Какова цель фазы тасования и сортировки в редукторе в Map Reduce Programming?
В программировании Map Reduce фаза сокращения имеет перемешивание, сортировку и уменьшение в качестве своих частей. Сортировка является дорогостоящим делом.
Какова цель фазы тасования и сортировки в редукторе в Map Reduce Programming?
11 ответов
Прежде всего shuffling это процесс передачи данных из преобразователей в редукторы, поэтому я думаю, что это необходимо для редукторов, так как в противном случае они не могли бы иметь никакого ввода (или ввода от каждого преобразователя). Перемешивание может начаться еще до окончания фазы карты, чтобы сэкономить время. Вот почему вы можете видеть статус уменьшения больше 0% (но меньше 33%), когда статус карты еще не равен 100%.
Sorting экономит время для редуктора, помогая легко определить, когда должна начинаться новая задача редуцирования. Он просто запускает новую задачу сокращения, когда, проще говоря, следующий ключ в отсортированных входных данных отличается от предыдущего. Каждая задача сокращения занимает список пар "ключ-значение", но она должна вызывать метод redu (), который принимает входные данные из списка ключей (значение), поэтому он должен группировать значения по ключу. Это легко сделать, если входные данные предварительно отсортированы (локально) на этапе отображения и просто отсортированы слиянием на этапе сокращения (поскольку преобразователи получают данные от многих картографов).
PartitioningТо, что вы упомянули в одном из ответов, это другой процесс. Он определяет, в какой редукторе будет отправлена пара (ключ, значение), вывод фазы карты. Partitioner по умолчанию использует хэширование ключей для их распределения по задачам сокращения, но вы можете переопределить его и использовать свой собственный Partitioner.
Отличным источником информации для этих шагов является данное руководство Yahoo.
Хорошим графическим представлением этого является следующее (shuffle называется "copy" на этом рисунке):
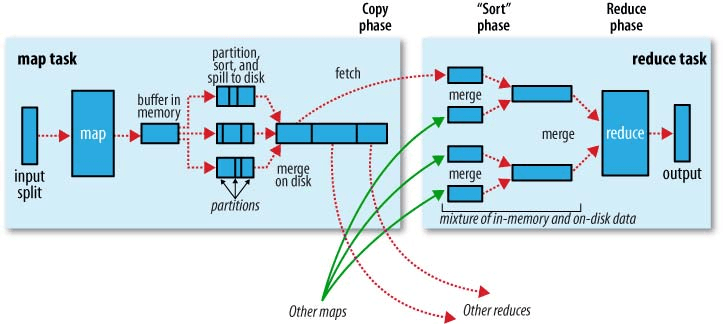
Обратите внимание, что shuffling а также sorting не выполняются вообще, если вы указываете нулевые редукторы (setNumReduceTasks(0)). Затем задание MapReduce останавливается на фазе карты, а фаза карты не включает никакой сортировки (так что даже фаза карты быстрее).
ОБНОВЛЕНИЕ: Поскольку вы ищете что-то более официальное, вы также можете прочитать книгу Тома Уайта "Hadoop: Полное руководство". Вот интересная часть для вашего вопроса.
Том Уайт был коммиттером Apache Hadoop с февраля 2007 года и является членом Apache Software Foundation, так что я думаю, что он довольно надежный и официальный...
Давайте вернемся к ключевым этапам программы Mapreduce.
Фаза карты выполняется картографами. Мапперы работают на несортированных парах ключ / значение. Каждый преобразователь генерирует ноль, одну или несколько выходных пар ключ / значение для каждой пары входной ключ / значение.
Фаза объединения выполняется объединителями. Объединитель должен объединять пары ключ / значение с одним и тем же ключом. Каждый объединитель может работать ноль, один или несколько раз.
Фаза перемешивания и сортировки выполняется структурой. Данные всех картографов сгруппированы по ключу, распределены по редукторам и отсортированы по ключу. Каждый редуктор получает все значения, связанные с одним и тем же ключом. Программист может предоставить пользовательские функции сравнения для сортировки и разделитель для разделения данных.
