Удаление строки DataFrame в Pandas на основе значения столбца
У меня есть следующий DataFrame:
daysago line_race rating rw wrating
line_date
2007-03-31 62 11 56 1.000000 56.000000
2007-03-10 83 11 67 1.000000 67.000000
2007-02-10 111 9 66 1.000000 66.000000
2007-01-13 139 10 83 0.880678 73.096278
2006-12-23 160 10 88 0.793033 69.786942
2006-11-09 204 9 52 0.636655 33.106077
2006-10-22 222 8 66 0.581946 38.408408
2006-09-29 245 9 70 0.518825 36.317752
2006-09-16 258 11 68 0.486226 33.063381
2006-08-30 275 8 72 0.446667 32.160051
2006-02-11 475 5 65 0.164591 10.698423
2006-01-13 504 0 70 0.142409 9.968634
2006-01-02 515 0 64 0.134800 8.627219
2005-12-06 542 0 70 0.117803 8.246238
2005-11-29 549 0 70 0.113758 7.963072
2005-11-22 556 0 -1 0.109852 -0.109852
2005-11-01 577 0 -1 0.098919 -0.098919
2005-10-20 589 0 -1 0.093168 -0.093168
2005-09-27 612 0 -1 0.083063 -0.083063
2005-09-07 632 0 -1 0.075171 -0.075171
2005-06-12 719 0 69 0.048690 3.359623
2005-05-29 733 0 -1 0.045404 -0.045404
2005-05-02 760 0 -1 0.039679 -0.039679
2005-04-02 790 0 -1 0.034160 -0.034160
2005-03-13 810 0 -1 0.030915 -0.030915
2004-11-09 934 0 -1 0.016647 -0.016647
Мне нужно удалить строки, где line_race равно 0, Какой самый эффективный способ сделать это?
19 ответов
Если я правильно понимаю, это должно быть так просто:
df = df[df.line_race != 0]
Но для любых будущих прохожих вы могли бы упомянуть, что df = df[df.line_race != 0] ничего не делает при попытке фильтрации None/ пропущенные значения.
Работает:
df = df[df.line_race != 0]
Ничего не делает
df = df[df.line_race != None]
Работает:
df = df[df.line_race.notnull()]
Просто чтобы добавить другое решение, особенно полезное, если вы используете новые оценщики панд, другие решения заменят оригинальные панды и потеряют оценщиков
df.drop(df.loc[df['line_race']==0].index, inplace=True)
В случае нескольких значений и str dtype
Я использовал следующее, чтобы отфильтровать заданные значения в столбце:
def filter_rows_by_values(df, col, values):
return df[df[col].isin(values) == False]
Пример:
В DataFrame я хочу удалить строки, которые имеют значения «b» и «c» в столбце «str»
df = pd.DataFrame({"str": ["a","a","a","a","b","b","c"], "other": [1,2,3,4,5,6,7]})
df
str other
0 a 1
1 a 2
2 a 3
3 a 4
4 b 5
5 b 6
6 c 7
filter_rows_by_values(d,"str", ["b","c"])
str other
0 a 1
1 a 2
2 a 3
3 a 4
Если вы хотите удалить строки на основе нескольких значений столбца, вы можете использовать:
df[(df.line_race != 0) & (df.line_race != 10)]
Чтобы удалить все строки со значениями 0 и 10 для line_race.
Хотя предыдущий ответ почти аналогичен тому, что я собираюсь сделать, но использование метода индекса не требует использования другого метода индексации.loc(). Это можно сделать аналогичным, но точным образом, как
df.drop(df.index[df['line_race'] == 0], inplace = True)
Лучший способ сделать это с помощью логического маскирования:
In [56]: df
Out[56]:
line_date daysago line_race rating raw wrating
0 2007-03-31 62 11 56 1.000 56.000
1 2007-03-10 83 11 67 1.000 67.000
2 2007-02-10 111 9 66 1.000 66.000
3 2007-01-13 139 10 83 0.881 73.096
4 2006-12-23 160 10 88 0.793 69.787
5 2006-11-09 204 9 52 0.637 33.106
6 2006-10-22 222 8 66 0.582 38.408
7 2006-09-29 245 9 70 0.519 36.318
8 2006-09-16 258 11 68 0.486 33.063
9 2006-08-30 275 8 72 0.447 32.160
10 2006-02-11 475 5 65 0.165 10.698
11 2006-01-13 504 0 70 0.142 9.969
12 2006-01-02 515 0 64 0.135 8.627
13 2005-12-06 542 0 70 0.118 8.246
14 2005-11-29 549 0 70 0.114 7.963
15 2005-11-22 556 0 -1 0.110 -0.110
16 2005-11-01 577 0 -1 0.099 -0.099
17 2005-10-20 589 0 -1 0.093 -0.093
18 2005-09-27 612 0 -1 0.083 -0.083
19 2005-09-07 632 0 -1 0.075 -0.075
20 2005-06-12 719 0 69 0.049 3.360
21 2005-05-29 733 0 -1 0.045 -0.045
22 2005-05-02 760 0 -1 0.040 -0.040
23 2005-04-02 790 0 -1 0.034 -0.034
24 2005-03-13 810 0 -1 0.031 -0.031
25 2004-11-09 934 0 -1 0.017 -0.017
In [57]: df[df.line_race != 0]
Out[57]:
line_date daysago line_race rating raw wrating
0 2007-03-31 62 11 56 1.000 56.000
1 2007-03-10 83 11 67 1.000 67.000
2 2007-02-10 111 9 66 1.000 66.000
3 2007-01-13 139 10 83 0.881 73.096
4 2006-12-23 160 10 88 0.793 69.787
5 2006-11-09 204 9 52 0.637 33.106
6 2006-10-22 222 8 66 0.582 38.408
7 2006-09-29 245 9 70 0.519 36.318
8 2006-09-16 258 11 68 0.486 33.063
9 2006-08-30 275 8 72 0.447 32.160
10 2006-02-11 475 5 65 0.165 10.698
ОБНОВЛЕНИЕ: Теперь, когда панды 0.13 вышли, еще один способ сделать это df.query('line_race != 0'),
Данный ответ, тем не менее, является правильным, так как кто-то выше сказал, что вы можете использовать df.query('line_race != 0') который в зависимости от вашей проблемы намного быстрее. Настоятельно рекомендую.
