dottrace и оптимизирующий метод с indexof
public static string[] GetStringInBetween(string strBegin, string strEnd, string strSource, bool includeBegin, bool includeEnd)
{
string[] result = { "", "" };
int iIndexOfBegin = strSource.IndexOf(strBegin);
if (iIndexOfBegin != -1)
{
// include the Begin string if desired
if (includeBegin)
iIndexOfBegin -= strBegin.Length;
strSource = strSource.Substring(iIndexOfBegin + strBegin.Length);
int iEnd = strSource.IndexOf(strEnd);
if (iEnd != -1)
{
// include the End string if desired
if (includeEnd)
iEnd += strEnd.Length;
result[0] = strSource.Substring(0, iEnd);
// advance beyond this segment
if (iEnd + strEnd.Length < strSource.Length)
result[1] = strSource.Substring(iEnd + strEnd.Length);
}
}
return result;
}
использование:
string[] result = null;
result = HtmlHelper.GetStringInBetween(bits[0], bits[1], tagValuePair.Value, true, true);
Я использую dottrace, и этот метод использует 33% моего процессора. Как я могу оптимизировать это. Из-за этого мое приложение вылетает или мне не хватает памяти. Разумно ли, что этот метод статичен?
dottrace показывает 30% использования процессора на этом:
System.String.IndexOf(String, Int32, Int32, StringComparison)
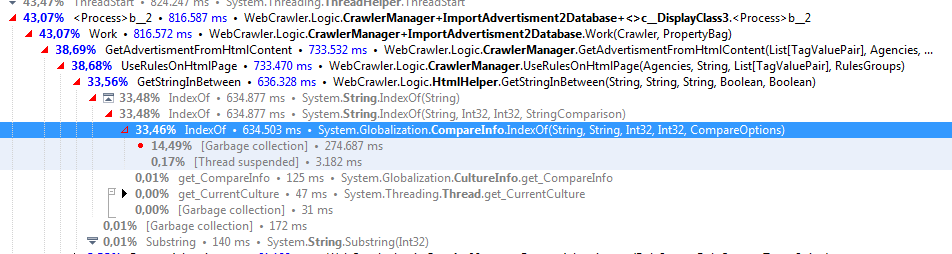
РЕДАКТИРОВАТЬ:
GetStringInBetween(string strBegin, string strEnd, string strSource, bool includeBegin, bool includeEnd)
strBegin = "<td class=\"m92_t_col2\">"
strEnd = "</td>"
strSource = "xxxxxxxx<td class=\"m92_t_col2\">Di. 31.01.12</td>xxxxxxxxxxxxxx
includeBegin = true
includeEnd = true
then i will get result
result[0] = "<td class=\"m92_t_col2\">Di. 31.01.12</td>"
надеюсь, что это помогает, что этот метод делает. Попробуйте найти строку между strBegin и strEnd...
2 ответа
Копирование части строки (ваш первый вызов SubString) просто для продолжения поиска в ней плохо сказывается на производительности. Вместо этого сохраните исходную строку ввода, но используйте перегрузку для IndexOf, которая принимает начальный индекс, а затем скорректируйте вычисление индекса для извлечения результата соответствующим образом.
Кроме того, зная, что эти строки не локализованы, вы можете получить их, используя порядковый компаратор в IndexOf.
Нечто подобное
public static string[] GetStringInBetween(string strBegin, string strEnd, string strSource, bool includeBegin, bool includeEnd)
{
string[] result = { "", "" };
int iIndexOfBegin = strSource.IndexOf(strBegin, StringComparison.Ordinal);
if (iIndexOfBegin != -1)
{
int iEnd = strSource.IndexOf(strEnd, iIndexOfBegin, StringComparison.Ordinal);
if (iEnd != -1)
{
result[0] = strSource.Substring(
iIndexOfBegin + (includeBegin ? 0 : strBegin.Length),
iEnd + (includeEnd ? strEnd.Length : 0) - iIndexOfBegin);
// advance beyond this segment
if (iEnd + strEnd.Length < strSource.Length)
result[1] = strSource.Substring(iEnd + strEnd.Length);
}
}
return result;
}
Для вашего примера ввода, кажется, вы работаете с фрагментами HTML.
Я предлагаю использовать HTML Agility Pack для разбора HTML - он предоставляет результаты в виде простого запроса, используя синтаксис LINQ to XML или XPath. Это быстрая и эффективная библиотека.