Массивные вставки из одной большой таблицы в другие связанные таблицы
В:
В настоящее время я собрал все данные в одну таблицу 'Bigtable' PostgreSQL (там около 1,2 млн строк). Теперь мне нужно разделить дизайн на отдельные таблицы, которые все зависят от Bigtable. Некоторые из таблиц могут иметь подтаблицы. Модель очень похожа на снежинку.
Проблема:
Что будет лучшим вариантом для вставки данных в таблицы? Я думал сделать вставку с функциями, написанными на "SQL" или PLgSQL. Но проблема все еще с автоматически генерируемыми идентификаторами.
Также, если вы знаете, какие инструменты могут облегчить решение этой проблемы, тогда пишите!
//Изменить я добавил пример, это не реальный случай только для иллюстрации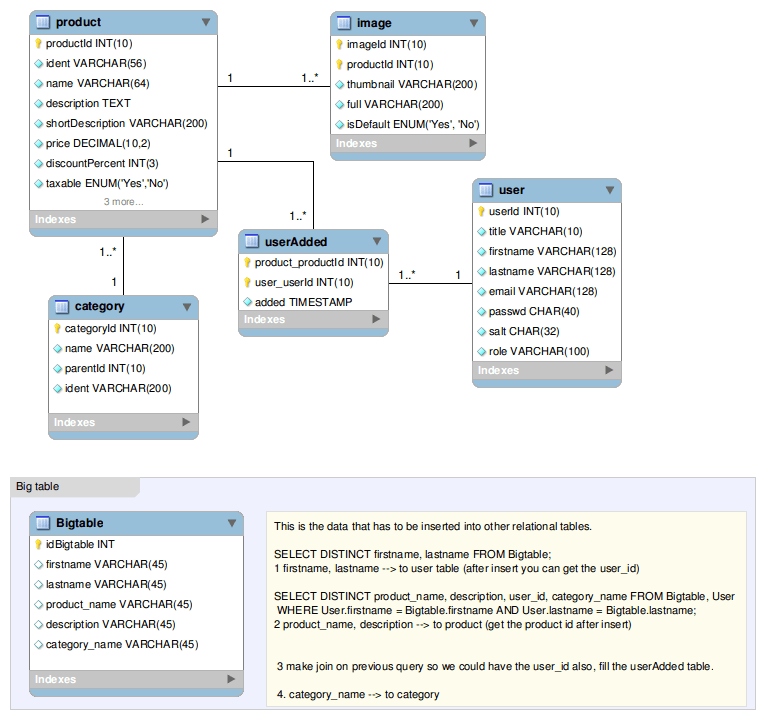
3 ответа
1,2 м рядов не так уж много. Лучший инструмент - это скрипт sql, выполненный из консоли "psql". Если у вас есть более новая версия Pg, вы можете использовать встроенные функции (оператор DO), когда это необходимо. Но, вероятно, самая полезная команда - это оператор INSERT INTO SELECT.
-- file conversion.sql
DROP TABLE IF EXISTS f1 CASCADE;
CREATE TABLE f1(a int, b int);
INSERT INTO f1
SELECT x1, y1
FROM data
WHERE x1 = 10;
...
-- end file
psql mydb -f conversion.sql
Если я понимаю ваш вопрос, вы можете использовать функцию psql следующим образом:
CREATE OR REPLACE FUNCTION migration() RETURNS integer AS
$BODY$
DECLARE
currentProductId INTEGER;
currentUserId INTEGER;
currentReg RECORD;
BEGIN
FOR currentReg IN
SELECT * FROM bigtable
LOOP
-- Product
SELECT productid INTO currentProductId
FROM product
WHERE name = currentReg.product_name;
IF currentProductId IS NULL THEN
EXECUTE 'INSERT INTO product (name) VALUES (''' || currentReg.product_name || ''') RETURNING productid'
INTO currentProductId;
END IF;
-- User
SELECT userid INTO currentUserId
FROM user
WHERE first_name = currentReg.first_name and last_name = currentReg.last_name;
IF currentUserId IS NULL THEN
EXECUTE 'INSERT INTO user (first_name, last_name) VALUES (''' || currentReg.first_name || ''', ''' || currentReg.last_name || ''') RETURNING userid'
INTO currentUserId;
-- Insert into userAdded too with: currentUserId and currentProductId
[...]
END IF;
-- Rest of tables
[...]
END LOOP;
RETURN 1;
END;
$BODY$
LANGUAGE plpgsql;
select * from migration();
В этом случае предполагается, что каждая таблица выполняет свою собственную последовательность первичных ключей, и я уменьшил количество полей в таблицах для упрощения. Я надеюсь, что вы были полезны.
Нет необходимости использовать функцию для этого (если я не понял вашу проблему)
Если все ваши столбцы идентифицированы как serial столбец (т.е. они автоматически генерируют значения), то это можно сделать с помощью простых операторов INSERT. Это предполагает, что все целевые таблицы пусты.
INSERT INTO users (firstname, lastname)
SELECT DISTINCT firstname, lastname
FROM bigtable;
INSERT INTO category (name)
SELECT DISTINCT category_name
FROM bigtable;
-- the following assumes a column categoryid in the product table
-- which is not visible from your screenshot
INSERT INTO product (product_name, description, categoryid)
SELECT DISTINCT b.product_name, b.description, c.categoryid
FROM bigtable b
JOIN category c ON c.category_name = b.category_name;
INSERT INTO product_added (product_productid, user_userid)
SELECT p.productid, u.userid
FROM bigtable b
JOIN product p ON p.product_name = b.product_name
JOIN users u ON u.firstname = b.firstname AND u.lastname = b.lastname