Существуют различные способы достижения этого. Ниже будут оставлены различные варианты, которые можно использовать в зависимости от специфики своего варианта использования.
Можно будет считать, что кадр данных OP хранится в переменнойdf.
Опция 1
Для случая OP, учитывая, что единственный столбец со значениями0этоline_race, следующее сделает работу
df_new = df[df != 0].dropna()
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Однако, поскольку это не всегда так, рекомендуется проверить следующие параметры, в которых будет указано имя столбца.
Вариант 2
подход tshauck оказывается лучше, чем вариант 1, потому что можно указать столбец. Однако существуют дополнительные варианты в зависимости от того, как нужно обращаться к столбцу:
Например, используя позицию в кадре данных
df_new = df[df[df.columns[2]] != 0]
Или явно указав столбец следующим образом
df_new = df[df['line_race'] != 0]
Можно также использовать тот же логин, но с помощью пользовательской лямбда-функции, такой как
df_new = df[df.apply(lambda x: x['line_race'] != 0, axis=1)]
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Вариант 3
С использованием pandas.Series.mapи пользовательская лямбда-функция
df_new = df['line_race'].map(lambda x: x != 0)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Вариант 4
С использованиемследующее
df_new = df.drop(df[df['line_race'] == 0].index)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Вариант 5
С использованиемследующее
df_new = df.query('line_race != 0')
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Вариант 6
С использованием pandas.DataFrame.dropи pandas.DataFrame.queryследующее
df_new = df.drop(df.query('line_race == 0').index)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Вариант 7
Если у вас нет твердого мнения о выходе, можно использовать векторизованный подход с numpy.select
df_new = np.select([df != 0], [df], default=np.nan)
[Out]:
[['2007-03-31' 62 11.0 56 1.0 56.0]
['2007-03-10' 83 11.0 67 1.0 67.0]
['2007-02-10' 111 9.0 66 1.0 66.0]
['2007-01-13' 139 10.0 83 0.880678 73.096278]
['2006-12-23' 160 10.0 88 0.793033 69.786942]
['2006-11-09' 204 9.0 52 0.636655 33.106077]
['2006-10-22' 222 8.0 66 0.581946 38.408408]
['2006-09-29' 245 9.0 70 0.518825 36.317752]
['2006-09-16' 258 11.0 68 0.486226 33.063381]
['2006-08-30' 275 8.0 72 0.446667 32.160051]
['2006-02-11' 475 5.0 65 0.164591 10.698423]]
Это также может быть преобразовано в фрейм данных с
df_new = pd.DataFrame(df_new, columns=df.columns)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.0 56.0
1 2007-03-10 83 11.0 67 1.0 67.0
2 2007-02-10 111 9.0 66 1.0 66.0
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Что касается наиболее эффективного решения, это будет зависеть от того, как вы хотите измерить эффективность. Предполагая, что кто-то хочет измерить время выполнения, один из способов сделать это — использовать time.perf_counter().
Если измерить время выполнения всех вышеперечисленных вариантов, то получится следующее
method time
0 Option 1 0.00000110000837594271
1 Option 2.1 0.00000139995245262980
2 Option 2.2 0.00000369996996596456
3 Option 2.3 0.00000160001218318939
4 Option 3 0.00000110000837594271
5 Option 4 0.00000120000913739204
6 Option 5 0.00000140001066029072
7 Option 6 0.00000159995397552848
8 Option 7 0.00000150001142174006
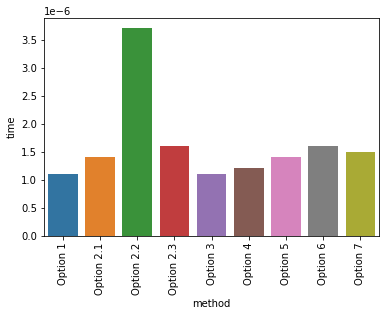
Однако это может измениться в зависимости от используемого фрейма данных, требований (например, аппаратного обеспечения) и многого другого.
Примечания:
Существуют различные предложения по использованию
inplace=True. Предлагаю прочитать это: /questions/22204233/python-pandas-ponimanie-na-meste-true/55271663#55271663Есть также люди с твердым мнением о
.apply(). Предлагаю прочитать это: Когда я должен (не) хотеть использовать pandas apply() в моем коде?Если у кого-то есть пропущенные значения, можно также рассмотреть
pandas.DataFrame.dropna. Используя вариант 2, это будет что-то вродеdf = df[df['line_race'] != 0].dropna()Существуют дополнительные способы измерения времени выполнения, поэтому я бы порекомендовал этот поток: Как получить время выполнения программы Python?
Один из эффективных и привлекательных способов - использовать
eq() метод:
df[~df.line_race.eq(0)]
Еще один способ сделать это. Возможно, не самый эффективный способ, поскольку код выглядит немного сложнее, чем код, упомянутый в других ответах, но все же альтернативный способ сделать то же самое.
df = df.drop(df[df['line_race']==0].index)
Добавляем еще один способ сделать это.
df = df.query("line_race!=0")
Я скомпилировал и запустил свой код. Это точный код. Вы можете попробовать это самостоятельно.
data = pd.read_excel('file.xlsx')
Если у вас есть специальный символ или пробел в имени столбца, вы можете написать его в '' как в данном коде:
data = data[data['expire/t'].notnull()]
print (date)
Если есть только одно строковое имя столбца без пробелов или специальных символов, вы можете получить к нему прямой доступ.
data = data[data.expire ! = 0]
print (date)
предоставлено так много вариантов (или, может быть, я не обратил на это особого внимания, извините, если это так), но никто не упомянул об этом: мы можем использовать эту нотацию в пандах: ~ (это дает нам обратное условие)
df = df[~df["line_race"] == 0]
На всякий случай нужно удалить строку, но значение может быть в разных столбцах. В моем случае я использовал проценты, поэтому я хотел удалить строки, которые имеют значение 1 в любом столбце, поскольку это означает, что это 100%
for x in df:
df.drop(df.loc[df[x]==1].index, inplace=True)
Не оптимально, если в вашем df слишком много столбцов.
Просто добавляем еще один способ расширения DataFrame по всем столбцам:
for column in df.columns:
df = df[df[column]!=0]
Пример:
def z_score(data,count):
threshold=3
for column in data.columns:
mean = np.mean(data[column])
std = np.std(data[column])
for i in data[column]:
zscore = (i-mean)/std
if(np.abs(zscore)>threshold):
count=count+1
data = data[data[column]!=i]
return data,count
Если вам нужно удалить строки на основе значений индекса, логическое индексирование в верхнем ответе также может быть адаптировано. Например, в следующем коде удаляются строки с индексом от 3 до 7.
df = pd.DataFrame({'A': range(10), 'B': range(50,60)})
x = df[(df.index < 3) | (df.index > 7)]
# or equivalently
y = df[~((df.index >= 3) & (df.index <= 7))]
# or using query
z = df.query("~(3 <= index <= 7)")
# if the index has a name (as in the OP), use the name
# to select rows in 2007:
df.query("line_date.dt.year == 2007")
Как уже отмечали другие, это очень читаемая функция, которая идеально подходит для этой задачи. Фактически, для больших фреймов данных это самый быстрый метод для этой задачи (результаты тестов см. в этом ответе ).
Некоторые распространенные вопросы сquery():
- Для имен столбцов с пробелом используйте обратные кавычки.
df = pd.DataFrame({'col A': [0, 1, 2, 0], 'col B': ['a', 'b', 'cd', 'e']}) # wrap a column name with space by backticks x = df.query('`col A` != 0') - Чтобы обратиться к переменным в локальной среде, добавьте к ним префикс
@.to_exclude = [0, 2] y = df.query('`col A` != @to_exclude') - Также можно вызывать методы Series.
# remove rows where the length of the string in column B is not 1 z = df.query("`col B`.str.len() == 1")
Это не имеет большого значения для простого примера, подобного этому, но для сложной логики я предпочитаю использоватьdrop()при удалении строк, потому что это более просто, чем использование обратной логики. Например, удалите строки, в которыхA=1 AND (B=2 OR C=3).
Вот масштабируемый синтаксис, который прост для понимания и может обрабатывать сложную логику:
df.drop( df.query(" `line_race` == 0 ").index)
Вы можете попробовать использовать это:
df.drop(df[df.line_race != 0].index, inplace = True)
.