Сократите использование памяти программой на Haskell
У меня есть следующая программа на Haskell:
processDate :: String -> IO ()
processDate date = do
...
let newFlattenedPropertiesWithPrice = filter (notYetInserted date existingProperties) flattenedPropertiesWithPrice
geocodedProperties <- propertiesWithGeocoding newFlattenedPropertiesWithPrice
propertiesWithGeocoding :: [ParsedProperty] -> IO [(ParsedProperty, Maybe LatLng)]
propertiesWithGeocoding properties = do
let addresses = fmap location properties
let batchAddresses = chunksOf 100 addresses
batchGeocodedLocations <- mapM geocodeAddresses batchAddresses
let geocodedLocations = fromJust $ concat <$> sequence batchGeocodedLocations
return (zip properties geocodedLocations)
geocodeAddresses :: [String] -> IO (Maybe [Maybe LatLng])
geocodeAddresses addresses = do
mapQuestKey <- getEnv "MAP_QUEST_KEY"
geocodeResponse <- openURL $ mapQuestUrl mapQuestKey addresses
return $ geocodeResponseToResults geocodeResponse
geocodeResponseToResults :: String -> Maybe [Maybe LatLng]
geocodeResponseToResults inputResponse =
latLangs
where
decodedResponse :: Maybe GeocodingResponse
decodedResponse = decodeGeocodingResponse inputResponse
latLangs = fmap (fmap geocodingResultToLatLng . results) decodedResponse
decodeGeocodingResponse :: String -> Maybe GeocodingResponse
decodeGeocodingResponse inputResponse = Data.Aeson.decode (fromString inputResponse) :: Maybe GeocodingResponse
Он читает список свойств (домов и квартир) из HTML-файлов, анализирует их, геокодирует адреса и сохраняет результаты в sqlite db.
Все работает отлично, за исключением очень высокого использования памяти (около 800M).
Закомментировав код, я определил проблему как шаг геокодирования.
Одновременно я отправляю 100 адресов API MapQuest ( https://developer.mapquest.com/documentation/geocoding-api/batch/get/).
Ответ на 100 адресов довольно массивный, поэтому он может быть одним из виновников, но 800M? Я чувствую, что это относится ко всем результатам до конца, который приводит к такому высокому использованию памяти.
После комментирования геокодирование часть использования памяти программы составляет около 30 млн., Что нормально.
Вы можете получить полную версию, которая воспроизводит проблему здесь: https://github.com/Leonti/haskell-memory-so

Я довольно новичок в Хаскеле, поэтому не уверен, как мне его оптимизировать.
Есть идеи?
Ура!
1 ответ
Возможно, стоит отметить, что это оказалось простой проблемой потоковой передачи, возникающей в результате использования mapM а также sequence, который с replicateM а также traverse и другие вещи, которые заставляют вас "извлекать список из IO", всегда вызывают беспокойство накопления. Таким образом, небольшой обход потоковой библиотеки был необходим. Так что в репо нужно было просто заменить
processDate :: String -> IO ()
processDate date = do
allFiles <- listFiles date
allProperties <- mapM fileToProperties allFiles
let flattenedPropertiesWithPrice = filter hasPrice $ concat allProperties
geocodedProperties <- propertiesWithGeocoding flattenedPropertiesWithPrice
print geocodedProperties
propertiesWithGeocoding :: [ParsedProperty] -> IO [(ParsedProperty, Maybe LatLng)]
propertiesWithGeocoding properties = do
let batchProperties = chunksOf 100 properties
batchGeocodedLocations <- mapM geocodeAddresses batchProperties
let geocodedLocations = fromJust $ concat <$> sequence batchGeocodedLocations
return geocodedLocations
с чем-то вроде этого
import Streaming
import qualified Streaming.Prelude as S
processDate :: String -> IO ()
processDate date = do
allFiles <- listFiles date -- we accept an unstreamed list
S.print $ propertiesWithGeocoding -- this was the main pain point see below
$ S.filter hasPrice
$ S.concat
$ S.mapM fileToProperties -- this mapM doesn't accumulate
$ S.each allFiles -- the list is converted to a stream
propertiesWithGeocoding
:: Stream (Of ParsedProperty) IO r
-> Stream (Of (ParsedProperty, Maybe LatLng)) IO r
propertiesWithGeocoding properties =
S.concat $ S.concat
$ S.mapM geocodeAddresses -- this mapM doesn't accumulate results from mapquest
$ S.mapped S.toList -- convert segments to haskell lists
$ chunksOf 100 properties -- this is the streaming `chunksOf`
-- concat here flattens a stream of lists of as into a stream of as
-- and a stream of maybe as into a stream of as
Тогда использование памяти выглядит так, каждый пик, соответствующий поездке в Mapquest, быстро сопровождается небольшой обработкой и печатью, после чего ghc забывает все об этом и идет дальше:
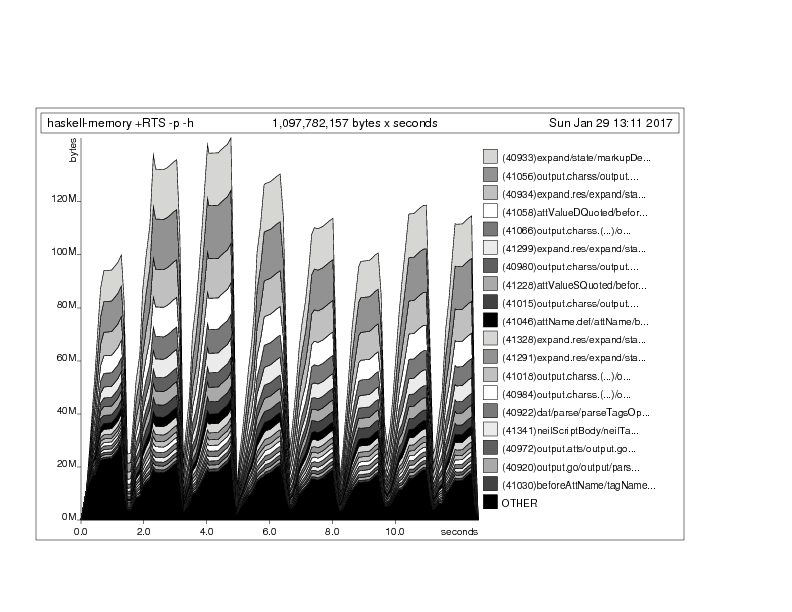
Конечно, это можно сделать с pipes или же conduit, Но здесь нам просто нужно немного простого mapM / sequence/ traverse / replicateM избегание и streaming возможно, проще всего для такого быстрого локального рефакторинга. Обратите внимание, что этот список довольно короткий, поэтому мысль "но короткие списки здорово mapM/traverse/ etc! "может показаться ложным. Почему бы просто не избавиться от них? Всякий раз, когда вы собираетесь написать список mapM f это хорошая идея для рассмотрения S.mapM f . S.each (или трубопровод или эквивалент труб) . Теперь у вас будет поток и вы сможете восстановить список с помощью S.toList или эквивалент, но вполне вероятно, что, как и в этом случае, вы обнаружите, что вам не нужен расширенный накопленный список, но вы можете, например, использовать какой-либо потоковый процесс, например, печать в файл или стандартный вывод или запись данных в базу данных, после того, как список, как манипуляции необходимы (здесь мы используем, например, потоковое filter а также concat чтобы сгладить потоковые списки и как своего рода catMaybe) .