При разборе PDF получить один и тот же текст дважды на разных страницах
У меня есть файл PDF, который содержит 2 страницы. Когда я анализирую это с моим анализатором, в Ojective-C, я имею следующую ситуацию.
Для первой страницы все в порядке, у меня есть текст, который я должен был иметь (который я визуально вижу в программах чтения PDF, таких как Preview, Adobe reader ...). Для второй страницы у меня есть текст, который я вижу на второй странице, плюс часть текста с первой страницы, которой нет на второй странице.
Я пытался с другими парсерами: pdftotext (xpdf) им удалось получить правильный результат. Pdfminer (на python) https://pypi.python.org/pypi/pdfminer/, я получил тот же результат, что и я. Часть текста с первой страницы извлекается дважды.
Мой вопрос: как это может произойти? Вы когда-нибудь видели эту ситуацию? Если текст действительно присутствует на второй странице, почему бы его не показать читателям PDF? Есть ли у вас мысли по этому поводу?
1 ответ
Я проверил ваш файл через Acrobat (используя "Изучить документ"), и он говорит мне, что в нем есть какой-то скрытый текст. Посмотрите на следующий снимок экрана:
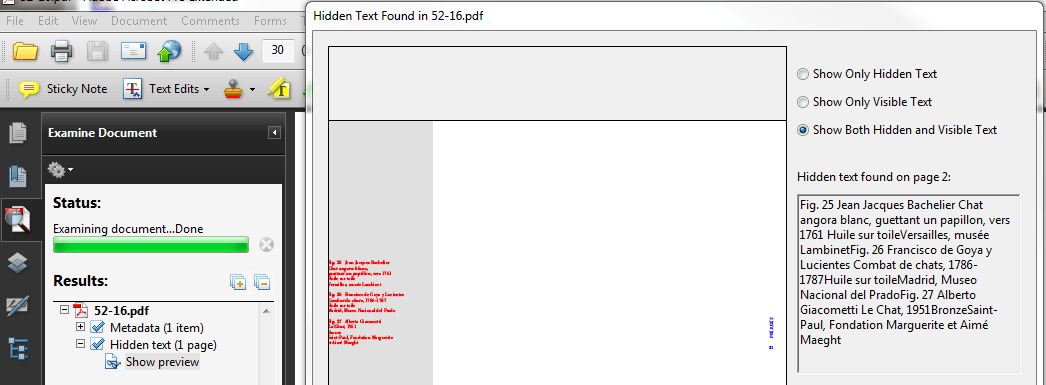
Текст красного цвета на снимке экрана отмечает, что скрыто. Как указывает mkl, он присутствует за пределами MediaBox, что делает его невидимым при просмотре документа в средстве просмотра PDF. Это не значит, что текст там. Если вы заглянете внутрь потока контента (что делают парсеры), вы все равно найдете его.
Ваш парсер должен отказаться от всего, что находится за пределами MediaBox. Обычно есть возможность сделать это. Я знаю, что есть один в iText; Я не знаю о других парсерах.