Разница в производительности между двумя, казалось бы, эквивалентными кодами сборки
tl; dr: у меня есть два функционально эквивалентных C-кода, которые я компилирую с Clang (тот факт, что это C-код не имеет большого значения; мне кажется, интересна только сборка), и IACA говорит мне, что один должен быть быстрее, но я Я не понимаю, почему, и мои тесты показывают одинаковую производительность для двух кодов.
У меня есть следующий код C (игнорировать #include "iacaMarks.h", IACA_START, IACA_END теперь):
ref.c:
#include "iacaMarks.h"
#include <x86intrin.h>
#define AND(a,b) _mm_and_si128(a,b)
#define OR(a,b) _mm_or_si128(a,b)
#define XOR(a,b) _mm_xor_si128(a,b)
#define NOT(a) _mm_andnot_si128(a,_mm_set1_epi32(-1))
void sbox_ref (__m128i r0,__m128i r1,__m128i r2,__m128i r3,
__m128i* r5,__m128i* r6,__m128i* r7,__m128i* r8) {
__m128i r4;
IACA_START
r3 = XOR(r3,r0);
r4 = r1;
r1 = AND(r1,r3);
r4 = XOR(r4,r2);
r1 = XOR(r1,r0);
r0 = OR(r0,r3);
r0 = XOR(r0,r4);
r4 = XOR(r4,r3);
r3 = XOR(r3,r2);
r2 = OR(r2,r1);
r2 = XOR(r2,r4);
r4 = NOT(r4);
r4 = OR(r4,r1);
r1 = XOR(r1,r3);
r1 = XOR(r1,r4);
r3 = OR(r3,r0);
r1 = XOR(r1,r3);
r4 = XOR(r4,r3);
*r5 = r1;
*r6 = r4;
*r7 = r2;
*r8 = r0;
IACA_END
}
Мне было интересно, смогу ли я оптимизировать его, вручную изменив расписание нескольких инструкций (я хорошо знаю, что компилятор C должен производить эффективное планирование, но мои эксперименты показали, что это не всегда так). В какой-то момент я попробовал следующий код (он такой же, как и выше, за исключением того, что никакие временные переменные не используются для хранения результатов XOR, которые впоследствии присваиваются *r5 а также *r6):
resched.c:
#include "iacaMarks.h"
#include <x86intrin.h>
#define AND(a,b) _mm_and_si128(a,b)
#define OR(a,b) _mm_or_si128(a,b)
#define XOR(a,b) _mm_xor_si128(a,b)
#define NOT(a) _mm_andnot_si128(a,_mm_set1_epi32(-1))
void sbox_resched (__m128i r0,__m128i r1,__m128i r2,__m128i r3,
__m128i* r5,__m128i* r6,__m128i* r7,__m128i* r8) {
__m128i r4;
IACA_START
r3 = XOR(r3,r0);
r4 = r1;
r1 = AND(r1,r3);
r4 = XOR(r4,r2);
r1 = XOR(r1,r0);
r0 = OR(r0,r3);
r0 = XOR(r0,r4);
r4 = XOR(r4,r3);
r3 = XOR(r3,r2);
r2 = OR(r2,r1);
r2 = XOR(r2,r4);
r4 = NOT(r4);
r4 = OR(r4,r1);
r1 = XOR(r1,r3);
r1 = XOR(r1,r4);
r3 = OR(r3,r0);
*r7 = r2;
*r8 = r0;
*r5 = XOR(r1,r3); // This two lines are different
*r6 = XOR(r4,r3); // (no more temporary variables)
IACA_END
}
Я компилирую эти коды, используя Clang 5.0.0 для моего i5-6500 (Skylake) с флагами -O3 -march=native (Я опускаю созданный код сборки, поскольку его можно найти в выходных данных IACA ниже, но если вы предпочитаете иметь их прямо здесь, спросите меня, и я добавлю их). Я сравнил эти два кода и не обнаружил разницы в производительности между ними. Из любопытства я запустил IACA для них, и я был удивлен, увидев, что в первой версии должно быть 6 циклов, а во второй - 7 циклов. Вот результаты производства IACA:
Для первой версии:
dada@dada-ubuntu ~/perf % clang -O3 -march=native -c ref.c && ./iaca -arch SKL ref.o
Intel(R) Architecture Code Analyzer Version - v3.0-28-g1ba2cbb build date: 2017-10-23;16:42:45
Analyzed File - ref_iaca.o
Binary Format - 64Bit
Architecture - SKL
Analysis Type - Throughput
Throughput Analysis Report
--------------------------
Block Throughput: 6.00 Cycles Throughput Bottleneck: FrontEnd
Loop Count: 23
Port Binding In Cycles Per Iteration:
--------------------------------------------------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
--------------------------------------------------------------------------------------------------
| Cycles | 6.0 0.0 | 6.0 | 1.3 0.0 | 1.4 0.0 | 4.0 | 6.0 | 0.0 | 1.4 |
--------------------------------------------------------------------------------------------------
DV - Divider pipe (on port 0)
D - Data fetch pipe (on ports 2 and 3)
F - Macro Fusion with the previous instruction occurred
* - instruction micro-ops not bound to a port
^ - Micro Fusion occurred
