Как запустить несколько параллельных WriteToBigQuery в облаке данных Google / Apache Beam?
Я хочу отделить событие от множества событий, учитывая данные
{"type": "A", "k1": "v1"}
{"type": "B", "k2": "v2"}
{"type": "C", "k3": "v3"}
И я хочу отделить type: A события к столу A в большом запросе, type:B события к столу B, type: C события к столу C,
Вот мои коды, реализованные через apache beam Python SDK и записать данные в bigquery,
A_schema = 'type:string, k1:string'
B_schema = 'type:string, k2:string'
C_schema = 'type:string, k2:string'
class ParseJsonDoFn(beam.DoFn):
A_TYPE = 'tag_A'
B_TYPE = 'tag_B'
C_TYPE = 'tag_C'
def process(self, element):
text_line = element.trip()
data = json.loads(text_line)
if data['type'] == 'A':
yield pvalue.TaggedOutput(self.A_TYPE, data)
elif data['type'] == 'B':
yield pvalue.TaggedOutput(self.B_TYPE, data)
elif data['type'] == 'C':
yield pvalue.TaggedOutput(self.C_TYPE, data)
def run():
parser = argparse.ArgumentParser()
parser.add_argument('--input',
dest='input',
default='data/path/data',
help='Input file to process.')
known_args, pipeline_args = parser.parse_known_args(argv)
pipeline_args.extend([
'--runner=DirectRunner',
'--project=project-id',
'--job_name=seperate-bi-events-job',
])
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = True
with beam.Pipeline(options=pipeline_options) as p:
lines = p | ReadFromText(known_args.input)
multiple_lines = (
lines
| 'ParseJSON' >> (beam.ParDo(ParseJsonDoFn()).with_outputs(
ParseJsonDoFn.A_TYPE,
ParseJsonDoFn.B_TYPE,
ParseJsonDoFn.C_TYPE)))
a_line = multiple_lines.tag_A
b_line = multiple_lines.tag_B
c_line = multiple_lines.tag_C
(a_line
| "output_a" >> beam.io.WriteToBigQuery(
'temp.a',
schema = A_schema,
write_disposition = beam.io.BigQueryDisposition.WRITE_TRUNCATE,
create_disposition = beam.io.BigQueryDisposition.CREATE_IF_NEEDED
))
(b_line
| "output_b" >> beam.io.WriteToBigQuery(
'temp.b',
schema = B_schema,
write_disposition = beam.io.BigQueryDisposition.WRITE_TRUNCATE,
create_disposition = beam.io.BigQueryDisposition.CREATE_IF_NEEDED
))
(c_line
| "output_c" >> beam.io.WriteToBigQuery(
'temp.c',
schema = (C_schema),
write_disposition = beam.io.BigQueryDisposition.WRITE_TRUNCATE,
create_disposition = beam.io.BigQueryDisposition.CREATE_IF_NEEDED
))
p.run().wait_until_finish()
Выход:
INFO:root:start <DoOperation output_banner/WriteToBigQuery output_tags=['out']>
INFO:oauth2client.transport:Attempting refresh to obtain initial access_token
INFO:oauth2client.client:Refreshing access_token
WARNING:root:Sleeping for 150 seconds before the write as BigQuery inserts can be routed to deleted table for 2 mins after the delete and create.
INFO:root:start <DoOperation output_banner/WriteToBigQuery output_tags=['out']>
INFO:oauth2client.transport:Attempting refresh to obtain initial access_token
INFO:oauth2client.client:Refreshing access_token
WARNING:root:Sleeping for 150 seconds before the write as BigQuery inserts can be routed to deleted table for 2 mins after the delete and create.
INFO:root:start <DoOperation output_banner/WriteToBigQuery output_tags=['out']>
INFO:oauth2client.transport:Attempting refresh to obtain initial access_token
INFO:oauth2client.client:Refreshing access_token
WARNING:root:Sleeping for 150 seconds before the write as BigQuery inserts can be routed to deleted table for 2 mins after the delete and create.
Однако здесь есть два вопроса
- нет данных в
bigquery? - Судя по логам, коды НЕ работают параллельно, а не запускаются 3 раза подряд?
Что-то не так в моих кодах или я что-то упускаю?
1 ответ
нет данных в bigquery?
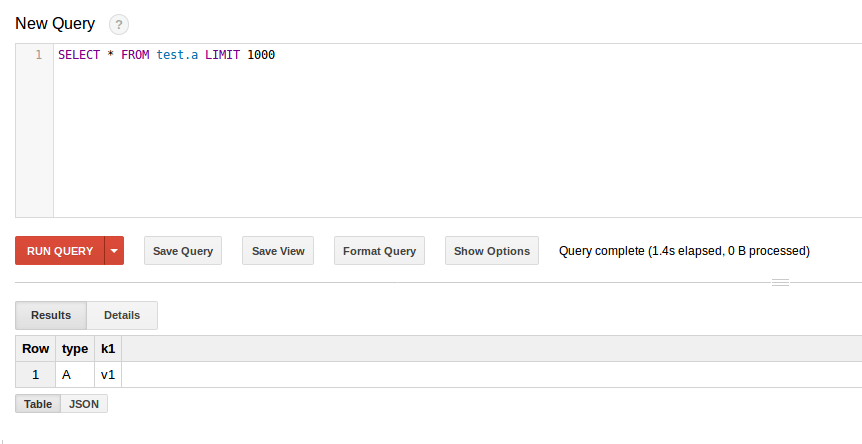
Ваш код выглядит отлично, так как данные записываются в BigQuery (C_schema должно быть k3 вместо k2). Помните, что данные передаются в потоковом режиме, поэтому вы не увидите их, если нажмете Preview кнопка таблицы, пока данные в потоковом буфере не будут зафиксированы. Запуск SELECT * запрос отобразит ожидаемые результаты:
Судя по логам, коды НЕ работают параллельно, а не запускаются 3 раза подряд?
