Исключение в потоке "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
Попытка запустить версию программы MR (2.7) в Windows 7 64 бит в затмении во время выполнения вышеуказанного исключения. Я проверил это, используя 64-битную версию Java 1.8, и заметил, что все демоны hadoop запущены.
Любые предложения высоко ценятся
21 ответ
В дополнение к другим решениям, пожалуйста, скачайте winutil.exe и hadoop.dll и добавьте в $HADOOP_HOME/bin. Меня устраивает.
https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1/bin
Примечание: я использую версию hadoop-2.7.3 
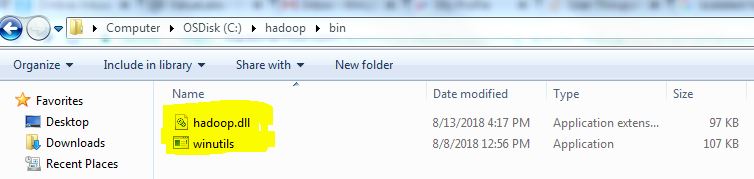
После сдачи haddop.dll а также winutils в hadoop/bin папку и добавление папки hadoop в PATHнам также нужно поставить hadoop.dll в C:\Windows\System32 папка
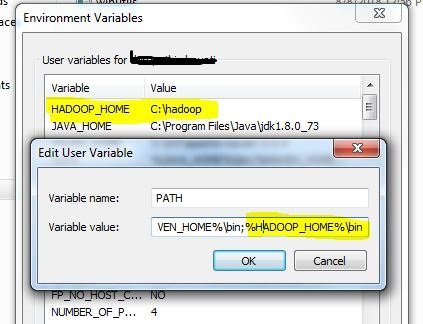
Эта проблема произошла со мной, и причина была я забыл добавить %HADOOP_HOME%/bin в PATH в моей среде переменные.
В моем случае у меня возникла эта проблема при запуске модульных тестов на локальном компьютере после обновления зависимостей до CDH6, у меня уже были правильно настроены переменные HADOOP_HOME и PATH, но мне пришлось скопировать hadoop.ddl в C: \ Windows \ System32, как предложено в других отвечать.
После попытки всего вышеперечисленного все заработало после помещения hasoop.dll в windows / System32.
Для меня эта проблема была решена путем загрузки winutils.exe & hadoop.dll из https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1/bin и помещения их в папку hadoop/bin
Добавление hadoop.dll и WinUntils.exe исправило ошибку, поддержку последних версий можно найти здесь
У меня уже было %HADOOP_HOME%/bin в моем PATH и мой код ранее работал без ошибок. Перезапуск моей машины заставил это работать снова.
Несоответствие версии является основной причиной этой проблемы. Выполнение полной версии hadoop с библиотекой java решит проблему, и если вы все еще сталкиваетесь с проблемой и работаете над версией hadoop 3.1.x, используйте эту библиотеку для загрузки bin
https://github.com/s911415/apache-hadoop-3.1.0-winutils/tree/master/bin
у меня уже было
%HADOOP_HOME%/binв моем ПУТИ. Добавление hadoop.dll в
Hadoop/bin directoryзаставил снова работать.
После загрузки и настройки hadoop.dll и wintuils.exe в качестве предыдущего ответа вам необходимо «перезапустить окна», чтобы они заработали.
Я отвечаю на это, потому что у меня была такая же проблема.
Я использую MinIO в качестве хранилища объектов и spark в качестве механизма обработки, версия 3.1.2 и hadoop 3.2 (spark-3.1.2-bin-hadoop3.2).
И я решил эту проблему, просто загрузив файл hadoop.dll со страницы Github = https://github.com/cdarlint/winutils и сохранив его в папке bin в моей папке spark. Затем я просто нажал кнопку spark-submit на терминале vscode, и все прошло гладко. введите описание изображения здесь
Я надеюсь, что это может помочь любому здесь!
В моем случае (pyspark = 3.3.1, версия Spark = 3.3.1, версия Hadoop = 3.3.2 ) я устанавливаю env vars по коду Python
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['HADOOP_HOME'] = "C:\\Program Files\\Hadoop\\"
добавлен с https://github.com/kontext-tech/winutils в папку bin последняя версия файлов hadoop hadoop-3.4.0-win10-x64 и добавлен hadoop.dll в C:\Windows\System32
В Intellij в разделе Run/Debug Configurations откройте приложение, которое вы пытаетесь запустить. На вкладке конфигурации укажите точный рабочий каталог. Наличие переменной для представления рабочего каталога также создает эту проблему. Когда я изменил рабочий каталог в настройках, он снова начал работать.
