MATLAB: как отобразить кодированный в кодировке UTF-8 текст из файла?
Суть моего вопроса заключается в следующем:
Как я могу отобразить символы Unicode в GUI (OS X) Matlab, чтобы они правильно отображались?
Подробности:
У меня есть таблица строк, хранящихся в файле, и некоторые из этих строк содержат символы Unicode в кодировке UTF-8. Я пробовал много разных способов (слишком много, чтобы перечислять здесь), чтобы отобразить содержимое этого файла в GUI MATLAB, но безуспешно. Например:
>> fid = fopen('/Users/kj/mytable.txt', 'r', 'n', 'UTF-8');
>> [x, x, x, enc] = fopen(fid); enc
enc =
UTF-8
>> tbl = textscan(fid, '%s', 35, 'delimiter', ',');
>> tbl{1}{1}
ans =
ÎÎÎÎÎΠΣΦΩαβγδεζηθικλμνξÏÏÏÏÏÏÏÏÏÏ
>>
Когда это происходит, если я вставляю строку непосредственно в графический интерфейс MATLAB, вставленная строка отображается правильно, что показывает, что графический интерфейс не способен в принципе отображать эти символы, но как только MATLAB читает его, он дольше отображает его правильно. Например:
>> pasted = 'ΓΔΘΛΞΠΣΦΩαβγδεζηθικλμνξπρςστυφχψω'
pasted =
>>
Спасибо!
1 ответ
Ниже я приведу свои выводы после некоторых копаний... Рассмотрим следующие тестовые файлы:
a.txt
ΓΔΘΛΞΠΣΦΩαβγδεζηθικλμνξπρςστυφχψω
b.txt
தமிழ்
Сначала мы читаем файлы:
%# open file in binary mode, and read a list of bytes
fid = fopen('a.txt', 'rb');
b = fread(fid, '*uint8')'; %'# read bytes
fclose(fid);
%# decode as unicode string
str = native2unicode(b,'UTF-8');
Если вы попытаетесь напечатать строку, вы получите кучу глупостей:
>> str
str =
Тем не менее, str действительно содержит правильную строку. Мы можем проверить код Unicode каждого символа, который, как вы можете видеть, выходит за пределы диапазона ASCII (последние два - непечатаемые окончания строки CR-LF):
>> double(str)
ans =
Columns 1 through 13
915 916 920 923 926 928 931 934 937 945 946 947 948
Columns 14 through 26
949 950 951 952 953 954 955 956 957 958 960 961 962
Columns 27 through 35
963 964 965 966 967 968 969 13 10
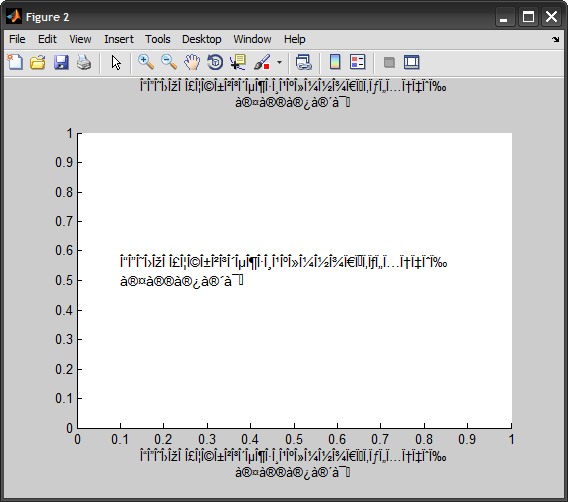
К сожалению, MATLAB, похоже, не может отобразить эту строку Unicode в графическом интерфейсе самостоятельно. Например, все это терпит неудачу:
figure
text(0.1, 0.5, str, 'FontName','Arial Unicode MS')
title(str)
xlabel(str)
Один прием, который я обнаружил, заключается в использовании встроенной возможности Java:
%# Java Swing
label = javax.swing.JLabel();
label.setFont( java.awt.Font('Arial Unicode MS',java.awt.Font.PLAIN, 30) );
label.setText(str);
f = javax.swing.JFrame('frame');
f.getContentPane().add(label);
f.pack();
f.setVisible(true);

Когда я готовился написать выше, я нашел альтернативное решение. Мы можем использовать DefaultCharacterSet недокументированная функция и установите кодировку в UTF-8 (на моей машине это ISO-8859-1 по умолчанию):
feature('DefaultCharacterSet','UTF-8');
Теперь с правильным шрифтом (вы можете изменить шрифт, используемый в окне команд из Preferences > Font), мы можем напечатать строку в приглашении (обратите внимание, что DISP по-прежнему не способен печатать Unicode):
>> str
str =
ΓΔΘΛΞΠΣΦΩαβγδεζηθικλμνξπρςστυφχψω
>> disp(str)
ΓΔΘΛΞΠΣΦΩαβγδεζηθικλμνξπÏςστυφχψω
И чтобы отобразить его в графическом интерфейсе, UICONTROL должен работать (под капотом, я думаю, что это действительно компонент Java Swing):
uicontrol('Style','text', 'String',str, ...
'Units','normalized', 'Position',[0 0 1 1], ...
'FontName','Arial Unicode MS', 'FontSize',30)
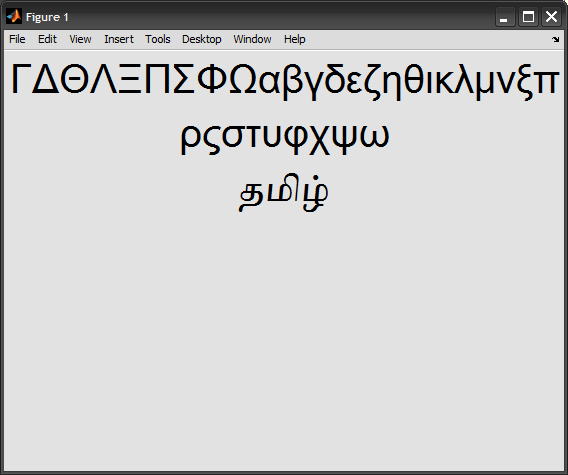
К сожалению, TEXT, TITLE, XLABEL и т. Д. Все еще показывают мусор:
В качестве примечания: в редакторе MATLAB сложно работать с источниками m-файлов, содержащими символы Unicode. Я использовал Notepad++ с файлами в кодировке UTF-8 без спецификации.