Sql Server 2008 R2 DC вносит изменения в производительность
Я заметил интересное изменение производительности, которое происходит около 1,5 миллиона введенных значений. Может кто-нибудь дать мне хорошее объяснение, почему это происходит?
Стол очень прост. Он состоит из (bigint, bigint, bigint, bool, varbinary(max)). У меня есть индекс pk clusered для первых трех bigints. Я вставляю только логическое "true" в качестве данных varbinary(max).
С этого момента производительность кажется довольно постоянной.
Легенда: Y (Время в мс) | X (вставки 10K)
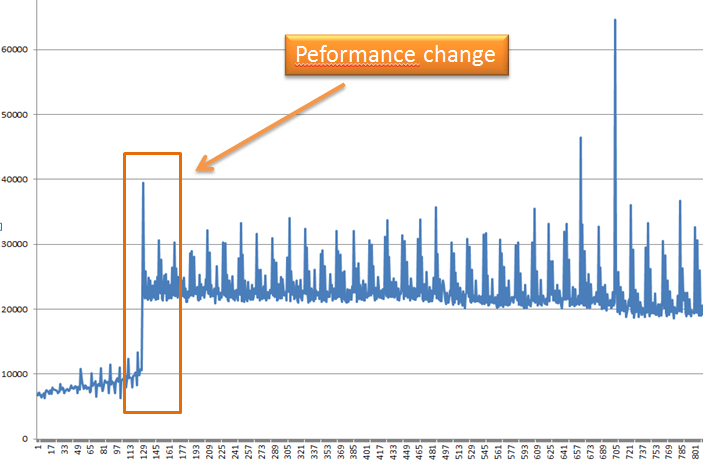
Я также интересуюсь постоянными относительно маленькими (иногда очень большими) шипами, которые есть на графике.
Фактический план выполнения до шипов.

Условные обозначения:
Таблица, которую я вставляю в: TSMDataTable
1. BigInt DataNodeID - фк
2. BigInt TS - основная отметка времени
3. BigInt CTS - модификация метки времени
4. Бит: ICT - ведет запись последнего введенного значения (увеличивает производительность чтения)
5. Данные: данные
Bool value Текущее время сохраняет отметку
Enviorment
Это местный.
Он не делится никакими ресурсами.
Это база данных фиксированного размера (достаточно, чтобы она не расширялась).
(Компьютер, 4 ядра, 8 ГБ, 7200rps, Win 7).
(Sql Server 2008 R2 DC, сходство процессоров (ядро 1,2), 3 ГБ,)
1 ответ
Вы проверили план выполнения, когда время идет? План может меняться в зависимости от статистики. Поскольку ваши данные быстро растут, статистика изменится, и это может вызвать другой план выполнения.
Вложенные циклы хороши для небольших объемов данных, но, как вы можете видеть, время увеличивается с увеличением объема. Тогда оптимизатор SQL-запросов, вероятно, переключается на план хеширования или слияния, который подходит для больших объемов данных.
Чтобы быстро подтвердить эту теорию, попробуйте отключить автоматическое обновление статистики и снова запустить тест. Вы не должны видеть "удар" тогда.
РЕДАКТИРОВАТЬ: Так как Falcon подтвердил, что производительность изменилась из-за статистики, мы можем разработать следующие шаги.
Я полагаю, вы делаете одну за другой, правильно? В этом случае (если вы не можете вставлять массовые данные), вам будет гораздо лучше вставлять их в рабочую таблицу кучи, а затем через равные промежутки времени перемещать массовые строки в целевую таблицу. Это связано с тем, что для каждой вставленной строки SQL должен проверять дубликаты ключей, внешние ключи и другие проверки, а также сортировать и разбивать страницы все время. Если вы можете позволить себе отложить эти проверки немного позже, я думаю, вы получите превосходную производительность вставки.
Я использовал этот метод для регистрации метрик. Ведение журнала будет происходить в виде простой таблицы кучи без индексов, внешних ключей и проверок. Каждые десять минут я создаю новую таблицу такого рода, затем с двумя sp_rename внутри транзакции (swift swap) я делаю полную таблицу доступной для обработки, и новая таблица принимает запись в журнал. Тогда вы можете спокойно выполнять всю проверку, сортировку, разбиение всего один раз.
Кроме того, я не уверен, как улучшить вашу ситуацию. Вам, безусловно, необходимо регулярно обновлять статистику, поскольку это является ключом к хорошей производительности в целом.
Можно попробовать использовать кластеризованный ключ с одним столбцом и дополнительный уникальный индекс для этих трех столбцов, но я сомневаюсь, что это сильно поможет.
Можно попробовать заполнить индексы - если ваши вставленные данные не являются последовательными. Это устранит чрезмерное разбиение страницы, перетасовку и фрагментацию. Вам необходимо регулярно поддерживать заполнение, что может потребовать перерыва.
Может быть, попытаться дать ему обновление HW. Вам необходимо выяснить, какой компонент является узким местом. Это может быть процессор или диск - мой любимый в этом случае. Память вряд ли имхо если у вас по одной вставки. Тогда это должно быть легко, если это не процессор (линия, висящая сверху графика), то, скорее всего, ваш ввод-вывод сдерживает вас. Попробуйте лучший контроллер, лучше кэшированный и более быстрый диск...