Что O(log n) означает точно?
В настоящее время я узнаю о времени работы Big O Notation и времени амортизации. Я понимаю понятие O (n) линейного времени, означающего, что размер входных данных пропорционально влияет на рост алгоритма... и то же самое относится, например, к квадратичному времени O (n2) и т. Д. Даже к алгоритмам такие как генераторы перестановок, с O(n!) раз, которые растут на факториалах.
Например, следующая функция - O (n), потому что алгоритм растет пропорционально его входу n:
f(int n) {
int i;
for (i = 0; i < n; ++i)
printf("%d", i);
}
Точно так же, если бы был вложенный цикл, время было бы O (n2).
Но что именно O (log n)? Например, что значит сказать, что высота полного двоичного дерева равна O (log n)?
Я знаю (возможно, не очень подробно), что такое логарифм, в том смысле, что: log10 100 = 2, но я не могу понять, как определить функцию с логарифмическим временем.
34 ответа
Я не могу понять, как определить функцию со временем журнала.
Наиболее распространенные атрибуты логарифмической функции времени выполнения:
- выбор следующего элемента для выполнения какого-либо действия является одной из нескольких возможностей, и
- нужно выбрать только одного.
или же
- элементы, над которыми выполняется действие, это цифры n
Вот почему, например, поиск людей в телефонной книге - это O(log n). Вам не нужно проверять каждого человека в телефонной книге, чтобы найти нужного; вместо этого вы можете просто разделить-и-завоевать, посмотрев, где их имена расположены в алфавитном порядке, и в каждом разделе вам нужно только изучить подмножество каждого раздела, прежде чем вы в конце концов найдете чей-то номер телефона.
Конечно, большая телефонная книга все еще займет у вас больше времени, но она не будет расти так же быстро, как пропорциональное увеличение дополнительного размера.
Мы можем расширить пример телефонной книги, чтобы сравнить другие виды операций и их время выполнения. Мы предполагаем, что в нашей телефонной книге есть компании ("Желтые страницы"), которые имеют уникальные имена, и люди ("Белые страницы"), которые могут не иметь уникальных имен. Телефонный номер назначается максимум одному человеку или бизнесу. Мы также предполагаем, что для перехода на определенную страницу требуется постоянное время.
Вот время выполнения некоторых операций, которые мы могли бы выполнять в телефонной книге, от лучших к худшим:
O (1) (в лучшем случае): учитывая страницу с названием компании и названием компании, найдите номер телефона.
O (1) (средний регистр): учитывая страницу с именем человека и его именем, найдите номер телефона.
O (log n): учитывая имя человека, найдите номер телефона, выбрав случайную точку примерно на полпути в той части книги, которую вы еще не искали, а затем проверьте, находится ли имя человека в этой точке. Затем повторите процесс примерно на полпути через часть книги, где находится имя человека. (Это бинарный поиск по имени человека.)
O (n): Найти всех людей, номера телефонов которых содержат цифру "5".
O (n): По номеру телефона найдите человека или компанию с этим номером.
O (n log n): в офисе принтера произошла путаница, и в нашей телефонной книге все страницы были вставлены в случайном порядке. Исправьте порядок так, чтобы он был правильным: посмотрите на имя на каждой странице, а затем поместите эту страницу в соответствующее место в новой пустой телефонной книге.
Для приведенных ниже примеров мы сейчас в офисе принтера. Телефонные книги ждут отправки по почте каждому жителю или предприятию, и на каждой телефонной книге есть наклейка, указывающая, куда ее следует отправлять. Каждый человек или бизнес получает одну телефонную книгу.
O (n log n): мы хотим персонализировать телефонную книгу, поэтому мы собираемся найти имя каждого человека или компании в его назначенной копии, затем обвести их имя в книге и написать короткую благодарственную записку за их покровительство,
O (n2): в офисе произошла ошибка, и каждая запись в каждой телефонной книге имеет дополнительный "0" в конце номера телефона. Возьми немного белого и убери каждый ноль.
O (n · n!): Мы готовы загрузить телефонные книги в док-станцию. К сожалению, робот, который должен был загружать книги, стал бесполезным: он кладет книги на грузовик в случайном порядке! Хуже того, он загружает все книги в грузовик, затем проверяет, находятся ли они в правильном порядке, а если нет, то выгружает их и начинает заново. (Это ужасный вид бого.)
