Измерение "визуального воздействия" фрагмента текста по его растровому изображению
Я стремлюсь к этому в основном из любопытства, в стремлении создать идеальный алгоритм облака тегов. Получив данные в форме (термин, оценка), он отображает текст так, что его визуальное воздействие идеально соответствует его оценке.
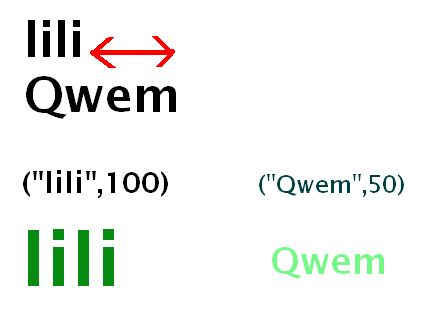
Что касается "визуального воздействия", то как человеческий глаз воспринимает размер / влияние текста. Изображение ниже показывает, что я имею в виду: как для изображений, визуальное воздействие которых можно явно определить, так и для текста, визуальное воздействие которого трудно определить. Я не знаю теории восприятия искусства / зрения, поэтому прошу прощения за (пере) изобретение этой метрики.

Что касается нахождения визуального воздействия текста, я считаю, что метрики, которые вступают в игру:
- цвет
- размер шрифта
- сила шрифта (обычный, жирный)
- сглаживание (если включено)
- с засечками (шрифт с засечками кажется более "твердым", чем шрифт с засечками)
Позвольте мне заявить о моей проблеме: "учитывая растровое изображение фрагмента текста на сколь угодно большом белом холсте, вернуть числовую метрику, которая соизмерима с тем, как человеческий глаз будет оценивать ее воздействие".
Я просто выпускник CS, который немного увлекался обработкой изображений, не занимаясь искусством или дизайном. Я осознаю, что сложно программно измерить что-то субъективное.