SQLite - UPSERT * не * Вставить или заменить
http://en.wikipedia.org/wiki/Upsert
Вставить обновление хранимой процедуры на SQL Server
Есть ли какой-нибудь умный способ сделать это в SQLite, о котором я не думал?
В основном я хочу обновить три из четырех столбцов, если запись существует, если она не существует, я хочу вставить запись со значением по умолчанию (NUL) для четвертого столбца.
Идентификатор является первичным ключом, поэтому в UPSERT будет только одна запись.
(Я пытаюсь избежать издержек SELECT, чтобы определить, нужно ли мне ОБНОВИТЬ или ВСТАВИТЬ, очевидно)
Предложения?
Я не могу подтвердить, что синтаксис на сайте SQLite для TABLE CREATE. Я не построил демо-версию, чтобы проверить его, но он не поддерживается...
Если бы это было так, у меня есть три столбца, так что это будет выглядеть так:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
но первые два больших двоичных объекта не вызовут конфликта, только идентификатор будет таким образом. Поэтому я не могу заменить Blob1 и Blob2 (по желанию)
ОБНОВЛЕНИЯ в SQLite, когда данные привязки представляют собой полную транзакцию, то есть каждая отправляемая строка, подлежащая обновлению, требует: операторов Prepare/Bind/Step/Finalize в отличие от INSERT, который позволяет использовать функцию сброса
Жизнь объекта оператора выглядит примерно так:
- Создайте объект с помощью sqlite3_prepare_v2()
- Привязать значения к параметрам хоста, используя интерфейсы sqlite3_bind_.
- Запустите SQL, вызвав sqlite3_step()
- Сбросьте инструкцию с помощью sqlite3_reset(), затем вернитесь к шагу 2 и повторите.
- Уничтожьте объект оператора с помощью sqlite3_finalize().
ОБНОВЛЕНИЕ Я предполагаю, медленный по сравнению с INSERT, но как это сравнить с SELECT с использованием первичного ключа?
Возможно, мне следует использовать select, чтобы прочитать 4-й столбец (Blob3), а затем использовать REPLACE, чтобы написать новую запись, смешивая исходный 4-й столбец с новыми данными для первых 3 столбцов?
19 ответов
Предполагая 3 столбца в таблице. ID, NAME, ROLE
ПЛОХОЙ: Это вставит или заменит все столбцы с новыми значениями для ID=1:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, 'John Foo', 'CEO');
ПЛОХОЙ: это вставит или заменит 2 столбца... столбцу ИМЯ будет присвоено значение NULL или значение по умолчанию:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, 'code monkey');
ХОРОШО: Это обновит 2 столбца. Когда ID = 1 существует, имя не изменится. Когда ID = 1 не существует, имя будет по умолчанию (NULL).
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
'code monkey',
(SELECT name FROM Employee WHERE id = 1)
);
Это обновит 2 столбца. Когда ID = 1 существует, роль не будет затронута. Когда ID = 1 не существует, роль будет установлена на "Benchwarmer" вместо значения по умолчанию.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
'Susan Bar',
COALESCE((SELECT role FROM Employee WHERE id = 1), 'Benchwarmer')
);
ВСТАВКА ИЛИ ЗАМЕНА НЕ эквивалентны "UPSERT".
Допустим, у меня есть таблица Employee с полями id, name и role:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Бум, вы потеряли имя сотрудника номер 1. SQLite заменил его значением по умолчанию.
Ожидаемый результат UPSERT будет состоять в том, чтобы изменить роль и сохранить имя.
Ответ Эрика Б. " Хорошо", если вы хотите сохранить только один или два столбца из существующей строки. Если вы хотите сохранить много столбцов, он становится слишком громоздким.
Вот подход, который будет хорошо масштабироваться для любого количества столбцов с обеих сторон. Для иллюстрации приведу следующую схему:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Обратите внимание, в частности, что name является естественным ключом строки - id используется только для внешних ключей, поэтому SQLite сам выбирает значение идентификатора при вставке новой строки. Но при обновлении существующей строки на основе его nameЯ хочу, чтобы он продолжал иметь старое значение идентификатора (очевидно!).
Я добиваюсь истинного UPSERT со следующей конструкцией:
WITH new (name, title, author) AS ( VALUES('about', 'About this site', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
Точная форма этого запроса может немного отличаться. Ключ является использование INSERT SELECT с левым внешним соединением, чтобы присоединить существующую строку к новым значениям.
Здесь, если строка ранее не существовала, old.id будет NULL SQLite автоматически назначит идентификатор, но если такая строка уже была, old.id будет иметь фактическое значение, и это будет использоваться повторно. Что именно то, что я хотел.
На самом деле это очень гибко. Обратите внимание, как ts колонка полностью отсутствует со всех сторон - потому что она имеет DEFAULT ценность, SQLite просто сделает правильную вещь в любом случае, поэтому мне не нужно заботиться об этом самостоятельно.
