ANTLR: от CommonTree к графу полезных объектов
Я начал использовать ANTLR сегодня и создал базовый парсер.
После разбора у меня получается дерево. Мне кажется, что это просто куча StringS соединены в древовидную структуру Tree-nodes. Это не очень полезно для меня. Я хотел бы иметь график объектов.
Чтобы уточнить (это пример, а не мое реальное приложение): Для "5-1+6" Я, кажется, в конечном итоге:
new String("PLUS")
new String("MINUS")
new String("5")
new String("1")
new String("6")
Что бы я нашел более полезным:
new Plus(
new Minus(
new IntegerLiteral(5),
new IntegerLiteral(1)),
new IntegerLiteral(6))
Каков наиболее удобный способ перехода от первого представления к другому? В этой статье автор делает нечто похожее на это:
public Expression createExpr(CommonTree ast) {
// ...
switch (ast.getType()) {
case SimpleExpressionParser.INT:
return new IntegerLiteral(ast.getText())
case SimpleExpressionParser.PLUS:
return new Plus(createExpr((CommonTree)ast.getChild(0)), // recurse
createExpr((CommonTree)ast.getChild(1))); // recurse
case SimpleExpressionParser.MINUS:
return new Minus(createExpr((CommonTree)ast.getChild(0)), // recurse
createExpr((CommonTree)ast.getChild(1))); // recurse
}
// ...
}
Это предпочтительный способ?! Разве я не могу поручить ANTLR как-то сгенерировать этот код котла (он будет огромным)?
Возможно связанные вопросы:
- Преобразование синтаксического дерева Antlr в полезные объекты (но я не вижу, как ответ отвечает на мой вопрос.)
1 ответ
Вот возможный способ. Короче говоря, это шаг, который вы должны выполнить:
- создать комбинированную грамматику, которая будет генерировать лексер и парсер;
- смешайте правила переписывания AST в грамматике из (1), чтобы преобразовать плоский список токенов в правильное дерево;
- написать грамматику дерева, по которой можно ходить по дереву (2);
- смешать пользовательский код внутри вашего дерева ходунки;
- Попробуй это.
1
Давайте создадим небольшой анализатор выражений, поддерживающий +, -, *, /, (...) и цифры, которые могут выглядеть так:
grammar Exp; // file: Exp.g
eval
: exp EOF
;
exp
: addExp
;
addExp
: mulExp ((Add | Sub) mulExp)*
;
mulExp
: unaryExp ((Mul | Div) unaryExp)*
;
unaryExp
: Sub atom
| atom
;
atom
: Number
| '(' exp ')'
;
Add : '+';
Sub : '-';
Mul : '*';
Div : '/';
Number : '0'..'9'+;
Space : ' ' {skip();};
2
Включая правила перезаписи, это будет выглядеть так:
grammar Exp; // file: Exp.g
options {
output=AST;
}
tokens {
U_SUB;
}
eval
: exp EOF -> exp
;
exp
: addExp
;
addExp
: mulExp ((Add | Sub)^ mulExp)*
;
mulExp
: unaryExp ((Mul | Div)^ unaryExp)*
;
unaryExp
: Sub atom -> ^(U_SUB atom)
| atom
;
atom
: Number
| '(' exp ')' -> exp
;
Add : '+';
Sub : '-';
Mul : '*';
Div : '/';
Number : '0'..'9'+;
Space : ' ' {skip();};
Теперь выражение как 10 - 2 * (3 + 8) будет преобразован в:
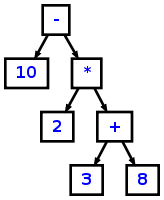
3
Чтобы создать древовидную грамматику, которая генерирует итератор для AST, сгенерированного в (2), вы должны сделать что-то вроде этого:
tree grammar ExpWalker; // file: ExpWalker.g
options {
tokenVocab=Exp; // use the tokens from Exp.g
ASTLabelType=CommonTree;
}
eval
: exp
;
exp
: ^(Add exp exp)
| ^(Sub exp exp)
