Работа с двумя факторами гранулярности - размерная модель
У меня есть вопрос о создании размерной модели и работе с различными уровнями детализации.
Я хотел бы знать, какой из этих двух подходов будет лучшим и почему. Или, если есть другой подход, который был бы еще лучше.
Сценарий, который я использую, прост: у меня есть 2 измерения, Регион и Клиент и 1 факт, Продажи.
Это две таблицы измерений, одна для региона и другая для клиента с таблицей фактов, содержащей продажи, выглядящие так:
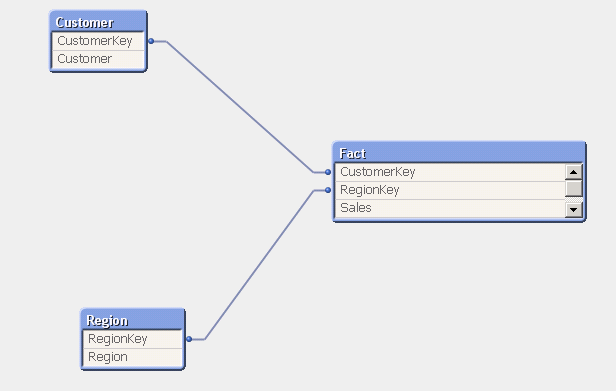
Теперь я хочу агрегировать продажи по регионам. Но я не уверен, что это лучший подход.
Должен ли я агрегировать продажи по регионам, а затем объединить данные в таблицу фактов, чтобы модель выглядела следующим образом:
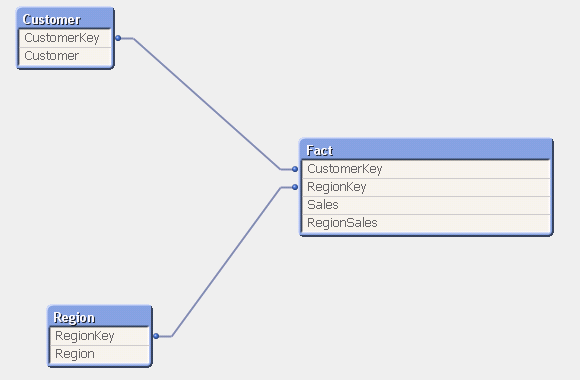
Или я должен создать новую таблицу, которая содержит агрегированные значения с ключом, присоединяющимся к таблице измерений фактов и регионов, которая будет выглядеть следующим образом:
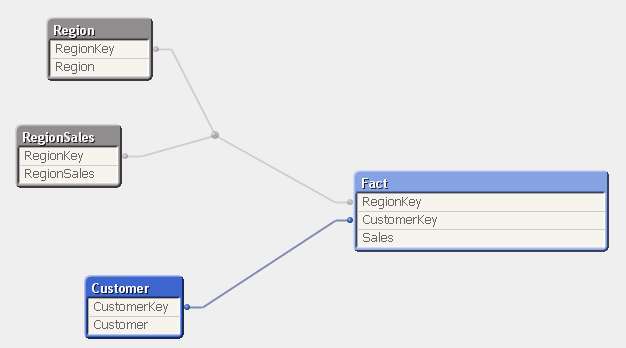
Или есть другой подход, который побеждает эти два?
Ваша мудрость и вклад приветствуются.
Спасибо
1 ответ
Ваша первая диаграмма позволяет вам запрашивать факт для агрегирования по регионам, но я предполагаю, что вы хотите предварительно агрегировать результаты на уровне региона по соображениям производительности.
Стандартный метод для агрегированных фактов заключается в создании отдельной таблицы фактов на нужном уровне, которая дополняет основной факт. В идеале у вас должен быть инструмент для запросов, который знает, когда вы выиграете от использования агрегированного факта.
Агрегированный факт будет содержать только RegionKey и Sales (т.е. внешний ключ к измерению региона). Это похоже на ваше второе решение, но нет никакой связи с фактом, из которого были собраны цифры. В этом нет необходимости: вы уже можете видеть, какие подробные факты составляют совокупности из самого основного факта.
Ваше первое решение "смешивает зерно" факта и не рекомендуется. Таблицы фактов должны иметь четко сформулированное зерно, чтобы вы знали, что представляет каждая строка, например, измерение продажи клиенту. Если вы включили агрегированную цифру, это не относится к продажам одного покупателя (или только одного покупателя), и вы можете получить двойной счет, если не понимаете этого при запросе. Фактически, в идеале меры должны быть "аддитивными" во всех измерениях: вы не можете суммировать агрегированную цифру RegionSales с чем-либо, кроме региона.
Однако функции современных инструментов BI и систем баз данных имеют характеристики производительности, которые значительно снижают потребность в совокупности фактов. Столбчатые базы данных (или индексы columnstore в реляционных базах данных, таких как SQL Server) в реляционных моделях данных, таких как в Power BI, способствуют быстрому выполнению такого рода запросов без специальных таблиц агрегирования. Это важно, потому что может быть трудно поддерживать ваши сводные таблицы в актуальном состоянии и в соответствии с вашими фактами.