Вы также можете включить столбец на new а также old стороны, а затем использовать, например, COALESCE(new.content, old.content) во внешнем SELECT сказать "вставить новое содержимое, если оно было, иначе сохранить старое содержимое" - например, если вы используете фиксированный запрос и связываете новые значения с заполнителями.
2018-05-18 СТОП ПРЕСС.
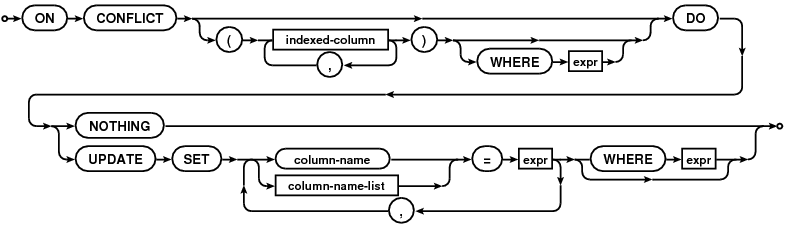
Поддержка UPSERT в SQLite! Синтаксис UPSERT был добавлен в SQLite с версией 3.24.0 (ожидается)!
UPSERT - это специальное синтаксическое дополнение к INSERT, которое заставляет INSERT вести себя как UPDATE или no-op, если INSERT нарушает ограничение уникальности. UPSERT не является стандартным SQL. UPSERT в SQLite следует синтаксису, установленному PostgreSQL.
Я знаю, что опоздал на вечеринку, но....
UPDATE employee SET role = 'code_monkey', name='fred' WHERE id = 1;
INSERT OR IGNORE INTO employee(id, role, name) values (1, 'code monkey', 'fred');
Таким образом, он пытается обновить, если запись есть, то вставка не обработана.
альтернативно:
Еще один совершенно другой способ сделать это: в моем приложении я установил в строке rowID значение long.MaxValue, когда я создаю строку в памяти. (MaxValue никогда не будет использоваться в качестве идентификатора, который вы не проживете достаточно долго... Тогда, если rowID не является этим значением, тогда он уже должен быть в базе данных, поэтому требуется ОБНОВЛЕНИЕ, если это MaxValue, тогда ему нужна вставка. Это полезно только в том случае, если вы можете отслеживать идентификаторы строк в своем приложении.
Если вы вообще делаете обновления, я бы..
- Начать сделку
- Сделать обновление
- Проверьте количество строк
- Если это 0, сделайте вставку
- совершить
Если вы вообще делаете вставки, я бы
- Начать сделку
- Попробуйте вставить
- Проверьте наличие ошибки первичного ключа
- если мы получили ошибку, сделайте обновление
- совершить
Таким образом, вы избегаете выбора и получаете транзакционный звук на Sqlite.
Я понимаю, что это старый поток, но в последнее время я работал в sqlite3 и придумал этот метод, который лучше соответствовал моим потребностям в динамическом генерировании параметризованных запросов:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
Это по-прежнему 2 запроса с предложением where при обновлении, но, похоже, делает свое дело. У меня также есть такое видение, что sqlite может полностью оптимизировать оператор обновления, если вызов change () больше нуля. Насколько мне это известно, или нет, но человек может мечтать, не так ли?;)
Для бонусных баллов вы можете добавить эту строку, которая возвращает вам идентификатор строки, будь то новая вставленная строка или существующая строка.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
Начиная с версии 3.24.0, UPSERT поддерживается SQLite.
Из документации:
UPSERT - это специальное синтаксическое дополнение к INSERT, которое заставляет INSERT вести себя как UPDATE или no-op, если INSERT нарушает ограничение уникальности. UPSERT не является стандартным SQL. UPSERT в SQLite следует синтаксису, установленному PostgreSQL. Синтаксис UPSERT был добавлен в SQLite с версией 3.24.0 (ожидается).
UPSERT - это обычный оператор INSERT, за которым следует специальное предложение ON CONFLICT.
https://www.sqlite.org/images/syntax/upsert-clause.gif
Источник изображения: https://www.sqlite.org/images/syntax/upsert-clause.gif
Вы действительно можете сделать переход в SQLite, он выглядит немного иначе, чем вы привыкли. Это будет выглядеть примерно так:
INSERT INTO table name (column1, column2)
VALUES ("value12", "value2") WHERE id = 123
ON CONFLICT DO UPDATE
SET column1 = "value1", column2 = "value2" WHERE id = 123
Вот решение, которое действительно является UPSERT (ОБНОВЛЕНИЕ или ВСТАВКА) вместо ВСТАВКИ ИЛИ ЗАМЕНЫ (которая работает по-разному во многих ситуациях).
Это работает так:
1. Попробуйте обновить, если существует запись с таким же Id.