Секционер решает, какой редуктор получит конкретную пару ключ-значение.
Редуктор получает отсортированные пары ключ /[список значений], отсортированные по ключу. Список значений содержит все значения с одним и тем же ключом, созданным картографами. Каждый редуктор испускает ноль, одну или несколько пар ключ / значение для каждой пары ключ / значение.
Взгляните на эту статью javacodegeeks Марии Юрковичовой и статью mssqltips Datta для лучшего понимания
Ниже изображение из статьи safaribooksonline
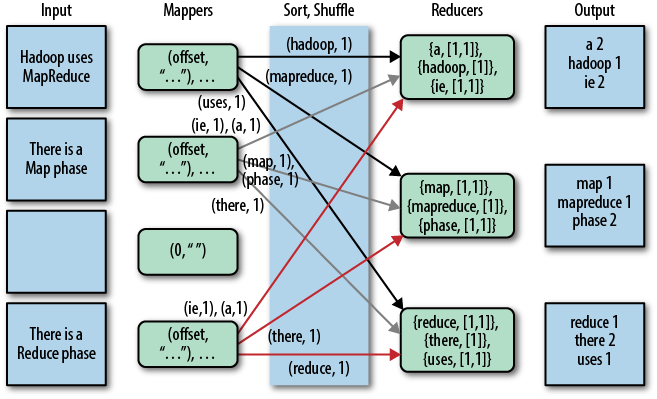
Я думал о том, чтобы просто добавить некоторые моменты, отсутствующие в ответах выше Эта диаграмма, взятая отсюда, ясно показывает, что на самом деле происходит.

Если я еще раз укажу реальную цель
Разделение: улучшает параллельную обработку, распределяя нагрузку обработки между различными узлами (Mappers), что позволит сэкономить общее время обработки.
Объединить: Сокращает вывод каждого Mapper. Это сэкономит время, затрачиваемое на перемещение данных с одного узла на другой.
Sort (Shuffle & Sort): облегчает во время выполнения планировать (порождать / запускать) новые редукторы, где при прохождении списка отсортированных элементов всякий раз, когда текущий ключ отличается от предыдущего, он может порождать новый редуктор,
Некоторые требования к обработке данных вообще не нуждаются в сортировке. Syncsort сделал сортировку в Hadoop подключаемой. Вот хороший блог от них по сортировке. Процесс перемещения данных из картографов в редукторы называется тасованием, обратитесь к этой статье для получения дополнительной информации об этом.
Перестановка - это процесс, при котором промежуточные данные от картографов передаются в 0,1 или более редукторов. Каждый редуктор получает 1 или более ключей и связанных с ними значений в зависимости от количества редукторов (для сбалансированной нагрузки). Далее значения, связанные с каждым ключом, сортируются локально.
Я всегда предполагал, что это было необходимо, так как выходной сигнал от преобразователя является входом для редуктора, поэтому он был отсортирован по пространству клавиш, а затем разбит на сегменты для каждого входа редуктора. Вы хотите, чтобы все одинаковые значения ключа оказались в одном сегменте, идущем к редуктору, чтобы они сводились вместе. Нет смысла отправлять K1,V2 и K1,V4 в разные редукторы, так как они должны быть вместе, чтобы быть уменьшенными.
Пытался объяснить это как можно проще
Из-за своего размера распределенный набор данных обычно хранится в разделах, каждый из которых содержит группу строк. Это также улучшает параллелизм для таких операций, как карта или фильтр. Перетасовка любая операция над набором данных , что требует перераспределения данных по его разделам. Примеры включают сортировку и группировку по ключу.
Распространенный метод перетасовки большого набора данных - разделить выполнение на карту и этап сокращения. Затем данные перетасовываются между картой и задачами сокращения. Например, предположим, что мы хотим отсортировать набор данных с 4 разделами, где каждый раздел представляет собой группу из 4 блоков. Цель состоит в том, чтобы создать другой набор данных с 4 разделами, но на этот раз отсортированный по ключу.

