Увеличить multi_index_container и медленный оператор ++
Это дополнительный вопрос для этого вопроса MIC. При добавлении элементов в вектор ссылочных упаковщиков я трачу около 80% времени внутри оператора ++ независимо от того, какой вариант итерации я выберу.
Запрос работает следующим образом
VersionView getVersionData(int subdeliveryGroupId, int retargetingId,
const std::wstring &flightName) const {
VersionView versions;
for (auto i = 0; i < 3; ++i) {
for (auto j = 0; j < 3; ++j) {
versions.insert(m_data.get<mvKey>().equal_range(boost::make_tuple(subdeliveryGroupId + i, retargetingId + j,
flightName)));
}
}
return versions;
}
Я пробовал следующие способы заполнения справочной оболочки
template <typename InputRange> void insert(const InputRange &rng) {
// 1) base::insert(end(), rng.first, rng.second); // 12ms
// 2) std::copy(rng.first, rng.second, std::back_inserter(*this)); // 6ms
/* 3) size_t start = size(); // 12ms
auto tmp = std::reference_wrapper<const
VersionData>(VersionData(0,0,L""));
resize(start + boost::size(rng), tmp);
auto beg = rng.first;
for (;beg != rng.second; ++beg, ++start)
{
this->operator[](start) = std::reference_wrapper<const VersionData>(*beg);
}
*/
std::copy(rng.first, rng.second, std::back_inserter(*this));
}
Все, что я делаю, я плачу за оператор ++ или метод размера, который просто увеличивает итератор, то есть я все еще застрял в ++. Таким образом, вопрос заключается в том, есть ли способ итерировать диапазоны результатов быстрее. Если такого способа не существует, стоит ли попробовать перейти к реализации equal_range, добавив новый аргумент, который содержит ссылку на контейнер reference_wrapper, который будет заполнен результатами вместо создания диапазона?
РЕДАКТИРОВАТЬ 1: пример кода http://coliru.stacked-crooked.com/a/8b82857d302e4a06/
Из-за этой ошибки он не скомпилируется на Coliru
РЕДАКТИРОВАТЬ 2: Дерево вызовов, со временем, проведенным в операторе ++
 РЕДАКТИРОВАТЬ 3: некоторые конкретные вещи. Прежде всего, я не запустил этот поток только потому, что оператор ++ занимает слишком много времени в общем времени выполнения, и мне не нравится это просто "потому что", но в этот самый момент это является основным узким местом в наших тестах производительности. Каждый запрос обычно обрабатывается в сотнях микросекунд, запрос, аналогичный этому (они несколько более сложные), обрабатывается ~1000-1500 микросекунд, и он все еще приемлем. Первоначальная проблема заключалась в том, что как только число элементов в структуре данных увеличивается до сотен тысяч, производительность снижается примерно до 20 миллисекунд. Теперь, после перехода на MIC (что значительно улучшило читаемость кода, удобство обслуживания и общую элегантность), я могу достичь примерно 13 миллисекунд на запрос, из которых 80%-90% тратится на оператор ++. Теперь вопрос, можно ли это как-то улучшить или я должен искать смолу и перья для меня?:)
РЕДАКТИРОВАТЬ 3: некоторые конкретные вещи. Прежде всего, я не запустил этот поток только потому, что оператор ++ занимает слишком много времени в общем времени выполнения, и мне не нравится это просто "потому что", но в этот самый момент это является основным узким местом в наших тестах производительности. Каждый запрос обычно обрабатывается в сотнях микросекунд, запрос, аналогичный этому (они несколько более сложные), обрабатывается ~1000-1500 микросекунд, и он все еще приемлем. Первоначальная проблема заключалась в том, что как только число элементов в структуре данных увеличивается до сотен тысяч, производительность снижается примерно до 20 миллисекунд. Теперь, после перехода на MIC (что значительно улучшило читаемость кода, удобство обслуживания и общую элегантность), я могу достичь примерно 13 миллисекунд на запрос, из которых 80%-90% тратится на оператор ++. Теперь вопрос, можно ли это как-то улучшить или я должен искать смолу и перья для меня?:)
4 ответа
Я думаю, что вы измеряете неправильные вещи полностью. Когда я масштабируюсь с 3x3x11111 до 10x10x111111 (т.е. в 111 раз больше элементов в индексе), он все равно работает за 290 мс.