2. Если обновление не изменило ни одной строки (NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0)), затем вставьте запись.
Таким образом, либо существующая запись была обновлена, либо будет выполнена вставка.
Важной деталью является использование SQL-функции changes () для проверки попадания оператора обновления в какие-либо существующие записи и выполнения оператора вставки только в том случае, если он не обнаружил ни одной записи.
Следует отметить, что функция changes () не возвращает изменения, выполненные триггерами более низкого уровня (см. http://sqlite.org/lang_corefunc.html), поэтому обязательно примите это во внимание.
Вот SQL...
Тестовое обновление:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Тестовая вставка:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Расширяя ответ Аристотеля, вы можете ВЫБРАТЬ из фиктивной "синглтонной" таблицы (таблицы вашего собственного создания с одной строкой). Это позволяет избежать некоторого дублирования.
Я также сохранил пример переносимого через MySQL и SQLite и использовал столбец date_added в качестве примера того, как вы можете установить столбец только в первый раз.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
Лучший подход, который я знаю, это сделать обновление с последующей вставкой. "Затраты на выбор" необходимы, но это не страшное бремя, поскольку вы выполняете поиск по первичному ключу, что очень быстро.
Вы должны иметь возможность изменять приведенные ниже операторы с именами таблиц и полей, чтобы делать то, что вы хотите.
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
Если кто-то хочет прочитать мое решение для SQLite в Кордове, я получил этот общий метод js благодаря ответу @david выше.
function addOrUpdateRecords(tableName, values, callback) {
get_columnNames(tableName, function (data) {
var columnNames = data;
myDb.transaction(function (transaction) {
var query_update = "";
var query_insert = "";
var update_string = "UPDATE " + tableName + " SET ";
var insert_string = "INSERT INTO " + tableName + " SELECT ";
myDb.transaction(function (transaction) {
// Data from the array [[data1, ... datan],[()],[()]...]:
$.each(values, function (index1, value1) {
var sel_str = "";
var upd_str = "";
var remoteid = "";
$.each(value1, function (index2, value2) {
if (index2 == 0) remoteid = value2;
upd_str = upd_str + columnNames[index2] + "='" + value2 + "', ";
sel_str = sel_str + "'" + value2 + "', ";
});
sel_str = sel_str.substr(0, sel_str.length - 2);
sel_str = sel_str + " WHERE NOT EXISTS(SELECT changes() AS change FROM "+tableName+" WHERE change <> 0);";
upd_str = upd_str.substr(0, upd_str.length - 2);
upd_str = upd_str + " WHERE remoteid = '" + remoteid + "';";
query_update = update_string + upd_str;
query_insert = insert_string + sel_str;
// Start transaction:
transaction.executeSql(query_update);
transaction.executeSql(query_insert);
});
}, function (error) {
callback("Error: " + error);
}, function () {
callback("Success");
});
});
});
}
Итак, сначала подберите имена столбцов с помощью этой функции:
function get_columnNames(tableName, callback) {
myDb.transaction(function (transaction) {
var query_exec = "SELECT name, sql FROM sqlite_master WHERE type='table' AND name ='" + tableName + "'";
transaction.executeSql(query_exec, [], function (tx, results) {
var columnParts = results.rows.item(0).sql.replace(/^[^\(]+\(([^\)]+)\)/g, '$1').split(','); ///// RegEx
var columnNames = [];
for (i in columnParts) {
if (typeof columnParts[i] === 'string')
columnNames.push(columnParts[i].split(" ")[0]);
};
callback(columnNames);
});
});
}
Затем создайте транзакции программно.
"Значения" - это массив, который вы должны построить раньше, и он представляет строки, которые вы хотите вставить или обновить в таблице.
"remoteid" - это идентификатор, который я использовал в качестве ссылки, так как я синхронизируюсь с моим удаленным сервером.
Для использования плагина SQLite Cordova, пожалуйста, обратитесь к официальной ссылке
После Аристотеля Пагальциса и идеи COALESCE согласно ответу Эрика Б., здесь есть вариант обновления, чтобы обновить только несколько столбцов или вставить полную строку, если она не существует.
В этом случае представьте, что заголовок и содержимое должны быть обновлены, сохраняя другие старые значения, если они существуют, и вставляя предоставленные, если имя не найдено:
НОТА id вынужден быть NULL, когда INSERT как это должно быть автоинкремент. Если это просто сгенерированный первичный ключ, то COALESCE также может быть использован (см. комментарий Аристотеля Пагальциса).
WITH new (id, name, title, content, author)
AS ( VALUES(100, 'about', 'About this site', 'Whatever new content here', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT
old.id, COALESCE(old.name, new.name),
new.title, new.content,
COALESCE(old.author, new.author)
FROM new LEFT JOIN page AS old ON new.name = old.name;
Таким образом, общее правило: если вы хотите сохранить старые значения, используйте COALESCE, когда вы хотите обновить значения, используйте new.fieldname
Я думаю, что это может быть то, что вы ищете: ON CONFLICT.
