Сортировка по группам в rpivottable
У меня есть rpivottable сгенерированный с помощью этого кода благодаря rpivotTable пакет в R:
library("rpivotTable")
library("dplyr")
library("reshape2")
dane <- melt(HairEyeColor)
rpivotTable(dane,
rows = c("Hair", "Eye"),
cols = c("Sex"),
vals = "value",
aggregatorName = "Integer Sum",
locale = "en",
rendererName = "Table With Subtotal",
subtotals = TRUE)
который выглядит так:
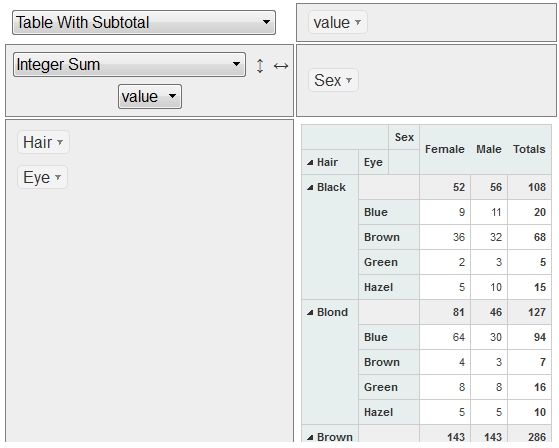
Сортируется по алфавиту. И я хотел бы отсортировать его в порядке убывания, используя общую сумму значений.
Я могу попробовать вот что:
library("rpivotTable")
library("dplyr")
library("reshape2")
dane <- melt(HairEyeColor)
sorter <- paste0("function(attr) {",
"var sortAs = $.pivotUtilities.sortAs;",
"if (attr == \"Eye\") { return sortAs([\"",
dane %>% group_by(Eye) %>% summarise(i = sum(value)) %>% arrange(-i) %>% .$Eye %>% paste(collapse = "\", \""),
"\"]); }",
"if (attr == \"Hair\") { return sortAs([\"",
dane %>% group_by(Hair) %>% summarise(i = sum(value)) %>% arrange(-i) %>% .$Hair %>% paste(collapse = "\", \""),
"\"]); }",
"}")
rpivotTable(dane,
rows = c("Hair", "Eye"),
cols = c("Sex"),
vals = "value",
aggregatorName = "Integer Sum",
locale = "en",
rendererName = "Table With Subtotal",
subtotals = TRUE,
sorters = sorter)
Чем я получаю это:
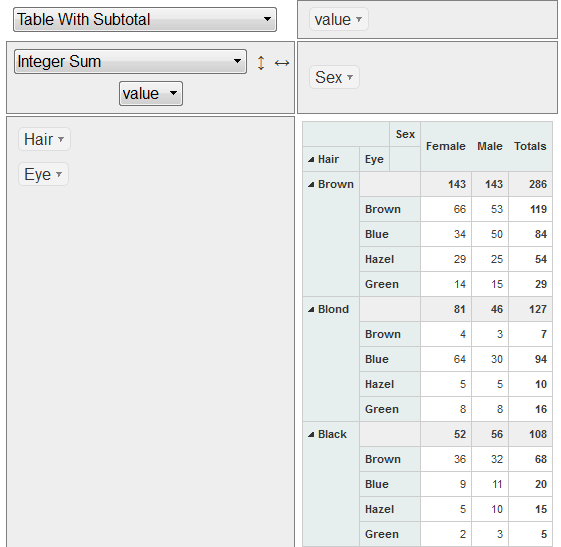
и это отсортировано по "внешней" группе. И я хотел бы, чтобы он был отсортирован по обеим группам, как здесь:
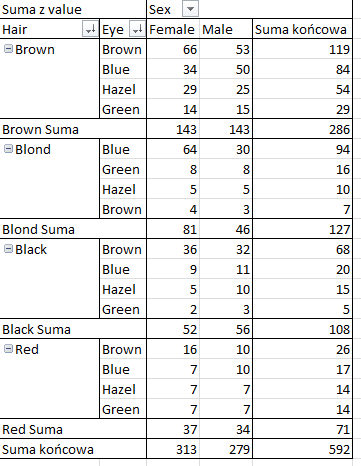
Это возможно в rpivotTable пакет?
0 ответов
Я мог бы узнать больше из вашего вопроса, чем вы узнали из моего ответа, потому что мне понравилось ваше умное сочетание dplyr и JavaScript. Чтобы сформулировать проблему еще раз, вы указываете один список сортировки по глазам в своей функции сортировки, но вам действительно нужен другой список сортировки по глазам в зависимости от группировки волос. Итак, ваш список сортировки глаз:
library("dplyr")
library("reshape2")
dane <- melt(HairEyeColor)
dane %>% group_by(Eye) %>% summarise(i = sum(value)) %>%
arrange(-i) %>% .$Eye %>% paste(collapse = "\", \"")
... имеет этот вывод:
"Brown\", \"Blue\", \"Hazel\", \"Green"
... и такой же порядок сортировки используется в каждой группе волос. См. Также этот ответ.
Я не эксперт в сводных таблицах, но, чтобы делать то, что вы хотите, я думаю, что функция сортировщика должна обрабатывать два атрибута, например [\"Hair\", \"Eye\"], а не только один. Я считаю, что такое выражение dplyr приведет вас к правильному результирующему двумерному списку:
dane %>% group_by(Hair, Eye) %>%
summarise(hairEyeSum = sum(value)) %>%
ungroup() %>%
arrange( desc(hairEyeSum)) %>%
group_by( Hair) %>%
mutate( hairSum = sum(hairEyeSum)) %>%
arrange( desc(hairSum), desc(hairEyeSum)) %>%
ungroup() %>%
transmute( hairEyeList = paste0( "[\"", Hair, "\",\"", Eye, "\"]"))
Выход:
# A tibble: 16 x 1
hairEyeList
<chr>
1 "[\"Brown\",\"Brown\"]"
2 "[\"Brown\",\"Blue\"]"
3 "[\"Brown\",\"Hazel\"]"
4 "[\"Brown\",\"Green\"]"
5 "[\"Blond\",\"Blue\"]"
6 "[\"Blond\",\"Green\"]"
7 "[\"Blond\",\"Hazel\"]"
8 "[\"Blond\",\"Brown\"]"
9 "[\"Black\",\"Brown\"]"
10 "[\"Black\",\"Blue\"]"
11 "[\"Black\",\"Hazel\"]"
12 "[\"Black\",\"Green\"]"
13 "[\"Red\",\"Brown\"]"
14 "[\"Red\",\"Blue\"]"
15 "[\"Red\",\"Hazel\"]"
16 "[\"Red\",\"Green\"]"
Но мне не удалось заставить работать функцию сортировщика.