O (nn): Вы исправляете робота, чтобы он правильно загружал вещи. На следующий день один из ваших коллег подшучивает над вами и подключает робот-погрузчик к автоматизированным системам печати. Каждый раз, когда робот отправляется на загрузку оригинальной книги, заводской принтер дублирует все телефонные книги! К счастью, системы обнаружения ошибок роботов настолько сложны, что робот не пытается печатать еще больше копий, когда для загрузки встречает дубликат книги, но ему все равно приходится загружать все напечатанные оригиналы и дубликаты книг.
Для более математического объяснения вы можете проверить, как сложность времени достигает log n Вот. https://hackernoon.com/what-does-the-time-complexity-o-log-n-actually-mean-45f94bb5bfbf
O(log N) в основном означает, что время идет линейно, в то время как n идет вверх по экспоненте. Так что, если это займет 1 второй для вычисления 10 элементы, это займет 2 секунды для вычисления 100 элементы, 3 секунды для вычисления 1000 элементы и так далее.
Это O(log n) когда мы делим и побеждаем алгоритмы типа, например, бинарный поиск. Другой пример - быстрая сортировка, где каждый раз, когда мы делим массив на две части, и каждый раз, когда это занимает O(N) время, чтобы найти элемент поворота. Отсюда это N O(log N)
На этот вопрос уже было выложено много хороших ответов, но я считаю, что нам действительно не хватает важного ответа, а именно иллюстрированного ответа.
Что значит сказать, что высота полного двоичного дерева равна O(log n)?
На следующем рисунке изображено двоичное дерево. Обратите внимание, что каждый уровень содержит удвоенное количество узлов по сравнению с уровнем выше (следовательно, двоичным):

Бинарный поиск - пример со сложностью O(log n), Предположим, что узлы на нижнем уровне дерева на рисунке 1 представляют элементы в некоторой отсортированной коллекции. Бинарный поиск - это алгоритм "разделяй и властвуй", и на рисунке показано, как нам потребуется (не более) 4 сравнений, чтобы найти запись, которую мы ищем в этом наборе данных из 16 элементов.
Предположим, что вместо этого у нас был набор данных с 32 элементами. Продолжите рисунок выше, чтобы найти, что теперь нам нужно 5 сравнений, чтобы найти то, что мы ищем, поскольку дерево умножилось только на один уровень глубже, когда мы умножили объем данных. В результате сложность алгоритма может быть описана как логарифмический порядок.
Заговор log(n) на простом листе бумаги, приведет к графику, где рост кривой замедляется как n увеличивается:

обзор
Другие дали хорошие примеры диаграмм, такие как древовидные диаграммы. Я не видел простых примеров кода. Поэтому в дополнение к моему объяснению я приведу некоторые алгоритмы с простыми операторами печати, чтобы проиллюстрировать сложность различных категорий алгоритмов.
Во-первых, вам нужно иметь общее представление о логарифме, которое вы можете получить по https://en.wikipedia.org/wiki/Logarithm. Использование естественных наук e и натуральное бревно. Ученики-инженеры будут использовать log_10 (база 10 журналов), а ученые-программисты будут часто использовать log_2 (база 2 журналов), поскольку компьютеры работают на двоичном языке. Иногда вы можете увидеть сокращения натурального журнала как ln()инженеры обычно оставляют _10 выключенным и просто используют log() и log_2 сокращается как lg(), Все типы логарифмов растут одинаково, поэтому они имеют одну и ту же категорию log(n),
Когда вы смотрите на примеры кода ниже, я рекомендую посмотреть O(1), затем O(n), затем O(n^2). После того, как вы хорошо с ними, а затем посмотрите на других. Я включил чистые примеры, а также варианты, чтобы продемонстрировать, как едва заметные изменения могут привести к той же классификации.
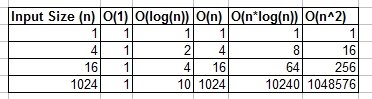
Вы можете думать о O(1), O(n), O(logn) и т. Д. Как о классах или категориях роста. Некоторые категории займут больше времени, чем другие. Эти категории помогают нам упорядочить производительность алгоритма. Некоторые растут быстрее по мере роста n. Следующая таблица демонстрирует указанный рост численно. В таблице ниже представьте log(n) как потолок log_2.