Ок, это интересно. Прослеживая WARNING В сообщении в коде мы можем прочитать следующее:
# if write_disposition == BigQueryDisposition.WRITE_TRUNCATE we delete
# the table before this point.
if write_disposition == BigQueryDisposition.WRITE_TRUNCATE:
# BigQuery can route data to the old table for 2 mins max so wait
# that much time before creating the table and writing it
logging.warning('Sleeping for 150 seconds before the write as ' +
'BigQuery inserts can be routed to deleted table ' +
'for 2 mins after the delete and create.')
# TODO(BEAM-2673): Remove this sleep by migrating to load api
time.sleep(150)
return created_table
else:
return created_table
После прочтения BEAM-2673 и BEAM-2801 кажется, что это связано с проблемой приемника BigQuery, использующего потоковый API с DirectRunner, Это приведет к тому, что процесс перестанет работать в течение 150 секунд при повторном создании таблицы, а это не будет сделано параллельно.
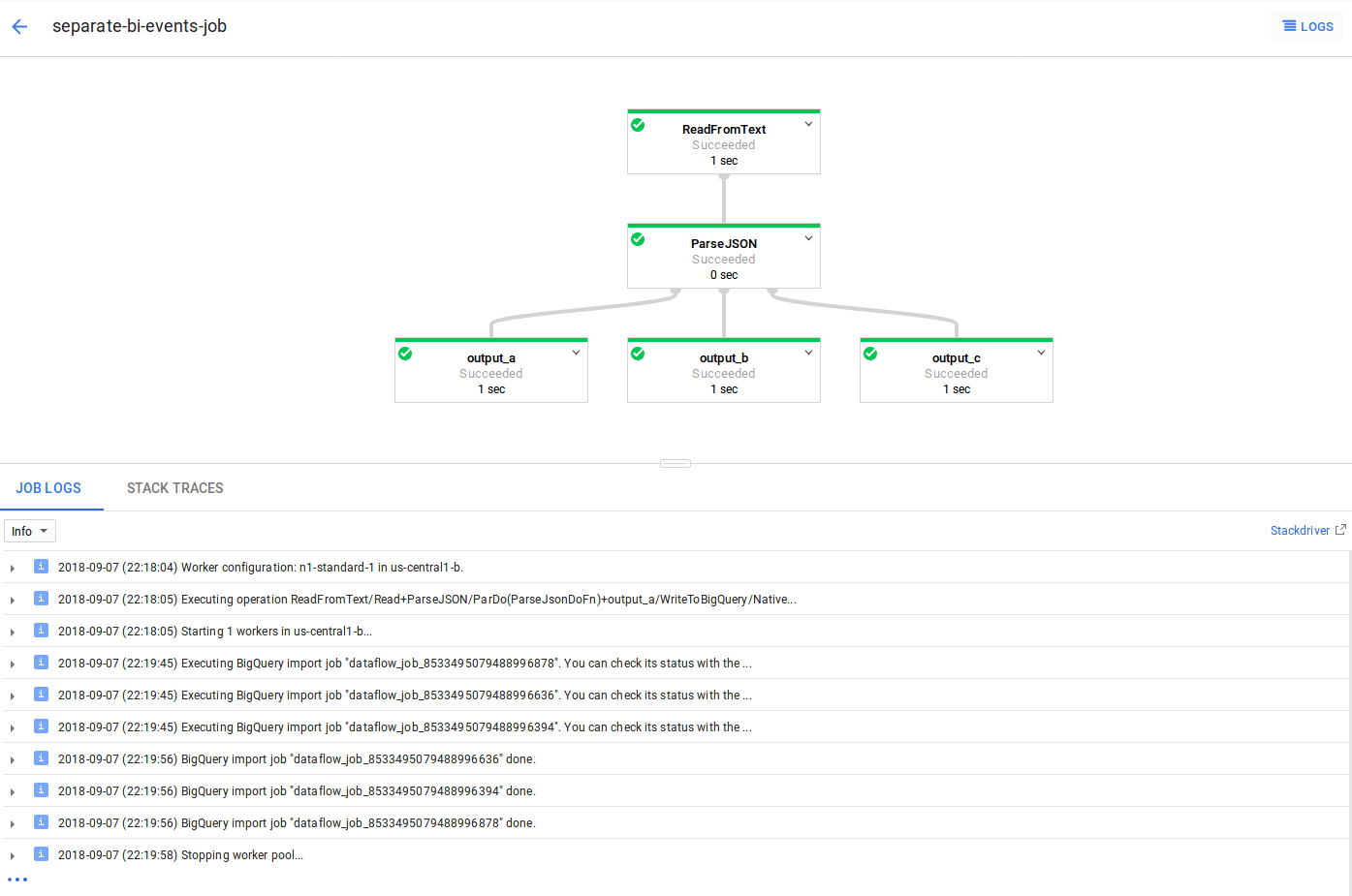
Если вместо этого мы запустим его в потоке данных (используя DataflowRunner, предоставляя промежуточный и временный путь, а также загружая входные данные из GCS), это будет запускать три задания импорта параллельно. На следующем рисунке видно, что все три начинаются с 22:19:45 и закончить в 22:19:56: