Когда использовать SortedList<TKey, TValue> поверх SortedDictionary<TKey, TValue>?
Это может показаться дубликатом этого вопроса, который спрашивает: "В чем разница между SortedList и SortedDictionary?" К сожалению, ответы не более чем цитируют документацию MSDN (в которой четко указано, что между ними есть различия в производительности и использовании памяти), но на самом деле не отвечают на вопрос.
На самом деле (и поэтому на этот вопрос нет одинаковых ответов), согласно MSDN:
SortedList<TKey, TValue>универсальный класс - это двоичное дерево поиска с O(log n) поиском, где n - количество элементов в словаре. В этом он похож наSortedDictionary<TKey, TValue>родовой класс. Два класса имеют похожие объектные модели, и оба имеют O(log n) извлечения. Эти два класса различаются в использовании памяти и скорости вставки и удаления:
SortedList<TKey, TValue>использует меньше памяти, чемSortedDictionary<TKey, TValue>,
SortedDictionary<TKey, TValue>имеет более быстрые операции вставки и удаления для несортированных данных, O(log n) в отличие от O(n) дляSortedList<TKey, TValue>,Если список заполняется сразу из отсортированных данных,
SortedList<TKey, TValue>быстрее чемSortedDictionary<TKey, TValue>,
Итак, ясно, что это указывало бы на то, что SortedList<TKey, TValue> это лучший выбор, если вам не нужны более быстрые операции вставки и удаления несортированных данных.
Вопрос по-прежнему остается, учитывая приведенную выше информацию, каковы практические (в реальных условиях, бизнес-кейс и т. Д.) Причины использования SortedDictionary<TKey, TValue>? Основываясь на информации о производительности, это будет означать, что на самом деле нет необходимости иметь SortedDictionary<TKey, TValue> совсем.
6 ответов
Я не уверен, насколько точна документация MSDN SortedList а также SortedDictionary, Кажется, говорят, что оба реализованы с использованием бинарного дерева поиска. Но если SortedList использует бинарное дерево поиска, почему он будет намного медленнее при добавлении, чем SortedDictionary?
Во всяком случае, вот некоторые результаты теста производительности.
Каждый тест работает на SortedList / SortedDictionary содержащий 10000 ключей int32. Каждый тест повторяется 1000 раз (Выпуск сборки, Запуск без отладки).
К первой группе тестов добавляются ключи в последовательности от 0 до 9999. Вторая группа тестов добавляет случайные тасованные ключи от 0 до 9999 (каждое число добавляется ровно один раз).
***** Tests.PerformanceTests.SortedTest
SortedDictionary Add sorted: 4411 ms
SortedDictionary Get sorted: 2374 ms
SortedList Add sorted: 1422 ms
SortedList Get sorted: 1843 ms
***** Tests.PerformanceTests.UnsortedTest
SortedDictionary Add unsorted: 4640 ms
SortedDictionary Get unsorted: 2903 ms
SortedList Add unsorted: 36559 ms
SortedList Get unsorted: 2243 ms
Как и при любом профилировании, важна относительная производительность, а не фактические цифры.
Как вы можете видеть, на отсортированных данных отсортированный список быстрее, чем SortedDictionary, По несортированным данным SortedList немного быстрее при поиске, но примерно в 9 раз медленнее при добавлении.
Если оба используют двоичные деревья для внутреннего использования, то довольно удивительно, что операция Add для несортированных данных выполняется намного медленнее. SortedList, Возможно, что отсортированный список может также добавлять элементы в отсортированную линейную структуру данных в одно и то же время, что замедлит его.
Тем не менее, вы ожидаете, что использование памяти SortedList быть равным или большим или, по меньшей мере, равным SortedDictionary, Но это противоречит тому, что говорится в документации MSDN.
Я не знаю, почему MSDN говорит, что SortedList<TKey, TValue> использовать двоичное дерево для его реализации, потому что если вы посмотрите на код с помощью декомпилятора, как Reflector ты понимаешь, что это неправда.
SortedList<TKey, TValue> это просто массив, который растет со временем.
Каждый раз, когда вы вставляете элемент, он сначала проверяет, достаточно ли массива, если нет, то массив большего размера воссоздается и старые элементы копируются в него (например, List<T>)
После этого он ищет, куда вставить элемент, используя двоичный поиск (это возможно, поскольку массив индексируется и уже отсортирован).
Чтобы сохранить массив отсортированным, он перемещает (или толкает) все элементы, расположенные после позиции элемента, которая будет вставлена на одну позицию (используя Array.Copy()).
Например:
// we want to insert "3"
2
4 <= 3
5
8
9
.
.
.
// we have to move some elements first
2
. <= 3
4
5 |
8 v
9
.
.
Это объясняет, почему производительность SortedList так плохо, когда вы вставляете несортированные элементы. Он должен повторно копировать некоторые элементы почти каждую вставку. Единственный случай, когда это не нужно делать, это когда элемент должен быть вставлен в конец массива.
SortedDictionary<TKey, TValue> отличается и использовать двоичное дерево для вставки и извлечения элементов. Это также имеет определенную стоимость при вставке, потому что иногда дерево необходимо перебалансировать (но не каждую вставку).
