Интегрировать распределенный источник данных в общую платформу
У меня есть 2 схемы БД, которые имеют обзоры мобильных телефонов. Единый обзор имеет 3 элемента. Текст отзыва, рейтинг и категория (в данном обзоре говорится о том, какая часть мобильного телефона. Например, "дисплей"). Я преобразовал их в два RDF, используя D2RQ.
Теперь я хочу построить граф знаний для домена мобильного телефона. Пример: Дисплей разделен на ЖК-дисплей и светодиод. Как мне построить график таких знаний?
Для примера я могу создать следующую структуру класса, используя Protege. 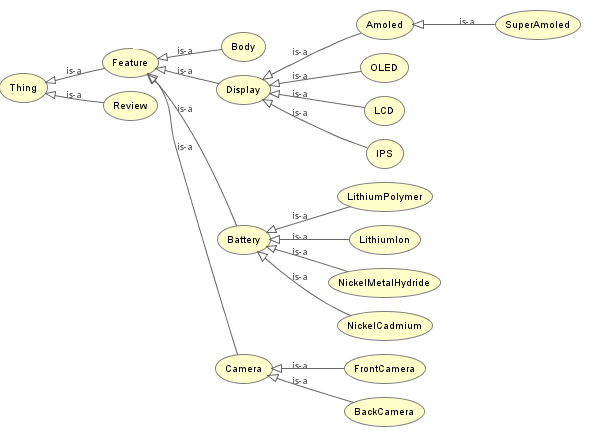
я делаю это правильно? и нужно ли мне создавать отдельных лиц для каждой подфункции, чтобы построить полный граф знаний?
- Добавление дополнительных требований -
Это то, чего я хочу достичь.
Каждый отзыв относится к определенной категории. Это будет соответствовать либо суперклассу, либо подклассу. Пример: дисплей или Amoled
Используя SPARQL, я хочу получить все отзывы о суперклассе, скажем, о Display. Применяя фильтр к категории, я могу получить отзывы о "дисплее". Но как включить в набор результатов обзоры подклассов, таких как Amoled, OLED, LCD или IPS?
1 ответ
Ты делаешь это правильно. И нет, вам не нужно создавать индивидуумов каждой субфектации. Если, конечно, приложение, которое будет использовать этот граф знаний, ожидает этого.
То, что сводится к тому, что это в значительной степени вопрос вкуса и ваших собственных целей. Из того, что я могу судить, структура вашего класса выглядит хорошо. Я не могу судить, является ли он "полным" или "достаточно хорошим", потому что я не знаю, для чего вы хотите его использовать.
Однако не отчаивайтесь: хорошая вещь в использовании технологии RDF заключается в том, что вам не нужно делать это полностью или прямо с первого прохода. Работайте с тем, что у вас есть, создайте свое приложение, как только вы дойдете до пункта "Мне нужна дополнительная информация в моем графе знаний здесь", просто вернитесь и добавьте его.