python joblib & random walk - выполнение планирования [CONCURRENT]-процесса
Вот мой код на python-3.6 для моделирования 1D отраженного случайного блуждания с использованием joblib модуль для генерации 400 реализаций одновременно через K работники на машине кластера Linux.
Я отмечаю, однако, что время выполнения для K=3 хуже чем для K=1 и что время выполнения для K=5 еще хуже!
Может кто-нибудь, пожалуйста, посмотрите способ улучшить мое использование joblib?
from math import sqrt
import numpy as np
import joblib as jl
import os
K = int(os.environ['SLURM_CPUS_PER_TASK'])
def f(j):
N = 10**6
p = 1/3
np.random.seed(None)
X = 2*np.random.binomial(1,p,N)-1 # X = 1 with probability p
s = 0 # X =-1 with probability 1-p
m = 0
for t in range(0,N):
s = max(0,s+X[t])
m = max(m,s)
return m
pool = jl.Parallel(n_jobs=K)
W = np.asarray(pool(jl.delayed(f)(j) for j in range(0,400)))
W
2 ответа
способ улучшить мое использование JobLib?
joblib может помочь и поможет, но только код, который может извлечь выгоду из распределенного выполнения, распределяется по некоторому пулу ресурсов, если затраты на это меньше, чем эффективное ускорение.
Настройка joblib Параметры предварительной загрузки и размера пакета начинают иметь какой-либо смысл только после того, как код, предназначенный для распространения, отрабатывает производительность.
Некоторые усилия в этом направлении, как показано ниже, показали ускорение ~ 8x по достижению еще чисто [SERIAL] время выполнения ~ 217,000 [us] за одну случайную прогулку (вместо ~ 1,640,000 [us] за элемент, как сообщалось выше).
Только после этого может возникнуть некоторая более сложная работа по оптимизации, связанной с ресурсами кластера (усилия по предотвращению опустошения производительности) для постулируемого намерения ab-Definitio организовать распределенный рабочий поток из 400 определенных выше его повторений.
Это имеет смысл, если и только если:
- по возможности избегать процессорного голодания и
- если нет необходимости оплачивать какие-либо чрезмерные дополнительные расходы при распределенном планировании работы.
Возможно, длинная, но важная история о том, где представление будет сохранено или потеряно
УПРАВЛЯЮЩЕЕ РЕЗЮМЕ
Вряд ли
лучшая награда за аргумент доктора Джина AMDAHL:
Внутренняя структура вышеописанной задачи сильно [SERIAL]:
- Генезис случайных чисел является в основном чисто
[SERIAL]процесс, благодаря PRNG-дизайну 1E6итератор на 1D-векторе предварительно опробованных шагов пьяного моряка является чисто[SERIAL]
Да, "внешний" объем работы (400 повторений одного и того же процесса) может быть легко преобразован в "просто"- [CONCURRENT] (не правда- [PARALLEL] даже если профессора и гуру-любители попытаются рассказать вам) планируйте планирование, но дополнительные затраты при этом будут хуже, чем линейно добавленные во время выполнения, и учитывая [SERIAL] Часть не была переработана производительность, чистый эффект от таких усилий может легко разрушить первоначальные благие намерения ( QED выше, так как опубликованные время выполнения выросла из 10:52, за K == 1 к ~ 13 минутам даже для небольшого количества K -с).