Производительность очень похожа при поиске элемента с SortedList или же SortedDictionary потому что они оба используют бинарный поиск.
На мой взгляд, вы никогда не должны использовать SortedList просто отсортировать массив. Если у вас мало элементов, всегда будет быстрее вставить значения в список (или массив) и затем вызвать Sort() метод.
SortedList в основном полезно, когда у вас есть список значений, которые уже отсортированы (например, из базы данных), вы хотите сохранить его отсортированным и выполнить некоторые операции, которые могли бы использовать преимущества его сортировки (например: Contains() метод SortedList выполняет бинарный поиск вместо линейного поиска)
SortedDictionary предлагает те же преимущества, что и SortedList но работает лучше, если значения для вставки еще не отсортированы.
РЕДАКТИРОВАТЬ: если вы используете.NET Framework 4.5, альтернатива SortedDictionary<TKey, TValue> является SortedSet<T>, Это работает так же, как SortedDictionary, используя двоичное дерево, но ключи и значения здесь одинаковы.
Они предназначены для двух разных целей?
Семантическая разница между этими двумя типами коллекций в.NET невелика. Они оба предлагают поиск по ключам, а также сохраняют записи в порядке сортировки ключей. В большинстве случаев вы будете в порядке с любым из них. Возможно, единственным отличием будет индексированный поиск SortedList разрешения.
Но производительность?
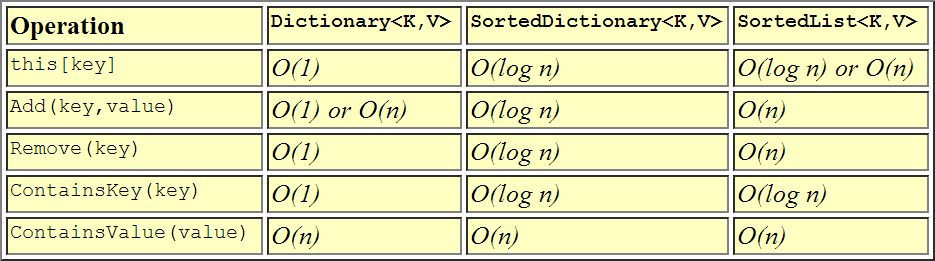
Однако есть разница в производительности, которая может быть более сильным фактором для выбора между ними. Вот табличное представление об их асимптотической сложности.
+------------------+---------+----------+--------+----------+----------+---------+
| Collection | Indexed | Keyed | Value | Addition | Removal | Memory |
| | lookup | lookup | lookup | | | |
+------------------+---------+----------+--------+----------+----------+---------+
| SortedList | O(1) | O(log n) | O(n) | O(n)* | O(n) | Lesser |
| SortedDictionary | n/a | O(log n) | O(n) | O(log n) | O(log n) | Greater |
+------------------+---------+----------+--------+----------+----------+---------+
* Insertion is O(1) for data that are already in sort order, so that each
element is added to the end of the list (assuming no resize is required).
Резюме
Подводя итог, вы хотите SortedList<K, V> когда:
- Вам требуется индексированный поиск.
- желательно иметь меньшие накладные расходы памяти.
- Ваши входные данные уже отсортированы (скажем, вы уже заказали их в БД).
Вместо этого вы бы предпочли SortedDictionary<K, V> когда:
- Относительная общая производительность имеет значение (в отношении масштабирования).
- Ваши входные данные неупорядочены.
Написание кода
И то и другое SortedList<K, V> а также SortedDictionary<K, V> воплощать в жизнь IDictionary<K, V>, так что в вашем коде вы можете вернуть IDictionary<K, V> из метода или объявить переменную как IDictionary<K, V>, В основном скрывают детали реализации и код от интерфейса.
IDictionary<K, V> x = new SortedDictionary<K, V>(); //for eg.
В будущем его будет легче переключать на случай, если вас не устраивают характеристики, характерные для одной коллекции.
Для получения дополнительной информации о двух типах коллекций см. Исходный связанный вопрос.
Это все, что нужно сделать. Извлечение ключей сравнимо, но добавление происходит гораздо быстрее со словарями.
Я стараюсь максимально использовать SortedList, потому что он позволяет перебирать ключи и коллекции значений. Насколько я знаю, это невозможно с SortedDictionary.
Я не уверен в этом, но, насколько мне известно, словари хранят данные в древовидных структурах, тогда как List хранит данные в линейных массивах. Это объясняет, почему с помощью словарей вставка и удаление выполняются намного быстрее, поскольку требуется меньше памяти. Это также объясняет, почему вы можете перебирать SortedLists, но не SortedDictionary.
Для нас важным моментом является тот факт, что у нас часто есть небольшие словари (<100 элементов), и современные процессоры гораздо быстрее обращаются к последовательной памяти, выполняя несколько трудных для прогнозирования ветвей. (т. е. итерация по линейному массиву, а не обход дерева). Поэтому, когда в вашем словаре менее 60 элементов, SortedList<> часто является самым быстрым и наиболее эффективным по памяти словарем во многих случаях использования.