Примеры простых кодов различных категорий Big O:
O (1) - Примеры с постоянным временем:
- Алгоритм 1:
Алгоритм 1 выводит привет один раз, и он не зависит от n, поэтому он всегда будет работать в постоянное время, поэтому O(1),
print "hello";
- Алгоритм 2:
Алгоритм 2 печатает привет 3 раза, однако это не зависит от размера ввода. Даже при увеличении n этот алгоритм всегда будет печатать привет только 3 раза. Это, как говорится 3, является константой, так что этот алгоритм также O(1),
print "hello";
print "hello";
print "hello";
O(log(n)) - Логарифмические примеры:
- Алгоритм 3 - действует как "log_2"
Алгоритм 3 демонстрирует алгоритм, который работает в log_2(n). Обратите внимание, что операция post цикла for умножает текущее значение i на 2, поэтому i идет от 1 до 2 до 4 до 8 до 16 до 32 ...
for(int i = 1; i <= n; i = i * 2)
print "hello";
- Алгоритм 4 - действует как "log_3"
Алгоритм 4 демонстрирует log_3. уведомление i идет от 1 до 3 до 9 до 27...
for(int i = 1; i <= n; i = i * 3)
print "hello";
- Алгоритм 5 - действует как "log_1.02"
Алгоритм 5 важен, поскольку он помогает показать, что, пока число больше 1 и результат многократно умножается на самого себя, вы смотрите на логарифмический алгоритм.
for(double i = 1; i < n; i = i * 1.02)
print "hello";
O (n) - Примеры линейного времени:
- Алгоритм 6
Этот алгоритм прост, который печатает привет n раз.
for(int i = 0; i < n; i++)
print "hello";
- Алгоритм 7
Этот алгоритм показывает вариант, где он напечатает привет n/2 раза. n/2 = 1/2 * n. Мы игнорируем постоянную 1/2 и видим, что этот алгоритм равен O (n).
for(int i = 0; i < n; i = i + 2)
print "hello";
O (n * log(n)) - nlog(n) Примеры:
- Алгоритм 8
Думайте об этом как о комбинации O(log(n)) а также O(n), Вложенность циклов for помогает нам получить O(n*log(n))
for(int i = 0; i < n; i++)
for(int j = 1; j < n; j = j * 2)
print "hello";
- Алгоритм 9
Алгоритм 9 похож на алгоритм 8, но каждый из циклов допускает изменения, которые все же приводят к получению конечного результата O(n*log(n))
for(int i = 0; i < n; i = i + 2)
for(int j = 1; j < n; j = j * 3)
print "hello";
O(n^2) - n в квадрате Примеры:
- Алгоритм 10
O(n^2) легко получается путем вложения стандартного для циклов.
for(int i = 0; i < n; i++)
for(int j = 0; j < n; j++)
print "hello";
- Алгоритм 11
Как и алгоритм 10, но с некоторыми вариациями.
for(int i = 0; i < n; i++)
for(int j = 0; j < n; j = j + 2)
print "hello";
O (n ^ 3) - n куб. Примеры:
- Алгоритм 12
Это похоже на алгоритм 10, но с 3 циклами вместо 2.
for(int i = 0; i < n; i++)
for(int j = 0; j < n; j++)
for(int k = 0; k < n; k++)
print "hello";
- Алгоритм 13
Как алгоритм 12, но с некоторыми изменениями, которые все еще дают O(n^3),
for(int i = 0; i < n; i++)
for(int j = 0; j < n + 5; j = j + 2)
for(int k = 0; k < n; k = k + 3)
print "hello";
Резюме
Выше приведено несколько простых примеров и вариантов, которые помогут продемонстрировать, какие тонкие изменения могут быть внесены, которые действительно не изменяют анализ. Надеюсь, это даст вам достаточно понимания.
Приведенное ниже объяснение использует случай полностью сбалансированного двоичного дерева, чтобы помочь вам понять, как мы получаем сложность логарифмического времени.
