Pandas groupby накопленная сумма
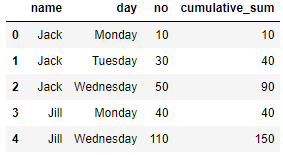
Я хотел бы добавить столбец накопленной суммы в мой фрейм данных Pandas, чтобы:
name | day | no
-----|-----------|----
Jack | Monday | 10
Jack | Tuesday | 20
Jack | Tuesday | 10
Jack | Wednesday | 50
Jill | Monday | 40
Jill | Wednesday | 110
будет выглядеть так:
Jack | Monday | 10 | 10
Jack | Tuesday | 30 | 40
Jack | Wednesday | 50 | 90
Jill | Monday | 40 | 40
Jill | Wednesday | 110 | 150
Я пробовал различные комбинации df.groupby а также df.agg(lambda x: cumsum(x)) но безрезультатно. Заранее спасибо!
8 ответов
Это должно сделать это, нужно groupby() дважды.
In [52]:
print df
name day no
0 Jack Monday 10
1 Jack Tuesday 20
2 Jack Tuesday 10
3 Jack Wednesday 50
4 Jill Monday 40
5 Jill Wednesday 110
In [53]:
print df.groupby(by=['name','day']).sum().groupby(level=[0]).cumsum()
no
name day
Jack Monday 10
Tuesday 40
Wednesday 90
Jill Monday 40
Wednesday 150
Обратите внимание, в результате DataFrame имеет MultiIndex,
Модификация к @ ответу Дмитрия. Это проще и работает в пандах 0.19.0:
print(df)
name day no
0 Jack Monday 10
1 Jack Tuesday 20
2 Jack Tuesday 10
3 Jack Wednesday 50
4 Jill Monday 40
5 Jill Wednesday 110
df['no_csum'] = df.groupby(['name'])['no'].cumsum()
print(df)
name day no no_csum
0 Jack Monday 10 10
1 Jack Tuesday 20 30
2 Jack Tuesday 10 40
3 Jack Wednesday 50 90
4 Jill Monday 40 40
5 Jill Wednesday 110 150
Это работает в пандах 0.16.2
In[23]: print df
name day no
0 Jack Monday 10
1 Jack Tuesday 20
2 Jack Tuesday 10
3 Jack Wednesday 50
4 Jill Monday 40
5 Jill Wednesday 110
In[24]: df['no_cumulative'] = df.groupby(['name'])['no'].apply(lambda x: x.cumsum())
In[25]: print df
name day no no_cumulative
0 Jack Monday 10 10
1 Jack Tuesday 20 30
2 Jack Tuesday 10 40
3 Jack Wednesday 50 90
4 Jill Monday 40 40
5 Jill Wednesday 110 150
Ты должен использовать
df['cum_no'] = df.no.cumsum()
http://pandas.pydata.org/pandas-docs/version/0.19.2/generated/pandas.DataFrame.cumsum.html
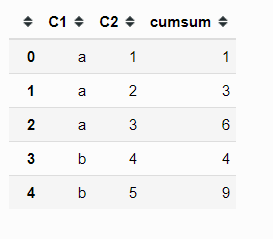
Еще один способ сделать это
import pandas as pd
df = pd.DataFrame({'C1' : ['a','a','a','b','b'],
'C2' : [1,2,3,4,5]})
df['cumsum'] = df.groupby(by=['C1'])['C2'].transform(lambda x: x.cumsum())
df
Вместо df.groupby(by=['name','day']).sum().groupby(level=[0]).cumsum()(см. выше) вы также можете сделать df.set_index(['name', 'day']).groupby(level=0, as_index=False).cumsum()
df.groupby(by=['name','day']).sum()на самом деле просто перемещает оба столбца в MultiIndexas_index=Falseозначает, что вам не нужно вызывать reset_index впоследствии
Data .csv:
name,day,no
Jack,Monday,10
Jack,Tuesday,20
Jack,Tuesday,10
Jack,Wednesday,50
Jill,Monday,40
Jill,Wednesday,110
Код:
import numpy as np
import pandas as pd
df = pd.read_csv('data.csv')
print(df)
df = df.groupby(['name', 'day'])['no'].sum().reset_index()
print(df)
df['cumsum'] = df.groupby(['name'])['no'].apply(lambda x: x.cumsum())
print(df)
Вывод:
name day no
0 Jack Monday 10
1 Jack Tuesday 20
2 Jack Tuesday 10
3 Jack Wednesday 50
4 Jill Monday 40
5 Jill Wednesday 110
name day no
0 Jack Monday 10
1 Jack Tuesday 30
2 Jack Wednesday 50
3 Jill Monday 40
4 Jill Wednesday 110
name day no cumsum
0 Jack Monday 10 10
1 Jack Tuesday 30 40
2 Jack Wednesday 50 90
3 Jill Monday 40 40
4 Jill Wednesday 110 150
начиная с версии 1.0 панды получили новый API для оконных функций.
в частности, то, что было достигнуто ранее с
df.groupby(['name'])['no'].apply(lambda x: x.cumsum())
или
df.set_index(['name', 'day']).groupby(level=0, as_index=False).cumsum()
теперь становится
df.groupby(['name'])['no'].expanding().sum()
Я считаю, что это более интуитивно понятно для всех функций, связанных с окном, чем групповые операции + уровень
хотя научиться использовать groupby полезно для общих целей.
см. документы:https://pandas.pydata.org/docs/user_guide/window.html
Если вы хотите написать однострочный (возможно, вы хотите передать методы в конвейер), вы можете сделать это, сначала установивas_indexпараметрgroupbyдля метода False, чтобы вернуть кадр данных с шага агрегации и использоватьassign()присвоить ему новый столбец (нарастающая сумма для каждого человека).
Эти связанные методы возвращают новый фрейм данных, поэтому вам нужно будет присвоить его переменной (например,agg_df), чтобы иметь возможность использовать его позже.
agg_df = (
# aggregate df by name and day
df.groupby(['name','day'], as_index=False)['no'].sum()
.assign(
# assign the cumulative sum of each name as a new column
cumulative_sum=lambda x: x.groupby('name')['no'].cumsum()
)
)