Запись словаря в CSV-файл с одной строкой для каждого "ключ: значение"
У меня есть словарь:
mydict = {key1: value_a, key2: value_b, key3: value_c}
Я хочу записать данные в файл dict.csv, в этом стиле:
key1: value_a
key2: value_b
key3: value_c
Я написал:
import csv
f = open('dict.csv','wb')
w = csv.DictWriter(f,mydict.keys())
w.writerow(mydict)
f.close()
Но теперь у меня есть все ключи в одном ряду и все значения в следующем ряду.
Когда мне удается написать такой файл, я также хочу прочитать его обратно в новый словарь.
Просто, чтобы объяснить мой код, словарь содержит значения и bool из textctrls и флажков (используя wxpython). Я хочу добавить кнопки "Сохранить настройки" и "Загрузить настройки". При сохранении настроек следует записать словарь в файл указанным способом (чтобы пользователю было проще редактировать csv-файл напрямую), загрузить настройки следует прочитать из файла и обновить текстовые поля и флажки.
7 ответов
DictWriter не работает так, как вы ожидаете.
with open('dict.csv', 'wb') as csv_file:
writer = csv.writer(csv_file)
for key, value in mydict.items():
writer.writerow([key, value])
Чтобы прочитать это обратно:
with open('dict.csv', 'rb') as csv_file:
reader = csv.reader(csv_file)
mydict = dict(reader)
что довольно компактно, но предполагает, что вам не нужно выполнять преобразование типов при чтении
Просто, чтобы дать возможность, запись словаря в CSV-файл также может быть сделано с пакетом Pandas. В приведенном примере это может быть что-то вроде этого:
mydict = {'key1': 'a', 'key2': 'b', 'key3': 'c'}
import pandas as pd
(pd.DataFrame.from_dict(data=mydict, orient='index')
.to_csv('dict_file.csv', header=False))
Главное, что нужно принять во внимание, это установить для параметра 'orient' значение 'index' внутри метода from_dict. Это позволяет вам выбрать, хотите ли вы записать каждый ключ словаря в новую строку.
Кроме того, внутри метода to_csv параметр заголовка имеет значение False, чтобы иметь только элементы словаря без раздражающих строк. Вы всегда можете установить имена столбцов и индексов внутри метода to_csv.
Ваш вывод будет выглядеть так:
key1,a
key2,b
key3,c
Если вместо этого вы хотите, чтобы ключи были именами столбцов, просто используйте параметр orient по умолчанию, который равен columns, как вы можете проверить в ссылках на документацию.
Самый простой способ - игнорировать модуль csv и отформатировать его самостоятельно.
with open('my_file.csv', 'w') as f:
[f.write('{0},{1}\n'.format(key, value)) for key, value in my_dict.items()]
outfile = open( 'dict.txt', 'w' )
for key, value in sorted( mydict.items() ):
outfile.write( str(key) + '\t' + str(value) + '\n' )
Вы можете просто сделать:
for key in mydict.keys():
f.write(str(key) + ":" + str(mydict[key]) + ",");
Так что вы можете иметь
ключ_1: значение_1, ключ_2: значение_2
Лично меня всегда раздражал модуль csv. Я ожидаю, что кто-то еще покажет вам, как с этим справиться, но мое быстрое и грязное решение:
with open('dict.csv', 'w') as f: # This creates the file object for the context
# below it and closes the file automatically
l = []
for k, v in mydict.iteritems(): # Iterate over items returning key, value tuples
l.append('%s: %s' % (str(k), str(v))) # Build a nice list of strings
f.write(', '.join(l)) # Join that list of strings and write out
Тем не менее, если вы хотите прочитать его обратно, вам нужно будет выполнить некоторый раздражающий синтаксический анализ, особенно если он все в одной строке. Вот пример использования предложенного вами формата файла.
with open('dict.csv', 'r') as f: # Again temporary file for reading
d = {}
l = f.read().split(',') # Split using commas
for i in l:
values = i.split(': ') # Split using ': '
d[values[0]] = values[1] # Any type conversion will need to happen here
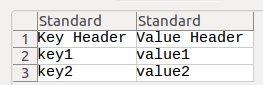
import csv
dict = {"Key Header":"Value Header", "key1":"value1", "key2":"value2"}
with open("test.csv", "w") as f:
writer = csv.writer(f)
for i in dict:
writer.writerow([i, dict[i]])
f.close()
#code to insert and read dictionary element from csv file
import csv
n=input("Enter I to insert or S to read : ")
if n=="I":
m=int(input("Enter the number of data you want to insert: "))
mydict={}
list=[]
for i in range(m):
keys=int(input("Enter id :"))
list.append(keys)
values=input("Enter Name :")
mydict[keys]=values
with open('File1.csv',"w") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=list)
writer.writeheader()
writer.writerow(mydict)
print("Data Inserted")
else:
keys=input("Enter Id to Search :")
Id=str(keys)
with open('File1.csv',"r") as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row[Id]) #print(row) to display all data
Я нуб, также опоздал на эти комментарии, хаха, но вы пытались добавить "s" на: w.writerow(mydict), например так: w.writerows(mydict), эта проблема произошла со мной, но с списки, я использовал единственное число вместо множественного числа. Pops! было исправлено.