Двоичное дерево - это случай, когда проблема размера n делится на подзадачу размера n/2, пока мы не достигнем проблемы размера 1:

И вот как вы получаете O(log n), то есть объем работы, который необходимо выполнить над указанным деревом, чтобы найти решение.
Распространенным алгоритмом с O(log n) сложностью по времени является бинарный поиск, рекурсивное отношение которого равно T(n/2) + O(1), т.е. на каждом последующем уровне дерева вы делите задачу на половину и выполняете постоянный объем дополнительной работы.
Если у вас была функция, которая принимает:
1 millisecond to complete if you have 2 elements.
2 milliseconds to complete if you have 4 elements.
3 milliseconds to complete if you have 8 elements.
4 milliseconds to complete if you have 16 elements.
...
n milliseconds to complete if you have 2**n elements.
Тогда это займет log2(n) времени. Обозначение Big O, в широком смысле, означает, что связь должна быть истинной только для больших n, и что постоянные факторы и меньшие члены можно игнорировать.
Логарифм
Хорошо, давайте попробуем и полностью поймем, что такое логарифм.
Представьте, что у нас есть веревка, и мы привязали ее к лошади. Если веревка напрямую привязана к лошади, то сила, которую лошадь должна будет оттянуть (скажем, от человека), равна 1.
Теперь представьте, что веревка обвита вокруг шеста. Лошади, которой нужно уйти, теперь придется тянуть во много раз сильнее. Количество раз будет зависеть от шероховатости веревки и размера полюса, но давайте предположим, что это умножит силу человека на 10 (когда веревка совершит полный оборот).
Теперь, если веревка обмотана петлей один раз, лошади нужно будет тянуть в 10 раз сильнее. Если человек решает сделать лошадь действительно трудной, он может снова обмотать веревку вокруг шеста, увеличивая ее прочность еще в 10 раз. Третий цикл снова увеличит прочность еще в 10 раз.

Мы видим, что для каждого цикла значение увеличивается на 10. Число ходов, необходимое для получения любого числа, называется логарифмом числа, т.е. нам нужно 3 сообщения, чтобы умножить вашу силу в 1000 раз, 6 сообщений, чтобы умножить вашу силу на 1000000.
3 - логарифм 1000, а 6 - логарифм 1 000 000 (основание 10).
Так что же на самом деле означает O(log n)?
В нашем примере выше, наша "скорость роста" равна O(log n). На каждую дополнительную петлю сила, которую может выдержать наша веревка, в 10 раз больше:
Turns | Max Force
0 | 1
1 | 10
2 | 100
3 | 1000
4 | 10000
n | 10^n
Теперь в приведенном выше примере использовалась база 10, но, к счастью, база журнала незначительна, когда мы говорим о больших обозначениях.
Теперь давайте представим, что вы пытаетесь угадать число от 1 до 100.
Your Friend: Guess my number between 1-100!
Your Guess: 50
Your Friend: Lower!
Your Guess: 25
Your Friend: Lower!
Your Guess: 13
Your Friend: Higher!
Your Guess: 19
Your Friend: Higher!
Your Friend: 22
Your Guess: Lower!
Your Guess: 20
Your Friend: Higher!
Your Guess: 21
Your Friend: YOU GOT IT!
Теперь вам понадобилось 7 догадок, чтобы понять это правильно. Но каковы здесь отношения? Какое наибольшее количество предметов вы можете угадать из каждого дополнительного предположения?
Guesses | Items
1 | 2
2 | 4
3 | 8
4 | 16
5 | 32
6 | 64
7 | 128
10 | 1024
Используя график, мы можем видеть, что если мы используем бинарный поиск, чтобы угадать число от 1 до 100, нам потребуется не более 7 попыток. Если бы у нас было 128 чисел, мы могли бы также угадать число в 7 попытках, но 129 чисел потребует максимум 8 попыток (в отношении логарифмов здесь нам понадобится 7 догадок для диапазона значений 128, 10 догадок для диапазона значений 1024). 7 - логарифм 128, 10 - логарифм 1024 (основание 2).
Обратите внимание, что я выделил "максимум". Большие обозначения всегда относятся к худшему случаю. Если вам повезет, вы можете угадать число за одну попытку, поэтому лучший случай - O(1), но это уже другая история.
Мы видим, что для каждого предположения наш набор данных сокращается. Хорошее практическое правило, чтобы определить, имеет ли алгоритм логарифмическое время, состоит в том, чтобы видеть, уменьшается ли набор данных на определенный порядок после каждой итерации
Что насчет O(n log n)?
В конечном итоге вы столкнетесь с алгоритмом линейного арифметического времени O(n log(n)). Эмпирическое правило, приведенное выше, применяется снова, но на этот раз логарифмическая функция должна запускаться n раз, например, уменьшение размера списка n раз, что происходит в алгоритмах. как слияние.
Вы можете легко определить, если алгоритмическое время равно n log n. Ищите внешний цикл, который перебирает список (O(n)). Затем посмотрите, есть ли внутренний цикл. Если внутренний цикл обрезает / сокращает набор данных на каждой итерации, этот цикл равен (O(log n), поэтому общий алгоритм равен = O (n log n).
Отказ от ответственности: Пример веревочного логарифма был взят из превосходной книги Математика "Восхищение" У. Сойера.
Логарифмическое время работы (O(log n)) по существу означает, что время выполнения увеличивается пропорционально логарифму входного размера - например, если 10 элементов занимает не более некоторого количества времени xи 100 предметов занимает максимум, скажем, 2xи 10000 предметов занимает максимум 4xтогда это выглядит как O(log n) сложность времени.
Сначала я рекомендую вам прочитать следующую книгу;
Вот некоторые функции и их ожидаемые сложности. Числа указывают частоты выполнения операторов.

После Big-O Сложность Chart также взяты из http://bigocheatsheet.com/ 
Наконец, очень простая витрина показывает, как она рассчитывается;
Анатомия частот выполнения операторов программы.
Анализ времени выполнения программы (пример).

Вы можете думать об O(log N) интуитивно, говоря, что время пропорционально количеству цифр в N.
Если операция выполняет работу с постоянным временем для каждой цифры или бита входа, вся операция займет время, пропорциональное количеству цифр или бит на входе, а не величине входа; таким образом, O(log N), а не O(N).
Если операция принимает серию решений с постоянным временем, каждое из которых вдвое (уменьшает в 3, 4, 5 раза) размер входного значения, которое необходимо учитывать, для целого потребуется время, пропорциональное логарифмическому основанию 2 (основанию 3)., база 4, база 5...) размера N ввода, а не O(N).
И так далее.
Что такое журналb(n)?
Это количество раз, которое вы можете несколько раз разрезать бревно длиной n на b равных частей, прежде чем достигнете участка размером 1.
Лучший способ мысленно визуализировать алгоритм, который выполняется в O(log n), заключается в следующем:
Если вы увеличите размер задачи на мультипликативную величину (т.е. умножите ее размер на 10), работа будет увеличена только на аддитивную величину.
Применяя это к вашему вопросу о бинарном дереве, вы получите хорошее приложение: если вы удвоите число узлов в бинарном дереве, высота увеличится только на 1 (аддитивное количество). Если вы удвоите его еще раз, оно все равно только увеличится на 1. (Очевидно, я предполагаю, что оно остается сбалансированным и тому подобное). Таким образом, вместо удвоения вашей работы при увеличении размера задачи вы выполняете лишь немного больше работы. Вот почему алгоритмы O(log n) просто великолепны.
Алгоритмы "разделяй и властвуй" обычно имеют logn компонент времени работы. Это происходит из-за многократного деления ввода на два.
В случае бинарного поиска на каждой итерации вы отбрасываете половину ввода. Следует отметить, что в нотации Big-O log - это база журнала 2.
Изменить: Как уже отмечалось, база журнала не имеет значения, но при вычислении производительности алгоритма Big-O логарифм будет получаться в два раза, поэтому я считаю его базой 2.
O(log n) немного вводит в заблуждение, точнее, O (log2 n), т. Е. (Логарифм с основанием 2).
Высота сбалансированного двоичного дерева равна O (log2 n), поскольку каждый узел имеет два (обратите внимание на "two", как в log2 n) дочерние узлы. Итак, дерево с n узлами имеет высоту log2 n.
Другим примером является бинарный поиск, который имеет время выполнения O (log2 n), потому что на каждом шаге вы делите пространство поиска на 2.
Но что именно O(log n)? Например, что значит сказать, что высота полного бинарного дерева равна O(log n)?
Я бы перефразировал это как "высота полного бинарного дерева - это log n". Вычисление высоты полного двоичного дерева было бы O(log n), если вы переходите вниз шаг за шагом.
Я не могу понять, как определить функцию с логарифмическим временем.
Логарифм по сути является обратным возведению в степень. Таким образом, если каждый "шаг" вашей функции исключает фактор элементов из исходного набора элементов, это алгоритм логарифмического времени.
В примере с деревом вы можете легко увидеть, что понижение уровня узлов сокращает экспоненциальное число элементов при продолжении обхода. Популярный пример просмотра отсортированной по имени телефонной книги по сути эквивалентен обходу двоичного дерева поиска (средняя страница является корневым элементом, и на каждом шаге можно определить, идти ли влево или вправо).
O(log n) относится к функции (или алгоритму, или шагу в алгоритме), работающей в течение времени, пропорционального логарифму (обычно основание 2 в большинстве случаев, но не всегда, и в любом случае это несущественно, если использовать обозначение big-O *) размера входа.
Логарифмическая функция является обратной к экспоненциальной функции. Иными словами, если ваш вклад растет экспоненциально (а не линейно, как вы обычно это считаете), ваша функция растет линейно.
O(log n) время выполнения очень распространено в любом приложении типа "разделяй и властвуй", потому что вы (в идеале) сокращаете работу вдвое. Если на каждом из этапов деления или завоевания вы выполняете работу с постоянным временем (или работу, которая не является постоянной, но со временем растет медленнее, чем O(log n)), тогда вся ваша функция O(log n), Довольно часто каждый шаг требует линейного времени на входе; это составит общую сложность времени O(n log n),
Сложность времени выполнения бинарного поиска является примером O(log n), Это связано с тем, что в бинарном поиске вы всегда игнорируете половину своего ввода на каждом последующем шаге, разделяя массив пополам и фокусируясь только на одной половине с каждым шагом. Каждый шаг является постоянным временем, потому что в бинарном поиске вам нужно сравнить только один элемент с вашим ключом, чтобы выяснить, что делать дальше, независимо от того, насколько большой массив вы рассматриваете в любой момент. Таким образом, вы делаете примерно log(n)/log(2) шагов.
Сложность времени выполнения сортировки слиянием является примером O(n log n), Это потому, что вы делите массив пополам с каждым шагом, в результате чего получается примерно log(n)/log(2) шагов. Однако на каждом шаге необходимо выполнять операции слияния для всех элементов (будь то одна операция слияния на двух подсписках из n/2 элементов или две операции слияния на четырех подсписках из n/4 элементов, не имеет значения, поскольку она добавляет к необходимости сделать это для п элементов в каждом шаге). Таким образом, общая сложность O(n log n),
* Помните, что обозначение big-O по определению не имеет значения для констант. Кроме того, путем изменения правила базы для логарифмов, единственная разница между логарифмами разных оснований является постоянным фактором.
Эти 2 случая займут O(log n) время
case 1: f(int n) {
int i;
for (i = 1; i < n; i=i*2)
printf("%d", i);
}
case 2 : f(int n) {
int i;
for (i = n; i>=1 ; i=i/2)
printf("%d", i);
}
Это просто означает, что время, необходимое для этой задачи, увеличивается с log(n) (пример: 2 с для n = 10, 4 с для n = 100, ...). Прочитайте статьи Википедии об алгоритме двоичного поиска и Big O Notation для большей точности.
Проще говоря: на каждом шаге вашего алгоритма вы можете сократить работу пополам. (Асимптотически эквивалентно третьему, четвертому, ...)
Если вы построите логарифмическую функцию на графическом калькуляторе или чем-то подобном, вы увидите, что она действительно медленно растет - даже медленнее, чем линейная функция.
Вот почему алгоритмы с логарифмической сложностью по времени очень востребованы: даже для действительно больших n (скажем, n = 10^8) они работают более чем приемлемо.
Но что именно O(log n)
Что это значит именно "как n стремится к infinity, time стремится к a*log(n) где a постоянный масштабный коэффициент ".
Или на самом деле, это не совсем так; скорее это значит что-то вроде time деленное на a*log(n) стремится к 1 ".
