка 0 также имеет хороший счет, но она не является частью блока, поэтому алгоритм должен знать, как справиться с этой ситуацией. Я думаю, что это кластеризация, но я не смог найти что-то достаточно простое, соответствующее нашим потребностям. Ждем любых советов.
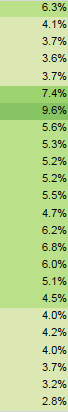
1 ответ
start = -1
Append a below-threshold value to the end of the data array x[]
For i from 1 to n:
If x[i] >= thresholdValue:
if start == -1:
start = i
Else:
If start != -1 and i - start >= thresholdLength:
ReportGoodBlock(start, i-1)
start = -1