Краткое тестирование показало, что после использования стандартных инструментов Python вся задача может быть выполнена в чистом виде. [SERIAL] мода под < 1.45 [s](вместо заявленных ~ 12 - 13 минут) даже на довольно устаревшем настольном устройстве каменного века (некоторый вычислительный эффект в кеше был возможен, хотя и скорее как случайный побочный эффект, чем преднамеренный рефакторинг кода по мотивам HPC для удельная производительность кластера HPC):
u@amd64FX:~$ lstopo --of ascii
+-----------------------------------------------------------------+
| Machine (7969MB) |
| |
| +------------------------------------------------------------+ |
| | Package P#0 | |
| | | |
| | +--------------------------------------------------------+ | |
| | | L3 (8192KB) | | |
| | +--------------------------------------------------------+ | |
| | | |
| | +--------------------------+ +--------------------------+ | |
| | | L2 (2048KB) | | L2 (2048KB) | | |
| | +--------------------------+ +--------------------------+ | |
| | | |
| | +--------------------------+ +--------------------------+ | |
| | | L1i (64KB) | | L1i (64KB) | | |
| | +--------------------------+ +--------------------------+ | |
| | | |
| | +------------++------------+ +------------++------------+ | |
| | | L1d (16KB) || L1d (16KB) | | L1d (16KB) || L1d (16KB) | | |
| | +------------++------------+ +------------++------------+ | |
| | | |
| | +------------++------------+ +------------++------------+ | |
| | | Core P#0 || Core P#1 | | Core P#2 || Core P#3 | | |
| | | || | | || | | |
| | | +--------+ || +--------+ | | +--------+ || +--------+ | | |
| | | | PU P#0 | || | PU P#1 | | | | PU P#2 | || | PU P#3 | | | |
| | | +--------+ || +--------+ | | +--------+ || +--------+ | | |
| | +------------++------------+ +------------++------------+ | |
| +------------------------------------------------------------+ |
| |
+-----------------------------------------------------------------+
+-----------------------------------------------------------------+
| Host: amd64FX |
| Date: Fri 15 Jun 2018 07:08:44 AM |
+-----------------------------------------------------------------+
< 1.45 [s] ?
Зачем? Как? Вот и вся история о... (благодаря усилиям HPC это может сделать намного меньше 1 [с])
Аргумент доктора Джина AMDAHL, даже в его оригинальной, агностической форме надстроек надстроек, в его хорошо процитированном докладе, показал, что любая композиция [SERIAL] а также [PARALLEL] блоки работы будут иметь принципиально ограниченную выгоду от увеличения количества единиц обработки, используемых для [PARALLEL] -part (известный как закон убывающей отдачи, к асимптотически ограниченному ускорению даже для бесконечного числа процессоров), тогда как любое улучшение, внесенное для [SERIAL] -part продолжит аддитивно увеличивать ускорение (чисто линейным способом). Позвольте мне здесь пропустить негативные последствия (также влияющие на ускорение, некоторые в такой же чистой линейной форме, но в неблагоприятном смысле - дополнительные накладные расходы - как они будут обсуждаться ниже).
Шаг № 1:
Восстановите код, чтобы сделать что-то полезное.
учитывая код как есть, случайного блуждания нет вообще.
Зачем?
>>> [ op( np.random.binomial( 1, 1 /3, 1E9 ) ) for op in ( sum, min, max, len ) ]
[0, 0, 0, 1000000000]
Так,
код "как есть" создает довольно дорогой список априорных известных констант. Никакой случайности вообще. Проклятое заклинание питона целочисленного деления. :o)
>>> [ op( np.random.binomial( 1, 1./3., 1E9 ) ) for op in ( sum, min, max, len ) ]
[333338430, 0, 1, 1000000000]
Так что это исправлено.
Шаг № 2:
Поймите накладные расходы (а также лучше всех скрытых блокировщиков производительности)
Любая попытка создания экземпляра распределенного процесса (для каждого из K -количество joblib порожденные процессы, вызывающие multiprocessing с подпроцессом, а не с потоками (backend) заставляет вас платить. Всегда...
При условии,
выполнение вашего кода получит дополнительное [SERIAL] добавочный код, который должен быть запущен, прежде чем ... все еще только теоретический... ( 1 / n_jobs ) эффект разделения может начать происходить.
Присмотритесь к "полезной" работе:
def f( j ): # T0
#pass; np.random.seed( None ) # + ~ 250 [us]
prnGEN = np.random.RandomState() # + ~ 230 [us]
# = 2 * np.random.binomial( 1, 1./3., 1E6 ) - 1 # + ~ 465,000 [us]
X = prnGEN.binomial( 1, 1./3., 1E6 ) # + ~ 393,000
X*= 2 # + ~ 2.940
X-= 1 # + ~ 2.940
s = 0; m = 0 # + ~ 3 [us]
for t in range( 0, int( 1E6 ) ): # ( py3+ does not allocate range() but works as an xrange()-generator
s = max( 0, s + X[t] ) # + ~ 15 [us] cache-line friendly consecutive { hit | miss }-rulez here, heavily ...
m = max( m, s ) # + ~ 5 [us]
return m # = ~ 2,150,000 [us] @ i5/2.67 GHz
# # = ~ 1,002,250 [us] @ amd/3.6 GHz
Для такого рода рабочих пакетов лучшие демонстрационные ускорения будут демонстрироваться с помощью неинтерпретируемого потокового бэкэнда без GIL, multiprocessing.Pool порожденные Cython-ised кодовые пакеты, cdef с nogil директивы. Можно ожидать такого выполнения кода под примерно = ~ 217,000 [us] за одну чистую [SERIAL] Случайная прогулка, с 1E6 шаги, когда начинает иметь смысл использовать пул узлов выполнения кода с некоторой настройкой перед загрузкой, чтобы не дать им голодать. Тем не менее, все предупреждения преждевременной оптимизации являются обязательными и действительными в этом упрощенном контексте, и для достижения результата профессионального уровня должны использоваться надлежащие методы проектирования.