| ^(Mul exp exp)
| ^(Div exp exp)
| ^(U_SUB exp)
| Number
;
4
И чтобы смешать ваши пользовательские классы в этом итераторе дерева, сделайте что-то вроде этого:
tree grammar ExpWalker; // file: ExpWalker.g
options {
tokenVocab=Exp; // use the tokens from Exp.g
ASTLabelType=CommonTree;
}
eval returns [ExpNode e]
: exp {e = $exp.e;}
;
exp returns [ExpNode e]
: ^(Add a=exp b=exp) {e = new AddExp($a.e, $b.e);}
| ^(Sub a=exp b=exp) {e = new SubExp($a.e, $b.e);}
| ^(Mul a=exp b=exp) {e = new MulExp($a.e, $b.e);}
| ^(Div a=exp b=exp) {e = new DivExp($a.e, $b.e);}
| ^(U_SUB a=exp) {e = new UnaryExp($a.e);}
| Number {e = new NumberExp($Number.text);}
;
5
Вот некоторый код для проверки всех классов (поместите все в один файл: Main.java):
import org.antlr.runtime.*;
import org.antlr.runtime.tree.*;
import org.antlr.stringtemplate.*;
public class Main {
public static void main(String[] args) throws Exception {
String source = "10 - 2 * (3 + 8)";
ExpLexer lexer = new ExpLexer(new ANTLRStringStream(source));
CommonTokenStream tokens = new CommonTokenStream(lexer);
ExpParser parser = new ExpParser(tokens);
ExpParser.eval_return returnValue = parser.eval();
CommonTree tree = (CommonTree)returnValue.getTree();
CommonTreeNodeStream nodes = new CommonTreeNodeStream(tree);
ExpWalker walker = new ExpWalker(nodes);
ExpNode root = walker.eval();
System.out.println(source + " = " + root.evaluate());
}
}
interface ExpNode {
double evaluate();
}
class NumberExp implements ExpNode {
final double num;
NumberExp(String s) {
num = Double.parseDouble(s);
}
@Override
public double evaluate() {
return num;
}
}
class AddExp implements ExpNode {
final ExpNode left, right;
AddExp(ExpNode a, ExpNode b) {
left = a;
right = b;
}
@Override
public double evaluate() {
return left.evaluate() + right.evaluate();
}
}
class SubExp implements ExpNode {
final ExpNode left, right;
SubExp(ExpNode a, ExpNode b) {
left = a;
right = b;
}
@Override
public double evaluate() {
return left.evaluate() - right.evaluate();
}
}
class MulExp implements ExpNode {
final ExpNode left, right;
MulExp(ExpNode a, ExpNode b) {
left = a;
right = b;
}
@Override
public double evaluate() {
return left.evaluate() * right.evaluate();
}
}
class DivExp implements ExpNode {
final ExpNode left, right;
DivExp(ExpNode a, ExpNode b) {
left = a;
right = b;
}
@Override
public double evaluate() {
return left.evaluate() / right.evaluate();
}
}
class UnaryExp implements ExpNode {
final ExpNode exp;
UnaryExp(ExpNode e) {
exp = e;
}
@Override
public double evaluate() {
return -exp.evaluate();
}
}
а затем сделать:
# создать лексер и парсер java -cp antlr-3.2.jar org.antlr.Tool Exp.g # генерировать дерево ходок java -cp antlr-3.2.jar org.antlr.Tool ExpWalker.g # скомпилировать все javac -cp antlr-3.2.jar *.java # запустить основной класс java -cp .:antlr-3.2.jar Main # *nix java -cp .;antlr-3.2.jar Главная # Windows
который печатает:
10 - 2 * (3 + 8) = -12,0
Вы можете пропустить странника и смешать весь код и returns [...] внутри вашей объединенной грамматики, но IMO, древовидная грамматика хранит вещи более упорядоченно, потому что лексер управляет, и токены как ( а также ) и т. д. удалены из него.
НТН