И заполнение материала занимает на порядки больше времени. Кажется, даже освобождение контейнера отнимает больше времени.
Что не имеет значения?
Я привел версию с некоторыми компромиссами, которые в основном показывают, что нет смысла настраивать вещи: View On Coliru
- есть переключатель, чтобы избежать
any_range(это не имеет смысла использовать это, если вы заботитесь о производительности) есть переключатель для настройки веса:
#define USE_FLYWEIGHT 0 // 0: none 1: full 2: no tracking 3: no tracking no lockingопять же, это просто показывает, что вы легко можете обойтись без него, и вам следует подумать об этом, если вам не нужна оптимизация памяти для строки (?) Если это так, рассмотрите возможность использования
OPTIMIZE_ATOMSподход:OPTIMIZE_ATOMSв основном летать вес дляwstringтам. Поскольку все строки повторяются здесь, это будет очень эффективно для хранения (хотя реализация быстрая и грязная и должна быть улучшена). Идея гораздо лучше применяется здесь: Как улучшить производительность улучшенных поисков interval_map
Вот некоторые элементарные тайминги:
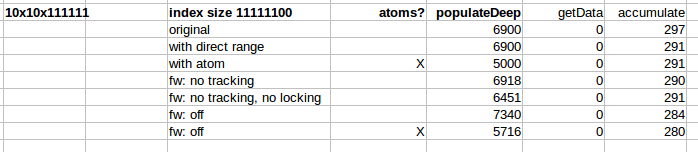
Как видите, в принципе ничего не имеет значения для выполнения запросов / итераций.
Любые итераторы: они имеют значение?
Это может быть причиной вашего компилятора. На моей компиляции (gcc 4.8.2) ничего особенного не было, но посмотрите разборку цикла накопления без итератора:
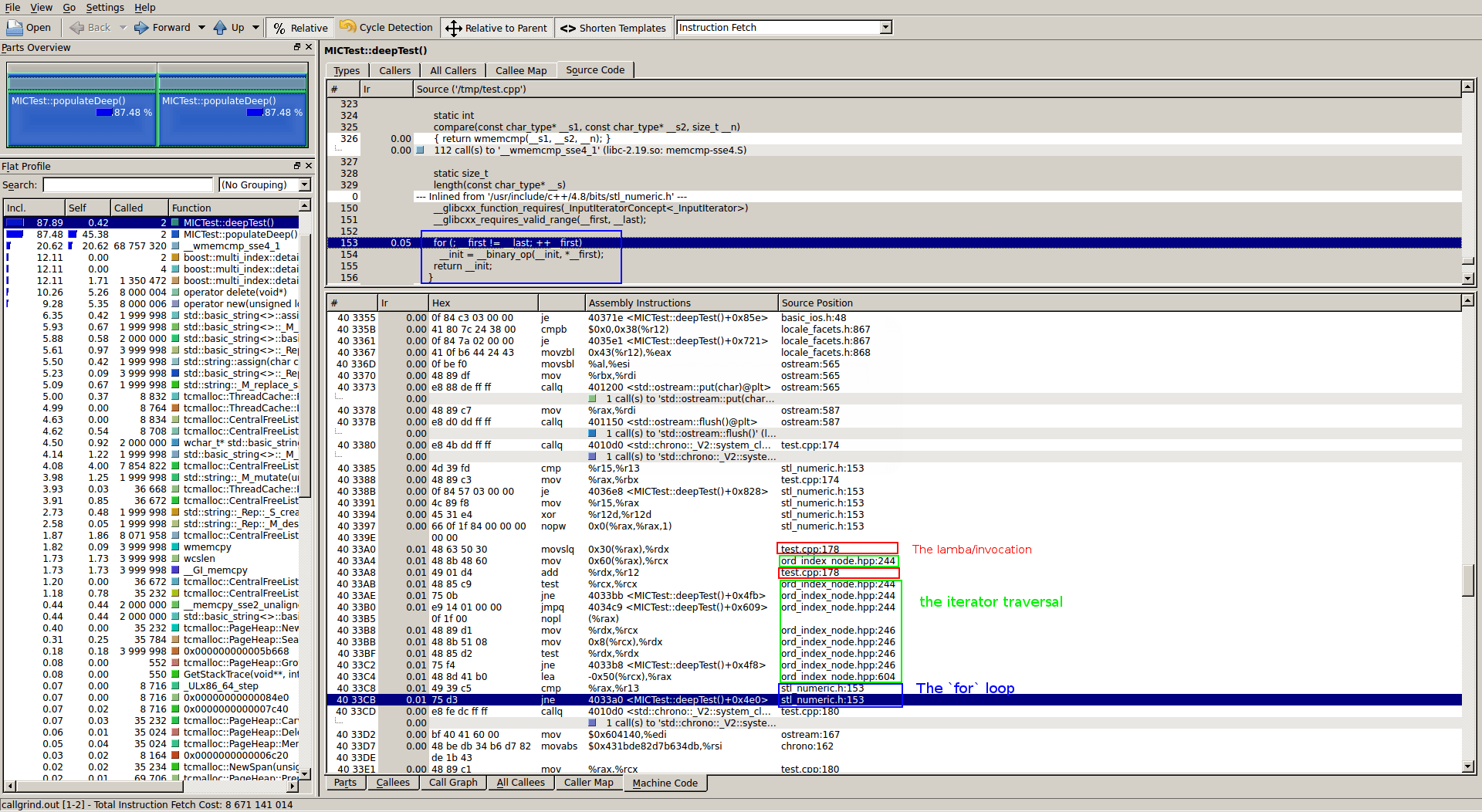
Как вы можете видеть из разделов, которые я выделил, кажется, что нет ничего сложного ни в алгоритме, ни в лямбде, ни в обходе итератора. Теперь с any_iterator ситуация намного менее ясна, и если ваша компиляция оптимизируется хуже, я могу представить, что она не в состоянии встроить элементарные операции, замедляя итерацию. (Просто угадаю немного сейчас)