Например, в операции сортировки каждый квадрат представляет собой отсортированный подраздел с ключами в отдельном диапазоне. Каждая задача сокращения затем объединяет-сортирует подразделения одного оттенка. На приведенной выше диаграмме показан этот процесс. Первоначально несортированный набор данных группируется по цвету (синий, фиолетовый, зеленый, оранжевый). Цель перемешивания - перегруппировать блоки по оттенку (от светлого к темному). Эта перегруппировка требует всеобщего взаимодействия: каждая задача карты (цветной кружок) производит один промежуточный результат (квадрат) для каждого оттенка, и эти промежуточные результаты перетасовываются в соответствующую задачу уменьшения (серый кружок).
Текст и изображение в основном были взяты отсюда.
Что ж, в Mapreduce есть две важные фразы, называемые Mapper и Reducer, которые слишком важны, но Reducer является обязательным. В некоторых программах редукторы не обязательны. Теперь перейдем к вашему вопросу. Перемешивание и сортировка - две важные операции в Mapreduce. Первая структура Hadoop берет структурированные / неструктурированные данные и разделяет данные на Key, Value.
Теперь программа Mapper разделяет и организует данные в ключи и значения для обработки. Сгенерируйте значения ключа 2 и значения 2. Эти значения следует обработать и переставить в правильном порядке, чтобы получить желаемое решение. Теперь эта перестановка и сортировка выполняются в вашей локальной системе (Framework позаботится об этом) и обрабатывают в локальной системе после того, как Framework Framework очистит данные в локальной системе. Хорошо
Здесь мы используем комбинатор и раздел также для оптимизации этого процесса перемешивания и сортировки. После правильной компоновки эти ключевые значения передаются в Reducer для получения желаемого результата клиента. Наконец Редуктор получить желаемый результат.
K1, V1 -> K2, V2 (мы напишем программу Mapper), -> K2, V' (здесь перемешать и смягчить данные) -> K3, V3 Генерировать вывод. К4, В4.
Обратите внимание, что все эти шаги являются только логической операцией, а не изменяют исходные данные.
Ваш вопрос: Какова цель фазы тасования и сортировки в редукторе в Map Reduce Programming?
Краткий ответ: для обработки данных, чтобы получить желаемый результат. Перестановка - это агрегирование данных, уменьшение - получение ожидаемого результата.
Перемешивание в MapReduce:
Передача данных от картографов редукторам называется перетасовкой. Процесс, с помощью которого система выполняет сортировку и передает вывод карты редуктору в качестве ввода. Фаза перемешивания MapReduce необходима для редукторов, иначе они не будут иметь никакого ввода. Процесс перемешивания экономит время и позволяет выполнить задачу за меньшее время.
Сортировка в MapReduce:
Сортировка на этапе уменьшения карты охватывает объединение и сортировку выходных данных карты. Сортировка в Hadoop помогает редуктору легко определить, когда должна начаться новая задача сокращения. Это может сэкономить время редуктору. Перемешивание и сортировка в hadoop Mapreduce не выполняются, если мы укажем 0 редукторов.
Есть только две вещи, которые MapReduce делает НАТУРАЛЬНО: сортировка и (реализовано сортировка) масштабируемый GroupBy.
Большинство приложений и шаблонов проектирования поверх MapReduce построены на этих двух операциях, которые предоставляются в случайном порядке и сортировке.
Это хорошее чтение. Надеюсь, поможет. С точки зрения сортировки, о которой вы говорите, я думаю, что это для операции слияния на последнем шаге Map. Когда операция сопоставления завершена, и необходимо записать результат на локальный диск, мульти-слияние будет выполнено для разбиений, сгенерированных из буфера. А для операции слияния полезна сортировка каждого раздела в расширенном.