"Стремится к" имеет обычное математическое значение из "анализа": например, "если вы выбираете произвольно малую ненулевую константу k тогда я могу найти соответствующее значение X такой, что ((time/(a*log(n))) - 1) меньше чем k для всех значений n лучше чем X ".
Проще говоря, это означает, что уравнение для времени может иметь некоторые другие компоненты: например, оно может иметь некоторое постоянное время запуска; но эти другие компоненты бледнеют к незначительности для больших значений n, и a*log(n) является доминирующим термином для больших n.
Обратите внимание, что если бы уравнение было, например...
время (n) = a + b log (n) + c n + d n n
... тогда это будет O(n в квадрате), потому что, независимо от того, что значения констант a, b, c и ненулевой d, d*n*n термин всегда будет доминировать над остальными при любом достаточно большом значении n.
Вот что означает обозначение бита О: оно означает "каков порядок доминирующего члена для любого достаточно большого n".
Каждый раз, когда мы пишем алгоритм или код, мы пытаемся проанализировать его асимптотическую сложность. Это отличается от своей временной сложности.
Асимптотическая сложность - это поведение времени выполнения алгоритма, тогда как временная сложность - это фактическое время выполнения. Но некоторые люди используют эти термины взаимозаменяемо.
Потому что сложность времени зависит от различных параметров, а именно.
1. Физическая система
2. Язык программирования
3. Стиль кодирования
4. И многое другое......
Фактическое время выполнения не является хорошей мерой для анализа.
Вместо этого мы принимаем входной размер в качестве параметра, потому что, какой бы ни был код, входные данные одинаковы.Таким образом, время выполнения зависит от размера ввода.
Ниже приведен пример алгоритма линейного времени
Линейный поиск
Учитывая n входных элементов, для поиска элемента в массиве вам нужно не более n сравнений. Другими словами, независимо от того, какой язык программирования вы используете, какой стиль кодирования вы предпочитаете, в какой системе вы его выполняете. В худшем случае требуется только n сравнений. Время выполнения линейно пропорционально размеру ввода.
И это не просто поиск, какой бы ни была работа (приращение, сравнение или любая операция), это функция размера ввода.
Таким образом, когда вы говорите, что какой-либо алгоритм равен O(log n), это означает, что время выполнения в логах умножается на размер ввода n.
По мере увеличения размера ввода увеличивается объем выполненной работы (здесь время выполнения).(Следовательно, пропорциональность)
n Work
2 1 units of work
4 2 units of work
8 3 units of work
Посмотрите, как увеличивается входной размер, проделанная работа увеличивается, и она не зависит от какой-либо машины. И если вы попытаетесь выяснить стоимость единиц работы, это на самом деле зависит от указанных выше параметров. Он будет меняться в зависимости от систем и всего.
Я могу добавить кое-что интересное, что я прочитал в книге Кормена и т. Д. Давным-давно. Теперь представьте себе проблему, в которой мы должны найти решение в проблемном пространстве. Это проблемное пространство должно быть конечным.
Теперь, если вы можете доказать, что на каждой итерации вашего алгоритма вы отсекаете часть этого пространства, то есть не менее некоторого предела, это означает, что ваш алгоритм работает за время O(logN).
Я должен отметить, что мы говорим здесь об относительном пределе доли, а не об абсолютном. Бинарный поиск - классический пример. На каждом шаге мы выбрасываем половину проблемного пространства. Но бинарный поиск - не единственный такой пример. Предположим, вы как-то доказали, что на каждом шаге вы выбрасываете не менее 1/128 проблемного пространства. Это означает, что ваша программа все еще работает во время O(logN), хотя и значительно медленнее, чем бинарный поиск. Это очень хороший совет при анализе рекурсивных алгоритмов. Часто можно доказать, что на каждом этапе рекурсия не будет использовать несколько вариантов, и это приводит к отсечению некоторой дроби в проблемном пространстве.
На самом деле, если у вас есть список из n элементов и вы создаете двоичное дерево из этого списка (как в алгоритме "разделяй и властвуй"), вы будете продолжать делить на 2, пока не достигнете списков размера 1 (листья).
