1D БПФ столбцов и строк трехмерной матрицы в CUDA
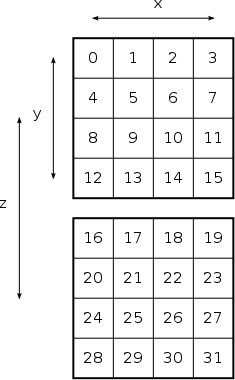
Я пытаюсь вычислить пакетные 1D БПФ, используя cufftPlanMany, Набор данных поступает из трехмерного поля, хранящегося в одномерном массиве, где я хочу вычислить 1D БПФ в x а также y направление. Данные сохраняются, как показано на рисунке ниже; непрерывный в x затем y затем z,
Делать пакетные БПФ в x -направление (я считаю) прямолинейно; с вводом stride=1, distance=nx а также batch=ny * nz, он вычисляет БПФ над элементами {0,1,2,3}, {4,5,6,7}, ..., {28,29,30,31}, Однако я не могу придумать, как добиться того же для БПФ в y -направление. Партия для каждого xy Самолет снова прост (вход stride=nx, dist=1, batch=nx результаты в БПФ более {0,4,8,12}, {1,5,9,13}, так далее.). Но с batch=nx * nz идущий от {3,7,11,15} в {16,20,24,28}, расстояние больше чем 1, Можно ли это как-то сделать с помощью cufftPlanMany?
2 ответа
Я думаю, что краткий ответ на ваш вопрос (возможность использования одного cufftPlanMany выполнять 1D БПФ столбцов трехмерной матрицы) НЕТ.
Действительно, преобразования выполняются в соответствии с cufftPlanMany что ты называешь как
cufftPlanMany(&handle, rank, n,
inembed, istride, idist,
onembed, ostride, odist, CUFFT_C2C, batch);
должен подчиняться расширенному макету данных. В частности, 1D БПФ разрабатываются по следующей схеме
input[b * idist + x * istride]
где b обращается к b -й сигнал и istride это расстояние между двумя последовательными элементами в одном и том же сигнале. Если 3D матрица имеет размеры M * N * Q и если вы хотите выполнить 1D преобразования вдоль столбцов, то расстояние между двумя последовательными элементами будет M в то время как расстояние между двумя последовательными сигналами будет 1, Кроме того, количество пакетных выполнений должно быть установлено равным M, С этими параметрами вы можете покрыть только один фрагмент трехмерной матрицы. Действительно, если вы попытаетесь увеличить M затем cuFFT начнет пытаться вычислить новые FFT по столбцам, начиная со второго ряда. Единственное решение этой проблемы - итеративный вызов cufftExecC2C покрыть все Q дольки.
Для записи следующий код предоставляет полностью проработанный пример того, как выполнять 1D БПФ столбцов трехмерной матрицы.
#include <thrust/device_vector.h>
#include <cufft.h>
/********************/
/* CUDA ERROR CHECK */
/********************/
#define gpuErrchk(ans) { gpuAssert((ans), __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, const char *file, int line, bool abort=true)
{
if (code != cudaSuccess)
{
fprintf(stderr,"GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) exit(code);
}
}
int main() {
const int M = 3;
const int N = 4;
const int Q = 2;
thrust::host_vector<float2> h_matrix(M * N * Q);
for (int k=0; k<Q; k++)
for (int j=0; j<N; j++)
for (int i=0; i<M; i++) {
float2 temp;
temp.x = (float)(j + k * M);
//temp.x = 1.f;
temp.y = 0.f;
h_matrix[k*M*N+j*M+i] = temp;
printf("%i %i %i %f %f\n", i, j, k, temp.x, temp.y);
}
printf("\n");
thrust::device_vector<float2> d_matrix(h_matrix);
thrust::device_vector<float2> d_matrix_out(M * N * Q);
// --- Advanced data layout
// input[b * idist + x * istride]
// output[b * odist + x * ostride]
// b = signal number
// x = element of the b-th signal
cufftHandle handle;
int rank = 1; // --- 1D FFTs
int n[] = { N }; // --- Size of the Fourier transform