Некоторые инструменты могут помочь вам увидеть, до уровня сборки, сколько инструкций было фактически добавлено любым соответствующим элементом синтаксического конструктора языка высокого уровня (или маскарадами параллелизации / параллелизации #pragma), чтобы "понюхать" эти надстройки Затраты на оплату при окончательном выполнении кода:
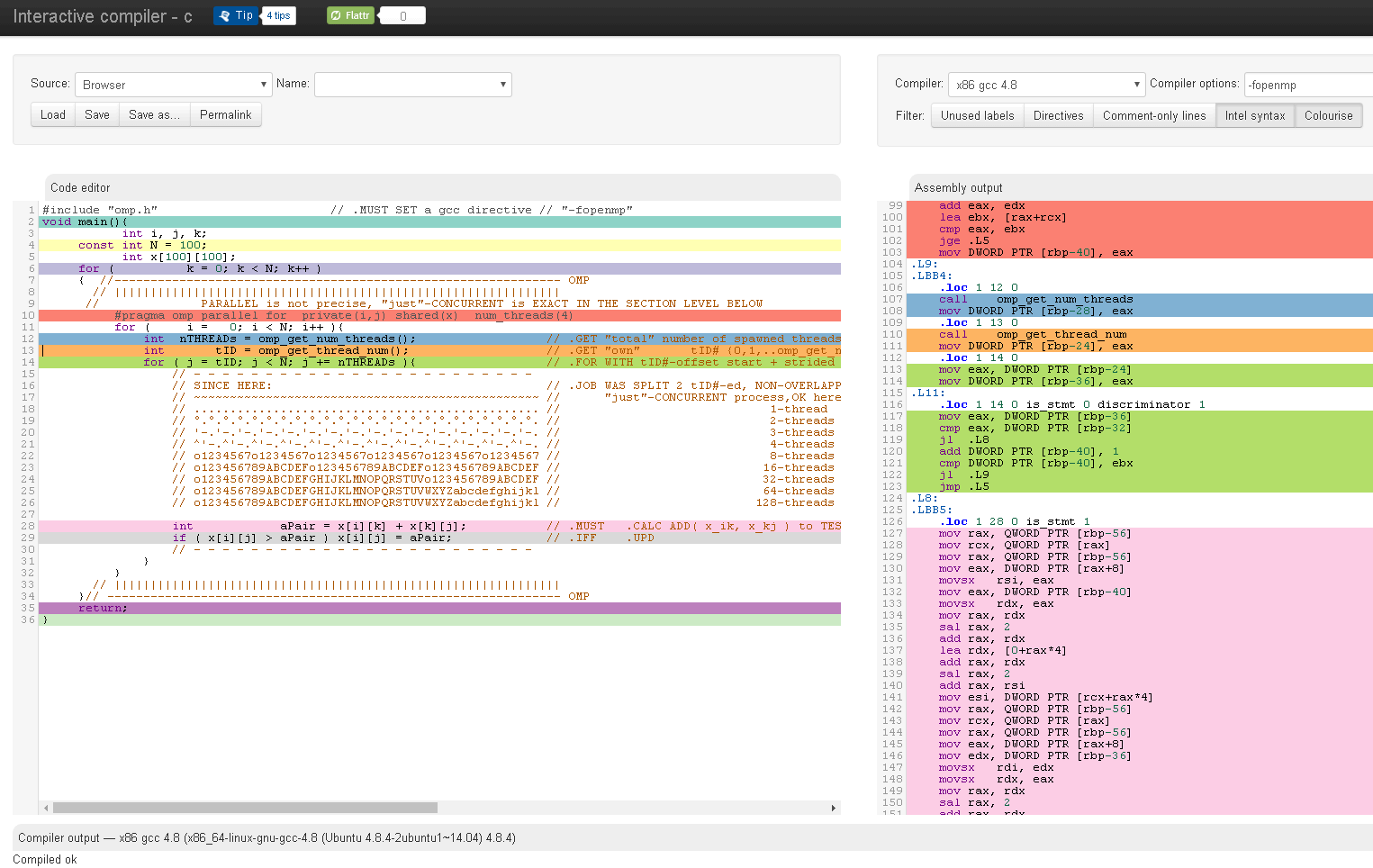
Учитывая эти дополнительные затраты на обработку, "небольшое" (тонкое) количество работы "внутри" "просто", выполняемого одновременно (остерегайтесь, автоматическое планирование [PARALLEL] не возможно), эти дополнительные расходы может заставить вас заплатить больше, чем вы получили бы от раскола.