Если вы определите свою таблицу следующим образом:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
field1 TEXT
);
Теперь, если вы делаете INSERT с уже существующим идентификатором, SQLite автоматически выполняет UPDATE вместо INSERT.
Hth...
Этот метод смешивает несколько других методов из ответа на этот вопрос и включает в себя использование CTE (Common Table Expressions). Я представлю запрос, а затем объясню, почему я сделал то, что сделал.
Я хотел бы изменить фамилию сотрудника 300 на ДЭВИС, если есть сотрудник 300. В противном случае я добавлю нового сотрудника.
Имя таблицы: сотрудники Столбцы: id, first_name, last_name
Запрос:
INSERT OR REPLACE INTO employees (employee_id, first_name, last_name)
WITH registered_employees AS ( --CTE for checking if the row exists or not
SELECT --this is needed to ensure that the null row comes second
*
FROM (
SELECT --an existing row
*
FROM
employees
WHERE
employee_id = '300'
UNION
SELECT --a dummy row if the original cannot be found
NULL AS employee_id,
NULL AS first_name,
NULL AS last_name
)
ORDER BY
employee_id IS NULL --we want nulls to be last
LIMIT 1 --we only want one row from this statement
)
SELECT --this is where you provide defaults for what you would like to insert
registered_employees.employee_id, --if this is null the SQLite default will be used
COALESCE(registered_employees.first_name, 'SALLY'),
'DAVIS'
FROM
registered_employees
;
По сути, я использовал CTE, чтобы уменьшить количество раз, когда оператор select должен использоваться для определения значений по умолчанию. Поскольку это CTE, мы просто выбираем нужные столбцы из таблицы, и оператор INSERT использует это.
Теперь вы можете решить, какие значения по умолчанию вы хотите использовать, заменив пустые значения в функции COALESCE на то, какими должны быть значения.
Если не возражаете, проделайте это за две операции.
Шаги:
1) Добавьте новые элементы с помощью "ВСТАВИТЬ ИЛИ ИГНОРИРОВАТЬ"
2) Обновите существующие элементы с помощью "ОБНОВЛЕНИЕ"
Входными данными для обоих шагов является один и тот же набор новых или обновляемых элементов. Прекрасно работает с существующими элементами, которые не требуют изменений. Они будут обновлены, но с теми же данными, и, следовательно, чистый результат - без изменений.
Конечно, медленнее и т. Д. Неэффективно. Ага.
Легко написать sql и поддерживать и понимать его? Определенно.
Это компромисс, который следует учитывать. Отлично подходит для небольших апсертов. Отлично подходит для тех, кто не против пожертвовать эффективностью ради удобства сопровождения кода.
Полный пример обновления с помощью WHERE для выбора более новой датированной записи.
-- https://www.db-fiddle.com/f/7jyj4n76MZHLLk2yszB6XD/22
DROP TABLE IF EXISTS db;
CREATE TABLE db
(
id PRIMARY KEY,
updated_at,
other
);
-- initial INSERT
INSERT INTO db (id,updated_at,other) VALUES(1,1,1);
SELECT * FROM db;
-- INSERT without WHERE
INSERT INTO db (id,updated_at,other) VALUES(1,2,2)
ON CONFLICT(id) DO UPDATE SET updated_at=excluded.updated_at;
SELECT * FROM db;
-- WHERE is FALSE
INSERT INTO db (id,updated_at,other) VALUES(1,2,3)
ON CONFLICT(id) DO UPDATE SET updated_at=excluded.updated_at, other=excluded.other
WHERE excluded.updated_at > updated_at;
SELECT * FROM db;
-- ok to SET a PRIMARY KEY. WHERE is TRUE
INSERT INTO db (id,updated_at,other) VALUES(1,3,4)
ON CONFLICT(id) DO UPDATE SET id=excluded.id, updated_at=excluded.updated_at, other=excluded.other
WHERE excluded.updated_at > updated_at;
SELECT * FROM db;
Просто прочитав эту ветку и разочаровавшись в том, что нелегко было просто заняться этим "UPSERT", я продолжил расследование...
На самом деле вы можете сделать это напрямую и легко в SQLITE.
Вместо того, чтобы использовать: INSERT INTO
Использование: INSERT OR REPLACE INTO
Это именно то, что вы хотите!
SELECT COUNT(*) FROM table1 WHERE id = 1;
если COUNT(*) = 0
INSERT INTO table1(col1, col2, cole) VALUES(var1,var2,var3);
иначе если COUNT(*) > 0
UPDATE table1 SET col1 = var4, col2 = var5, col3 = var6 WHERE id = 1;