Преобразование рекурсивного шаблона регулярных выражений PCRE в определение групп балансировки.NET
PCRE имеет функцию, называемую рекурсивным шаблоном, которая может использоваться для сопоставления вложенных подгрупп. Например, рассмотрим "грамматику"
Q -> \w | '[' A ';' Q* ','? Q* ']' | '<' A '>'
A -> (Q | ',')*
// to match ^A$.
Это может быть сделано в PCRE с рисунком
^((?:,|(\w|\[(?1);(?2)*,?(?2)*\]|<(?1)>))*)$
(Пример тестового примера: http://www.ideone.com/L4lHE)
Должно совпадать:
abcdefgabc,def,ghiabc,,,def,,,,,,[abc;][a,bc;]sss[abc;d]as[abc;d,e][abc;d,e][fgh;j,k]<abc>[<a>b;<c,d>,<e,f>]<a,b,c><a,bb,c><,,,><><><><>,<>a<<<<>>><a>><<<<<>>>><><<<>>>><z>[a;b]<z[a;b]>[[;];][,;,][;[;]][<[;]>;<[;][;,<[;,]>]>]
Не должно совпадать:
<abc><abc<de>[a<b;c>;d,e][a]<<<<<>>>><><<<>>>>><<<<<>>>><><<<>>>[abc;def;][[;],][;,,][abc;d,e,f][<[;]>;<[;][;,<[;,]>]]><z[a;b>]
В.NET нет рекурсивного шаблона. Вместо этого он обеспечивает балансировочные группы для стековых манипуляций для сопоставления простых вложенных шаблонов.
Можно ли преобразовать вышеуказанный шаблон PCRE в стиль.NET Regex?
(Да, я знаю, для этого лучше не использовать регулярные выражения. Это просто теоретический вопрос.)
Рекомендации
2 ответа
Альтернативой.Net рекурсивному шаблону является стек. Проблема здесь в том, что нам нужно выразить грамматику в терминах стеков.
Вот один из способов сделать это:
Немного другое обозначение для грамматики
- Во-первых, нам нужны грамматические правила (например,
Aа такжеQв вопросе). - У нас есть один стек. Стек может содержать только правила.
- На каждом шаге мы извлекаем текущее состояние из стека, сопоставляем то, что нам нужно, и помещаем дополнительные правила в стек. Когда мы закончим с состоянием, мы ничего не нажимаем и не возвращаемся в предыдущее состояние.
Эта запись находится где-то между CFG и автоматом Pushdown, где мы помещаем правила в стек.
Пример:
Давайте начнем с простого примера: a n b n. Обычная грамматика для этого языка:
S -> aSb | ε
Мы можем перефразировать это, чтобы соответствовать обозначению:
# Start with <push S>
<pop S> -> "a" <push B> <push S> | ε
<pop B> -> "b"
Прописью:
- Начнем с
Sв стеке. - Когда мы поп
Sиз стека мы можем либо:- Ничего не соответствует или...
- соответствует "а", но тогда мы должны подтолкнуть государство
Bв стек. Это обещание, мы будем соответствовать "б". Далее мы также толкаемSтак что мы можем продолжать сопоставлять "а", если мы хотим.
- Когда мы подобрали достаточно "а", мы начинаем появляться
Bs из стека, и соответствует "b" для каждого. - Когда это будет сделано, мы сопоставим четное число "a" и "b".
или, более свободно:
Когда мы находимся в случае S, сопоставьте "a" и нажмите B, а затем S или ничего не подходите.
Когда мы находимся в случае B, соответствовать "b".
Во всех случаях мы извлекаем текущее состояние из стека.
Написание шаблона в регулярном выражении.Net
Нам нужно как-то представлять разные государства. Мы не можем выбрать "1", "2", "3" или "a", "b", "c", потому что они могут быть недоступны в нашей входной строке - мы можем сопоставить только то, что присутствует в строке.
Одним из вариантов является нумерация наших штатов (в приведенном выше примере S будет указывать номер 0, и B это состояние 1).
Для государства S мы можем поместить символы в стек. Для удобства мы вставим первые символы в начале строки. Опять же, нам все равно, что это за персонажи, сколько их.
Push-состояние
В.Net, если мы хотим поместить первые 5 символов строки в стек, мы можем написать:
(?<=(?=(?<StateId>.{5}))\A.*)
Это немного запутанно:
(?<=…\A.*)это взгляд, идущий до самого начала строки.- Когда мы в начале, есть взгляд в будущее:
(?=…), Это сделано для того, чтобы мы могли совпадать за пределами текущей позиции - если мы находимся на позиции 2, у нас нет 5 символов перед нами. Итак, мы смотрим назад и с нетерпением ждем. (?<StateId>.{5})добавьте 5 символов в стек, указывая, что в какой-то момент нам нужно сопоставить состояние 5.