Блокаторы:
Любая дополнительная связь / синхронизация может дополнительно разрушить теоретическое ускорение выполнения кода. Блокировки, GIL избегаются, если не используется потоковый бэкэнд, семафоры, сокеты, совместное использование и т. Д. Являются общими блокировщиками.
Для тщательно спроектированного источника случайности любой отбор из такого "устройства" также должен быть центрально синхронизирован, чтобы сохранить качество такой случайности. Это может вызвать дополнительные проблемы за кулисами (распространенная проблема в системах с некоторыми авторитетными сертифицированными источниками случайности).
Следующий шаг?
Узнайте больше о Законе Амдала, лучше всего о современной переформулированной версии, в которой добавлены накладные расходы на установку и завершение в режиме строгих издержек, а также была учтена атомарность обработки для практической оценки реалистичных ограничений ускорения
Далее: измерьте ваши чистые затраты на длительность вашего кода, и вы косвенно получите дополнительные затраты на установку + накладные расходы на завершение работы вашей системы in vivo.
def f( j ):
ts = time.time()
#------------------------------------------------------<clock>-ed SECTION
N = 10**6
p = 1./3.
np.random.seed( None ) # RandomState coordination ...
X = 2 * np.random.binomial( 1, p, N ) - 1 # X = 1 with probability p
s = 0 # X =-1 with probability 1-p
m = 0
for t in range( 0, N ):
s = max( 0, s + X[t] )
m = max( m, s )
#------------------------------------------------------<clock>-ed SECTION
return ( m, time.time() - ts ) # tuple
Для учебных занятий я успешно распараллелил свой код случайного блуждания, используя специальные модули в R, Matlab, Julia & Stata. (Под словом "успешно" я подразумеваю, что совершенно очевидно, что 20 рабочих выполняют по крайней мере в 10 раз больше работы, чем 1 рабочий за тот же промежуток времени.) Разве такая внутренняя распараллеливание невозможна в Python?
Что ж, последний комментарий, похоже, отображает какие-то неудобства для людей, которые пытались помочь и которые привели причины, почему размещенный код, как есть, работает так, как было замечено. Это был не наш выбор, чтобы точно определить стратегию обработки, не так ли?
Так,
снова.
Учитывая первоначальное решение было
использование python-3.6 + joblib.Parallel() + joblib.delayed() приборы, просто Alea Iacta Est ...
Что могло бы сработать (как указано) для { R | MATLAB | Юлия | Stata } просто не означает, что он будет работать так же, как в GIL-step, тем меньше joblib.Parallel() порожденные экосистемы.
Первая цена ВСЕГДА будет платить за joblib.Parallel() порожденная работа - это стоимость восстановления всей копии 1:1 текущего состояния интерпретатора Python. Учитывая, что текущее состояние содержит куда больше экземпляров объекта, чем урезанный MCVE-код (как было продемонстрировано для MCVE-скрипта python2.x, как продемонстрировал @rth), весь образ памяти, многократно реплицируемый сначала нужно скопировать + перевезти + перестроить на все узлы распределенной обработки, в соответствии с управляемым SLURM размером кластера, что требует дополнительных (непроизводительных) накладных расходов. Если вы сомневаетесь, добавьте несколько numpy-массивов размером в ГБ в состояние интерпретатора python и поместите измеренные временные метки для соответствующих вычислений длительности в первую и последнюю ячейки массива и, наконец, return ( m, aFatArray ), Общее время выполнения увеличится, поскольку как исходная копия 1:1, так и путь возврата должны будут перемещать куда больший объем данных туда и обратно (опять же, для подробностей о затратах, связанных с созданием экземпляров, были размещены здесь во многих местах, включая шаблоны для систематического сравнительного анализа соответствующих дополнительных расходов).