@kreuzerkrieg, ваш пример кода не выполняет вставку в vector из std::reference_wrappers! Вместо этого вы проецируете результат equal_range в boost::any_range, который, как ожидается, будет довольно медленным на итерации - в основном, увеличение числа операций разрешается для виртуальных вызовов.
Итак, если я не пропускаю что-то здесь серьезно, производительность примера кода или его отсутствие не имеют ничего общего с вашей проблемой в реальном коде (при условии VersionView, из которых вы не показываете код, не использует boost::any_range).
Тем не менее, если вы можете позволить себе заменить упорядоченные индексы эквивалентными хешированными индексами, итерация, вероятно, будет быстрее, но это полный удар в темноте, если вы не показываете реальные вещи.
Тот факт, что 80% getVersionDataВремя выполнения тратится в operator++ Сам по себе не свидетельствует о каких-либо проблемах с производительностью, но говорит о том, что equal_range а также std::reference_wrapper вставка быстрее по сравнению. Иными словами, когда вы профилируете какой-то фрагмент кода, вы обычно находите места, где тратится больше всего времени, но зависит ли это от проблем или нет, зависит от требуемой общей производительности.
Итак, я применил следующее решение: в дополнение к индексу odered_non_unique ('byKey') я добавил индекс random_access. Когда данные загружены, я переставляю случайный индекс с помощью m_data.get.begin(). Затем, когда MIC запрашивается для данных, я просто делаю boost::equal_range для случайного индекса с пользовательским предикатом, который эмулирует ту же логику, которая применялась при упорядочении индекса 'byKey'. Вот и все, это дало мне быстрый "size()" (O(1), как я понимаю) и быстрый обход. Теперь я готов к твоим гнилым помидорам:)
РЕДАКТИРОВАТЬ 1: конечно, я изменил any_range с тега двунаправленного обхода на случайный доступ