Поп-штат
Согласно нашей записи мы всегда извлекаем верхнее состояние из стека. Это просто: (?<-StateId>),
Но прежде чем мы это сделаем, мы хотим знать, в каком состоянии это было - или сколько символов оно захватило. Более конкретно, нам нужно явно проверить для каждого состояния, как switch / case блок. Итак, чтобы проверить, имеет ли стек текущее состояние 5:
(?<=(?=.{5}(?<=\A\k<StateId>))\A.*)
- Снова,
(?<=…\A.*)проходит весь путь к началу. - Теперь мы продвигаемся
(?=.{5}…)на пять символов... - И использовать другой взгляд назад,
(?<=\A\k<StateId>)проверить, что в стеке действительно 5 символов.
Это имеет очевидный недостаток - когда строка слишком короткая, мы не можем представить количество больших состояний. Эта проблема имеет решения:
- Количество коротких слов в языке в любом случае является окончательным, поэтому мы можем добавить их вручную.
- Используйте что-то более сложное, чем один стек - мы можем использовать несколько стеков, каждый с нулем или одним символом, фактически биты нашего состояния (в конце есть пример).
Результат
Наш шаблон для n b n выглядит так:
\A
# Push State A, Index = 0
(?<StateId>)
(?:
(?:
(?:
# When In State A, Index = 0
(?<=(?=.{0}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
(?:
# Push State B, Index = 1
(?<=(?=(?<StateId>.{1}))\A.*)
a
# Push State A, Index = 0
(?<StateId>)
|
)
)
|
(?:
# When In State B, Index = 1
(?<=(?=.{1}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
b
)
|\Z
){2}
)+
\Z
# Assert state stack is empty
(?(StateId)(?!))
Рабочий пример для Regex Storm
Заметки:
- Обратите внимание, что квантификатор вокруг штатов
(?:(?:…){2})+- то есть, (число состояний)×(длина ввода). Я также добавил чередование для\Z, Давайте не будем вдаваться в подробности, но это обходной путь для раздражающей оптимизации в движке.Net. - То же самое можно записать как
(?<A>a)+(?<-A>b)+(?(A)(?!))- это всего лишь упражнение.
Ответить на вопрос
Грамматику вопроса можно переписать так:
# Start with <push A>
<pop A> -> <push A> ( @"," | <push Q> ) | ε
<pop Q> -> \w
| "<" <push Q2Close> <push A>
| "[" <push Q1Close> <push QStar> <push Q1Comma> <push QStar> <push Q1Semicolon> <push A>
<pop Q2Close> -> ">"
<pop QStar> -> <push QStar> <push Q> | ε
<pop Q1Comma> -> ","?
<pop Q1Semicolon> -> ";"
<pop Q1Close> -> "]"
Шаблон:
\A
# Push State A, Index = 0
(?<StateId>)
(?:
(?:
(?:
# When In State A, Index = 0
(?<=(?=.{0}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
(?:
# Push State A, Index = 0
(?<StateId>)
(?:
,
|
# Push State Q, Index = 1
(?<=(?=(?<StateId>.{1}))\A.*)
)
|
)
)
|
(?:
# When In State Q, Index = 1
(?<=(?=.{1}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
(?:
\w
|
<
# Push State Q2Close, Index = 2
(?<=(?=(?<StateId>.{2}))\A.*)
# Push State A, Index = 0
(?<StateId>)
|
\[
# Push State Q1Close, Index = 6
(?<=(?=(?<StateId>.{6}))\A.*)
# Push State QStar, Index = 3
(?<=(?=(?<StateId>.{3}))\A.*)
# Push State Q1Comma, Index = 4
(?<=(?=(?<StateId>.{4}))\A.*)
# Push State QStar, Index = 3
(?<=(?=(?<StateId>.{3}))\A.*)
# Push State Q1Semicolon, Index = 5
(?<=(?=(?<StateId>.{5}))\A.*)
# Push State A, Index = 0
(?<StateId>)
)
)
|
(?:
# When In State Q2Close, Index = 2
(?<=(?=.{2}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
>
)
|
(?:
# When In State QStar, Index = 3
(?<=(?=.{3}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
(?:
# Push State QStar, Index = 3
(?<=(?=(?<StateId>.{3}))\A.*)
# Push State Q, Index = 1
(?<=(?=(?<StateId>.{1}))\A.*)
|
)
)
|
(?:
# When In State Q1Comma, Index = 4
(?<=(?=.{4}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
,?
)
|
(?:
# When In State Q1Semicolon, Index = 5
(?<=(?=.{5}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
;
)
|
(?:
# When In State Q1Close, Index = 6
(?<=(?=.{6}(?<=\A\k<StateId>))\A.*)
(?<-StateId>)
\]
)
|\Z
){7}
)+
\Z
# Assert state stack is empty
(?(StateId)(?!))
К сожалению, это слишком долго, чтобы поместиться в URL, поэтому нет онлайн-примера.
Если бы мы использовали "двоичные" стеки с одним или нулевым символом, это выглядело бы так: https://gist.github.com/kobi/8012361
Вот скриншот шаблона, проходящего все тесты: 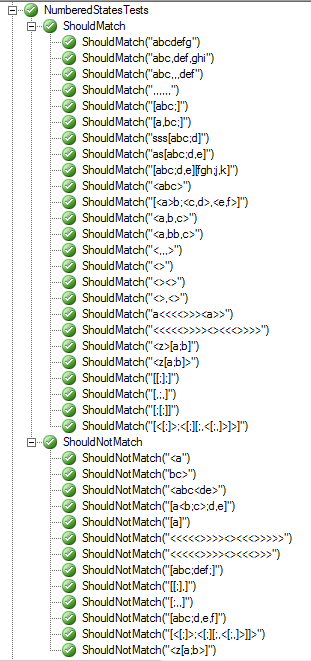
бонус
Движок.Net может делать больше, чем просто балансировать - он также может захватывать каждый экземпляр A или же Q, Это требует небольшой модификации шаблона: https://gist.github.com/kobi/8156968.
Обратите внимание, что мы добавили группы Start, A а также Q к шаблону, но они не влияют на поток, они используются исключительно для захвата.
Результат: например, для строки "[<a>b;<c,d>,<e,f>]" мы можем получить эти Capture s:
Group A
(0-17) [<a>b;<c,d>,<e,f>]
(1-4) <a>b
(2-2) a
(7-9) c,d
(13-15) e,f
Group Q
(0-17) [<a>b;<c,d>,<e,f>]
(1-3) <a>
(2-2) a
(4-4) b
(6-10) <c,d>
(7-7) c
(9-9) d
(12-16) <e,f>
(13-13) e
(15-15) f
Открытые вопросы
- Может ли каждая грамматика быть преобразована в нотацию стека состояний?
- Достаточно ли шагов (количество состояний)×(длина ввода), чтобы соответствовать всем словам? Какая еще формула может работать?
Исходный код
Код, используемый для генерации этих шаблонов и всех тестовых случаев, можно найти по https://github.com/kobi/RecreationalRegex
Ответ (вероятно) Да.
Техника намного сложнее, чем (?1) рекурсивный вызов, но результат почти один к одному с правилами грамматики - я работал таким методичным образом, что легко могу увидеть его в сценарии. По сути, вы подбираете блок за блоком и используете стек, чтобы отслеживать, где вы находитесь. Это почти рабочее решение:
^(?:
(\w(?<Q>)) # Q1
|
(<(?<Angle>)) #Q2 - start <
|
(\>(?<-Angle>)(?<-A>)?(?<Q>)) #Q2 - end >, match Q
|
(\[(?<Block>)) # Q3 start - [
|
(;(?<Semi-Block>)(?<-A>)?) #Q3 - ; after [
|
(\](?<-Semi>)(?<-Q>)*(?<Q>)) #Q3 ] after ;, match Q
|
((,|(?<-Q>))*(?<A>)) #Match an A group
)*$
# Post Conditions
(?(Angle)(?!))
(?(Block)(?!))
(?(Semi)(?!))
Это пропускает часть разрешения запятых в Q->[A;Q*,?Q*]и по какой-то причине позволяет [A;A]так что совпадает [;,,] а также [abc;d,e,f], Остальные строки совпадают с тестовыми примерами.
Другим незначительным моментом является проблема с переносом в стек с пустым захватом - это не так. A принимает Ø, поэтому я должен был использовать (?<-A>)? чтобы проверить, захвачен ли он.
Все регулярные выражения должны выглядеть следующим образом, но опять же, это бесполезно с ошибкой там.
Почему это не работает?
Нет способа синхронизации стеков: если я нажму (?<A>) а также (?<B>)Я могу совать их в любом порядке. Вот почему эта модель не может дифференцироваться <z[a;b>] от <z[a;b]>... нам нужен один стек для всех.
Это может быть решено для простых случаев, но здесь у нас есть нечто гораздо более сложное - в целом Q или же A, а не просто "<" или "[".