Именно это и послужило причиной для того, чтобы посоветовать типу O/P действительно измерить эффективное количество вычислительного времени (часть "выгоды" элементарного аргумента "затраты / выгода"), и то, и другое дешево получить в тривиальном эксперименте, который будет покажите масштаб, сумму и фактическую пропорцию полезной работы внутри "удаленных" эффективных полезных вычислений полезных нагрузок (см. модификацию кода, предложенную выше, которая возвращает значения так, чтобы W[:][1] сообщит фактические "чистые" вычислительные затраты на " полезную работу ", потраченную в течение времени вычисления эффективного рабочего пакета, как только они наконец будут получены и активированы в соответствующих "удаленных" экосистемах выполнения кода (здесь, в форме joblib.Parallel() порожденные двоичные полномасштабные реплики исходного интерпретатора Python), в то время как поток времени между началом и концом выполнения основного кода показывает фактические затраты - здесь единовременно потраченное количество времени, т.е. включая все "удаленные"- процесс-экземпляр (ы) + все соответствующие рабочие пакеты -распределение (я) + все "удаленное"-процесс-завершение.
Последнее замечание для тех,
кто не потратил время на чтение
о проблемах, связанных с источником случайности:
Любая хорошая практика должна избегать логики блокировки, скрытой за "общей случайностью". Лучше использовать индивидуально настроенные PRNG-источники. Если вы заинтересованы или нуждаетесь в сертифицированной PRNG-надежности, не стесняйтесь читать больше об этом в обсуждении здесь
@user3666197 написал очень хороший ответ о накладных расходах, с большим количеством выделенного текста;) Однако я хочу обратить ваше внимание, что когда вы запускаете свой код с K=1, вы делаете только один случайный обход. С K=3 или 5 вы выполняете 3 или 5 случайных прогулок одновременно (кажется). Таким образом, вам нужно умножить время выполнения K = 1 на 3 или 5, чтобы получить время выполнения, которое требуется для выполнения той же работы. Я думаю, что это время выполнения будет намного больше, чем вы получили.
Ну, чтобы дать полезный ответ, а не просто заметку (ОП прямо в комментариях). Кажется multiprocessing модуль является лучшим выбором. Вот твой код
from math import sqrt
import numpy as np
from multiprocessing import Pool
import os
K = int(os.environ['NTASK'])
def f(j):
N = 10**6
p = 1./3.
np.random.seed(None)
X = 2*np.random.binomial(1,p,N)-1 # X = 1 with probability p
s = 0 # X =-1 with probability 1-p
m = 0
for t in range(0,N):
s = max(0,s+X[t])
m = max(m,s)
return m
pool = Pool(processes=K)
print pool.map(f, xrange(40))
и производительность
$ time NTASK=1 python stof.py
[21, 19, 17, 17, 18, 16, 17, 17, 19, 19, 17, 16, 18, 16, 19, 22, 20, 18, 16, 17, 17, 16, 18, 18, 17, 17, 19, 17, 19, 19, 16, 16, 18, 17, 18, 18, 19, 20, 16, 19]
real 0m30.367s
user 0m30.064s
sys 0m 0.420s
$ time NTASK=2 python stof.py
[18, 16, 16, 17, 19, 17, 21, 18, 19, 21, 17, 16, 15, 25, 19, 16, 20, 17, 15, 19, 17, 16, 20, 17, 16, 16, 16, 16, 17, 23, 17, 16, 17, 17, 19, 16, 17, 16, 19, 18]
real 0m13.428s
user 0m26.184s
sys 0m 0.348s
$ time NTASK=3 python stof.py
[18, 17, 16, 19, 17, 18, 20, 17, 21, 16, 16, 16, 16, 17, 22, 18, 17, 15, 17, 19, 18, 16, 15, 16, 16, 24, 20, 16, 16, 16, 22, 19, 17, 18, 18, 16, 16, 19, 17, 18]
real 0m11.946s
user 0m29.424s
sys 0m 0.308s
$ time NTASK=4 python stof.py
[16, 19, 17, 16, 19, 17, 17, 16, 18, 22, 16, 21, 16, 18, 15, 16, 20, 17, 22, 17, 16, 17, 17, 20, 22, 21, 17, 17, 16, 17, 19, 16, 19, 16, 16, 18, 25, 21, 19, 18]
real 0m 8.206s
user 0m26.580s
sys 0m 0.360s