На первом шаге вы делите на 2. Затем у вас есть 2 списка (2^1), вы делите каждый на 2, поэтому у вас есть 4 списка (2^2), вы делите снова, у вас есть 8 списков (2^3)) и так далее, пока размер вашего списка не станет 1
Это дает вам уравнение:
n/(2^steps)=1 <=> n=2^steps <=> lg(n)=steps
(вы берете lg с каждой стороны, lg - основание журнала 2)
O(logn) - это одна из полиномиальных временных сложностей для измерения производительности любого кода во время выполнения.
Я надеюсь, что вы уже слышали об алгоритме двоичного поиска.
Предположим, вам нужно найти элемент в массиве размера N.
В основном, выполнение кода похоже на N N/2 N/4 N/8.... и т. Д.
Если вы сложите всю работу, проделанную на каждом уровне, вы получите n(1+1/2+1/4....), что равно O(logn)
Я могу привести пример для цикла for и, возможно, однажды поняв концепцию, возможно, будет проще понять ее в разных контекстах.
Это означает, что в цикле шаг растет в геометрической прогрессии. Например
for (i=1; i<=n; i=i*2) {;}
Сложность в O-обозначениях этой программы O(log(n)). Давайте попробуем перебрать его вручную (n между 512 и 1023 (исключая 1024):
step: 1 2 3 4 5 6 7 8 9 10
i: 1 2 4 8 16 32 64 128 256 512
Хотя n где-то между 512 и 1023, имеет место только 10 итераций. Это связано с тем, что шаг в цикле растет экспоненциально и, таким образом, для достижения завершения требуется всего 10 итераций.
Логарифм x (к основанию a) является обратной функцией от ^x.
Это все равно, что сказать, что логарифм обратен экспоненциальному.
Теперь попытайтесь увидеть это таким образом: если экспоненциальный рост очень быстрый, то логарифм растет (обратно) очень медленно.
Разница между O(n) и O (log (n)) огромна, аналогична разнице между O(n) и O (a^n) (a является константой).
Полный бинарный пример - O(ln n), потому что поиск выглядит так:
1 2 3 4 5 6 7 8 9 10 11 12
Поиск 4 дает 3 хита: 6, 3, а затем 4. И log2 12 = 3, что является хорошим приблизительным значением для количества хитов, где это необходимо.

log x to base b = y обратная b^y = x
Если у вас M-арное дерево глубины d и размера n, то:
обход всего дерева ~ O(M^d) = O(n)
Пройдя по единственной дорожке в дереве ~ O(d) = O(войти n в базу M)
В информационных технологиях это означает, что:
f(n)=O(g(n)) If there is suitable constant C and N0 independent on N,
such that
for all N>N0 "C*g(n) > f(n) > 0" is true.
Кажется, что эти обозначения в основном взяты из математики.
В этой статье есть цитата: DE Knuth, "БОЛЬШОЕ ОМИКРОН И БОЛЬШАЯ ОМЕГА И БОЛЬШАЯ ТЕТА", 1976 г.:
Исходя из обсуждаемых здесь вопросов, я предлагаю членам SIGACT и редакторам журналов по информатике и математике принять обозначения, как определено выше, если только лучшая альтернатива не будет найдена достаточно скоро.
Сегодня 2016, но мы используем его до сих пор.
В математическом анализе это означает, что:
lim (f(n)/g(n))=Constant; where n goes to +infinity
Но даже в математическом анализе иногда этот символ использовался в значении "C*g(n) > f(n) > 0".
Как я знаю из университета, этот символ был введен немецким математиком Ландау (1877-1938).
Если вы ищете ответ, основанный на интуиции, я хотел бы предложить вам две интерпретации.
Представьте себе очень высокий холм с очень широким основанием. Чтобы добраться до вершины холма, есть два пути: один - это специальный путь, идущий по спирали вокруг холма, достигающего наверху, другой: небольшая терраса, похожая на резьбу, вырезанную для обеспечения лестницы. Теперь, если первый путь достигает линейного времени O(n), второй - O(log n).
Представьте себе алгоритм, который принимает целое число,
nв качестве ввода и завершается во времени, пропорциональномnтогда это O (n) или тета (n), но если он работает во времени, пропорциональномnumber of digits or the number of bits in the binary representation on numberтогда алгоритм выполняется за время O (log n) или тета (log n).