Извлечение многострочного контента из содержимого потокового файла
Я импортирую данные из таблицы MySQL (только для выбранных столбцов) и помещаю их в HDFS. Как только это будет сделано, я хочу создать таблицу в Hive.
Для этого у меня есть schema.sql файл, который содержит инструкцию CREATE TABLE для всей таблицы, и я хочу создать новую инструкцию CREATE TABLE только для столбцов, которые я импортировал.
Нечто похожее на то, что я делаю с grep в приведенном ниже примере.

я использовал FetchFile вместе с ExtractText но не мог заставить это работать. Как я могу добиться этого, используя процессоры NiFi или даже Expression Language, если я получу общую схему в атрибут?
Или есть лучший способ создать таблицу на импортируемых данных?
1 ответ
NiFi может генерировать операторы Создать таблицу на основе содержимого потокового файла
1.Создание таблиц ORC с использованием процессора ConvertAvroToORC:
если вы конвертируете данные avro в формат ORC, а затем сохраняете их в HDFS, то процессор ConvertAvroToORC добавляет
hive.ddlприписать файл потока.PutHDFS процессор добавляет
absolute.hdfs.pathприписать файл потока.Мы можем использовать эти атрибуты hive.ddl, absolute.hdfs.path и динамически создавать таблицу orc поверх каталога HDFS.
Поток:
Pull data from source(ExecuteSQL...etc)
-> ConvertAvroToORC //add Hive DbName,TableName in HiveTableName property value-->
-> PutHDFS //store the orc file into HDFS location -->
-> ReplaceText //Replace the flowfile content with ${hive.ddl} Location '${absolute.hdfs.path}'-->
-> PutHiveQL //execute the create table statement
Обратитесь к этой ссылке для более подробной информации о приведенном выше потоке.
2.Создание таблиц Avro с использованием процессора ExtractAvroMetaData:
В NiFi, как только мы извлекаем данные, используя QueryDatabaseTable, процессоры ExecuteSQL формат данных находится в AVRO.
Мы можем создавать таблицы Avro на основе схемы avro (файл.avsc), и с помощью процессора ExtractAvroMetaData мы можем извлечь схему и сохранить ее в качестве атрибута потока, а затем с помощью этой схемы мы можем динамически создавать таблицы AvroTable.
Поток:
ExecuteSQL (success)|-> PutHDFS //store data into HDFS
(success)|-> ExtractAvroMetadata //configure Metadata Keys as avro.schema
-> ReplaceText //replace flowfile content with avro.schema
-> PutHDFS //store the avsc file into schema directory
-> ReplaceText //create avro table on top of schema directory
-> PutHiveQL //execute the hive.ddl
Пример AVRO создания таблицы оператора:
CREATE TABLE as_avro
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED as INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.url'='/path/to/the/schema/test_serializer.avsc');
Мы собираемся изменить путь к URL схемы с помощью процессора ReplaceText в вышеупомянутом потоке.
Другой способ, используя процессор ExecuteSQL, получить всю информацию о столбцах операторов таблицы (или) из (sys.tables/INFORMATION_SCHEMA.COLUMNS ..etc) из источника (если позволяет исходная система) и написать сценарий для map the data types в hive appropriate types затем храните их в своем desired format в улье.
РЕДАКТИРОВАТЬ:
Бежать grep Команда на содержимое файла потока нам нужно использовать процессор ExecuteStreamCommand
ESC Configs:
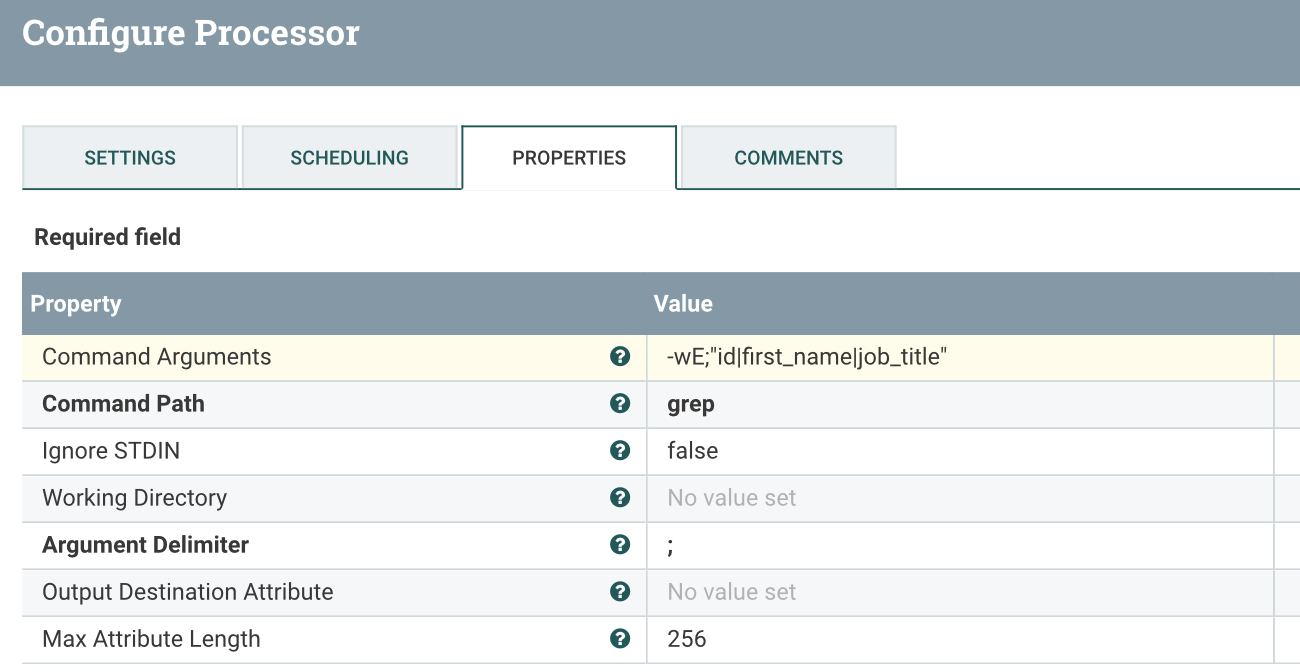
Тогда кормите output stream отношение к процессору ExtractText
ET Configs:
Добавить новое свойство как
содержание
(?s)(.*)
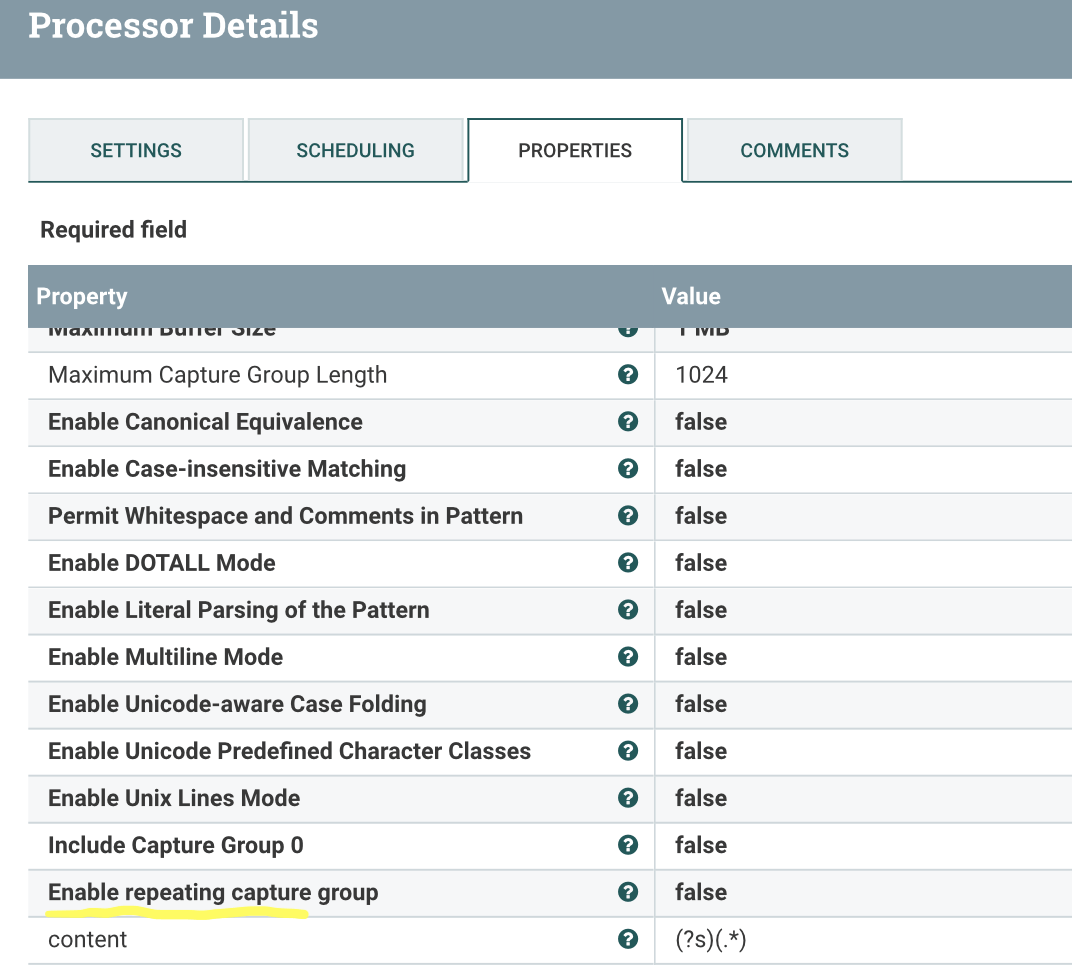
затем content attribute добавлен в файл потока. Вы можете использовать этот атрибут и подготовить операторы создания таблицы.