Условное разделение служб SSIS 2 не работает должным образом
Я новичок в SSIS и проходил через сценарий использования, где я хочу реализовать SCD типа 2 без использования компонента SCD (это требование), где мне нужно использовать более одного условного разбиения и Lookup. теперь, когда я использую один поиск и одно условное разбиение, он работает как шарм, но в момент, когда я ввожу второе условное разбиение, он не работает в любом случае. Я предоставил данные для просмотра данных, но они также не отображают данные.
вы не могли бы мне помочь
мой поток данных выглядит так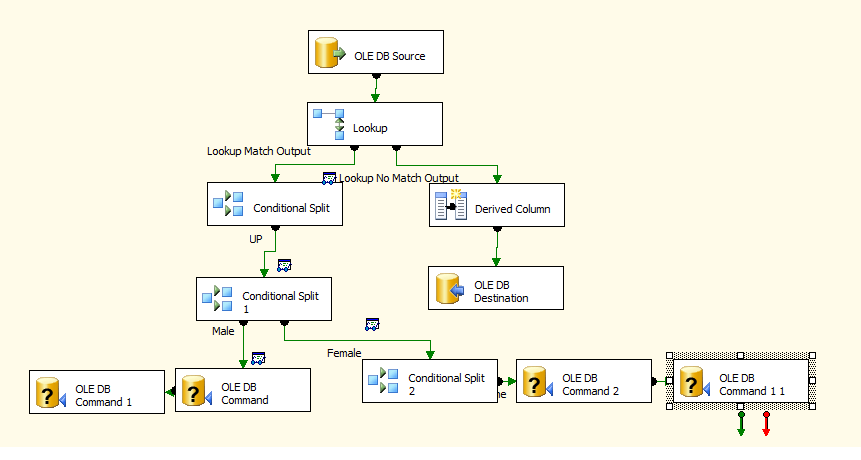
все еще первое условное разбиение все выглядит нормально, но после вставки второго и третьего условного разбиения не работает
1 ответ
Помните бритву Оккама. Что более вероятно, что продукт разработан, который работает с 0 к 1 компонентам, но полностью терпит неудачу с 2 или что ваша реализация имеет недостатки?
Я обнаружил, что следующие ситуации, скорее всего, будут идти вразрез с ожиданиями, которые я перевожу на "Я не читал никакой документации и пробираюсь по интерфейсу". Это не является оскорблением, это просто подход, который многие, в том числе и я, используют. Хитрость, конечно, в том, что когда вы столкнулись с чем-то, что ведет себя не так, вы обращаетесь к Руководству по тонкой настройке.
Проблемы дизайна высокого уровня
Ваши условные разбиения не учитывают все возможности, поэтому вы "теряете" данные. То, чего не хватает вашему потоку данных, - это количество строк. Сколько строк я начал с? Сколько строк отправлено в различные раковины / места назначения? В конце дня / потока данных вы должны быть в состоянии учитывать все данные. Если нет, значит, что-то пошло не так и загрузка данных недействительна.
Я также выбрал бы nits из-за отсутствия у вас полезных имен компонентов и объектов OLE DB Command, но это удобство обслуживания и масштабируемости, что является преждевременной оптимизацией, когда ответы неверны
Что, вероятно, причина
Приступая к медным трюкам, я готов поспорить, что вы теряете данные в следующих условиях в ваших данных
- НОЛЬ
- чувствительность к регистру
Из ваших аннотаций пути, ваш второй Conditional Split 1 имеет 2-3 выхода. Male, Femaleи при условии, что вы не переименовали вывод по умолчанию в мужской или женский, Default,
Вы заявляете, что теряете все данные в этом разделении. Вполне вероятно, что все идет к выводу по умолчанию. Я ожидаю, что у вас есть выражения в вашем условном разделении, как
Male := [GenderColumn] == "Male"
Female := [GenderColumn] == "Female"
Однако, если ваши исходные данные содержат мужской, мужской, женский, ЖЕНЩИНУ и все промежуточные перестановки, вы всегда будете сопоставлять только на основе строгого учета с учетом регистра, которому не соответствует ни один из ваших данных. Чтобы решить эту проблему, вы хотите сравнить согласованные значения.
Здесь я произвольно конвертирую все в верхний регистр. LOWER работает так же хорошо. Важно то, что они должны привести к одной и той же стоимости. Я также ленив в том, что я применяю функцию к константе.
Male := UPPER([GenderColumn]) == UPPER("Male")
Female := UPPER([GenderColumn]) == UPPER("Female")
Но подождите, что если у меня есть NULL? Отличный вопрос, что делать? Значение NULL не является ни мужским, ни женским, как должны обрабатываться эти данные? Прямо сейчас идет по пути вывода по умолчанию. Возможно, к этому следует относиться как к мужчине, так как в нашем продукте есть гендерная предвзятость. Ваш бизнес-пользователь, вероятно, будет знать, что следует делать с неизвестными значениями, поэтому вам следует обратиться к ним. Затем вы должны добавить в условие ИЛИ, через || и проверьте, является ли текущее значение для нашего столбца NULL
Male := UPPER([GenderColumn]) == UPPER("Male") || ISNULL([GenderColumn])
Female := UPPER([GenderColumn]) == UPPER("Female")