int istride = M, ostride = M; // --- Distance between two successive input/output elements
int idist = 1, odist = 1; // --- Distance between batches
int inembed[] = { 0 }; // --- Input size with pitch (ignored for 1D transforms)
int onembed[] = { 0 }; // --- Output size with pitch (ignored for 1D transforms)
int batch = M; // --- Number of batched executions
cufftPlanMany(&handle, rank, n,
inembed, istride, idist,
onembed, ostride, odist, CUFFT_C2C, batch);
for (int k=0; k<Q; k++)
cufftExecC2C(handle, (cufftComplex*)(thrust::raw_pointer_cast(d_matrix.data()) + k * M * N), (cufftComplex*)(thrust::raw_pointer_cast(d_matrix_out.data()) + k * M * N), CUFFT_FORWARD);
cufftDestroy(handle);
for (int k=0; k<Q; k++)
for (int j=0; j<N; j++)
for (int i=0; i<M; i++) {
float2 temp = d_matrix_out[k*M*N+j*M+i];
printf("%i %i %i %f %f\n", i, j, k, temp.x, temp.y);
}
}
Ситуация отличается для случая, когда вы хотите выполнить 1D преобразования строк. В этом случае расстояние между двумя последовательными элементами 1 в то время как расстояние между двумя последовательными сигналами M, Это позволяет вам установить количество N * Q преобразования, а затем вызывать cufftExecC2C только раз. Для записи приведенный ниже код предоставляет полный пример одномерных преобразований строк трехмерной матрицы.
#include <thrust/device_vector.h>
#include <cufft.h>
/********************/
/* CUDA ERROR CHECK */
/********************/
#define gpuErrchk(ans) { gpuAssert((ans), __FILE__, __LINE__); }
inline void gpuAssert(cudaError_t code, const char *file, int line, bool abort=true)
{
if (code != cudaSuccess)
{
fprintf(stderr,"GPUassert: %s %s %d\n", cudaGetErrorString(code), file, line);
if (abort) exit(code);
}
}
int main() {
const int M = 3;
const int N = 4;
const int Q = 2;
thrust::host_vector<float2> h_matrix(M * N * Q);
for (int k=0; k<Q; k++)
for (int j=0; j<N; j++)
for (int i=0; i<M; i++) {
float2 temp;
temp.x = (float)(j + k * M);
//temp.x = 1.f;
temp.y = 0.f;
h_matrix[k*M*N+j*M+i] = temp;
printf("%i %i %i %f %f\n", i, j, k, temp.x, temp.y);
}
printf("\n");
thrust::device_vector<float2> d_matrix(h_matrix);
thrust::device_vector<float2> d_matrix_out(M * N * Q);
// --- Advanced data layout
// input[b * idist + x * istride]
// output[b * odist + x * ostride]
// b = signal number
// x = element of the b-th signal
cufftHandle handle;
int rank = 1; // --- 1D FFTs
int n[] = { M }; // --- Size of the Fourier transform
int istride = 1, ostride = 1; // --- Distance between two successive input/output elements
int idist = M, odist = M; // --- Distance between batches
int inembed[] = { 0 }; // --- Input size with pitch (ignored for 1D transforms)
int onembed[] = { 0 }; // --- Output size with pitch (ignored for 1D transforms)
int batch = N * Q; // --- Number of batched executions
cufftPlanMany(&handle, rank, n,
inembed, istride, idist,
onembed, ostride, odist, CUFFT_C2C, batch);
cufftExecC2C(handle, (cufftComplex*)(thrust::raw_pointer_cast(d_matrix.data())), (cufftComplex*)(thrust::raw_pointer_cast(d_matrix_out.data())), CUFFT_FORWARD);
cufftDestroy(handle);
for (int k=0; k<Q; k++)
for (int j=0; j<N; j++)
for (int i=0; i<M; i++) {
float2 temp = d_matrix_out[k*M*N+j*M+i];
printf("%i %i %i %f %f\n", i, j, k, temp.x, temp.y);
}
}
Я полагаю, idist=nx*nz также может перепрыгнуть всю плоскость, а batch=nz будет покрывать одну плоскость yx. Решение должно быть принято в зависимости от того, больше ли nx или nz.