Да, эта проблема возникла, когда я использовал PIGUNITS для автоматизации PIGSCRIPTS, Две вещи в последовательности должны быть сделаны:
Скопируйте оба файла, как указано выше, в папку и добавьте ее в переменные окружения в разделе PATH.
Чтобы отразить изменения, которые вы только что сделали, вам нужно перезагрузить компьютер, чтобы загрузить файл.
Под JUNIT я получал эту ошибку, которая также поможет другим:
org.apache.pig.impl.logicalLayer.FrontendException: ОШИБКА 1066: невозможно открыть итератор для псевдонима XXXXX. Внутренняя ошибка: java.lang.IllegalStateException: задание в состоянии DEFINE вместо запуска в org.apache.pig.PigServer.openIterator(PigServer.java:925)
Хотя все приведенные выше рекомендации не помогли мне устранить эту ошибку. Установка переменной среды HADOOP_BIN_PATH устранила мою ошибку. Также еще одна связанная ошибка, когда слово access0 в строке ошибки заменяется на createDirectoryWithMode0.
Если вы заглянете в папку Hadoop/bin и проверите hdfs.cmd и Mapred.cmd, станет ясно, что ожидается переменная среды HADOOP_BIN_PATH. Например, этот код:
if not defined HADOOP_BIN_PATH (
set HADOOP_BIN_PATH=%~dp0
)
%~dp0 должен расшириться до папки, содержащей файл cmd. Однако вы можете представить себе другие компоненты Hadoop, такие как демоны, которые не запускаются из командной строки, которые также могут ожидать установки этой переменной среды.
Установите HADOOP_BIN_PATH в папку bin в каталоге Hadoop.
Если вы установили переменную среды пользователя, вам потребуется перезапустить процесс, запускающий ваше приложение. Если вы установили переменную системной среды, вам потребуется перезагрузить Windows, чтобы увидеть эффект.
Если проблема не устранена после добавления правильной версии Hadoop Winutils + Hadoop.dll, проверьте, установлена ли у вас JRE или JDK.
Hadoop написан на Java. Поэтому для этого потребуется JRE (среда выполнения Java), по крайней мере, с поддерживаемой версией. Но JRE (среда выполнения Java) недостаточна. Для запуска заданий Map-Reduce Hadoop по существу требует JDK (Java Development Kit). Вот почему после установки (с помощью JRE) при запуске командыpysparkв терминале вы получите этоUnable to load native-hadoop library for your platformпредупреждение. Для меня переход на JDK решил эти проблемы.
Вот тема о требованиях JDK для Hadoop: https://www.quora.com/Why-we-need-JDK-for-Hadoop-installation.
Вот что сработало для меня: загрузите последнюю версию winutils https://github.com/kontext-tech/winutils или проверьте свой текст Spark Release, он показывает cer Hadoop, который он использует.
Шаги
Скачать репозиторий
Создайте папку с именем hadoop в любом месте (например, на рабочем столе/hadoop)
Вставьте bin в эту папку (тогда у вас будет hadoop/bin)
скопировать hadoop.dll в windows/system32
Установить системную среду:
set HADOOP_HOME=c:/desktop/hadoop set PATH=%PATH%;%HADOOP_HOME%/bin;
Что касается меня, мне нужно загрузить winutils с https://github.com/kontext-tech/winutils , поскольку он имеет последнюю версию 3.3.
Важно убедиться, что версия совпадает с версией искры, которую вы загрузили, иначе вы можете найти странные сообщения об ошибках.
И hadoop.dll, и winutils.exe могут находиться в одной папке C:/hadoop/bin. Я не копировал ни в системную папку, и это работает.
Примечание. Я следовал этому , за исключением страниц загрузки инструмента winutils.
У меня все было настроено правильно, но при использовании я указал путь как «/ directory /» вместо «/ directory / *», из-за чего у меня pyspark.SparkContext.wholeTextFilesвозникла эта проблема.
Это может быть старый, но если он все еще не работает для кого-то, Шаг 1. Дважды щелкните winutils.exe. Если он показывает, что какой-то файл DLL отсутствует, загрузите этот файл .dll и поместите его в соответствующее место.
В моем случае отсутствовал файл msvcr100.dll, и мне пришлось установить распространяемый пакет Microsoft Visual C++ 2010 с пакетом обновления 1, чтобы он заработал. Всего наилучшего