# - ESP Tracking sync uop was issued
@ - SSE instruction followed an AVX256/AVX512 instruction, dozens of cycles penalty is expected
X - instruction not supported, was not accounted in Analysis
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
-----------------------------------------------------------------------------------------
| 1 | 1.0 | | | | | | | | vpxor xmm4, xmm3, xmm0
| 1 | | 1.0 | | | | | | | vpand xmm5, xmm4, xmm1
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm2, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm5, xmm5, xmm0
| 1 | | 1.0 | | | | | | | vpor xmm0, xmm3, xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm0, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm1, xmm4, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm3, xmm4, xmm2
| 1 | | | | | | 1.0 | | | vpor xmm2, xmm5, xmm2
| 1 | 1.0 | | | | | | | | vpxor xmm2, xmm2, xmm1
| 1 | | 1.0 | | | | | | | vpcmpeqd xmm4, xmm4, xmm4
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm1, xmm4
| 1 | 1.0 | | | | | | | | vpor xmm1, xmm5, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm4, xmm5, xmm3
| 1 | | | | | | 1.0 | | | vpor xmm3, xmm0, xmm3
| 1 | 1.0 | | | | | | | | vpxor xmm4, xmm4, xmm3
| 1 | | 1.0 | | | | | | | vpxor xmm4, xmm4, xmm1
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm1, xmm3
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdi], xmm4
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rsi], xmm1
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdx], xmm2
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rcx], xmm0
Total Num Of Uops: 26
Для второй версии:
dada@dada-ubuntu ~/perf % clang -O3 -march=native -c resched.c && ./iaca -arch SKL resched.o
Intel(R) Architecture Code Analyzer Version - v3.0-28-g1ba2cbb build date: 2017-10-23;16:42:45
Analyzed File - resched_iaca.o
Binary Format - 64Bit
Architecture - SKL
Analysis Type - Throughput
Throughput Analysis Report
--------------------------
Block Throughput: 7.00 Cycles Throughput Bottleneck: Backend
Loop Count: 22
Port Binding In Cycles Per Iteration:
--------------------------------------------------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
--------------------------------------------------------------------------------------------------
| Cycles | 6.0 0.0 | 6.0 | 1.3 0.0 | 1.4 0.0 | 4.0 | 6.0 | 0.0 | 1.3 |
--------------------------------------------------------------------------------------------------
DV - Divider pipe (on port 0)
D - Data fetch pipe (on ports 2 and 3)
F - Macro Fusion with the previous instruction occurred
* - instruction micro-ops not bound to a port
^ - Micro Fusion occurred
# - ESP Tracking sync uop was issued
@ - SSE instruction followed an AVX256/AVX512 instruction, dozens of cycles penalty is expected
X - instruction not supported, was not accounted in Analysis
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
-----------------------------------------------------------------------------------------
| 1 | 1.0 | | | | | | | | vpxor xmm4, xmm3, xmm0
| 1 | | 1.0 | | | | | | | vpand xmm5, xmm4, xmm1
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm2, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm5, xmm5, xmm0
| 1 | | 1.0 | | | | | | | vpor xmm0, xmm3, xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm0, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm1, xmm4, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm3, xmm4, xmm2
| 1 | | | | | | 1.0 | | | vpor xmm2, xmm5, xmm2
| 1 | 1.0 | | | | | | | | vpxor xmm2, xmm2, xmm1
| 1 | | 1.0 | | | | | | | vpcmpeqd xmm4, xmm4, xmm4
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm1, xmm4
| 1 | 1.0 | | | | | | | | vpor xmm1, xmm5, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm4, xmm5, xmm3
| 1 | | | | | | 1.0 | | | vpor xmm3, xmm0, xmm3
| 2^ | | | 0.3 | 0.4 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdx], xmm2
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.4 | vmovdqa xmmword ptr [rcx], xmm0
| 1 | 1.0 | | | | | | | | vpxor xmm0, xmm4, xmm3
| 1 | | 1.0 | | | | | | | vpxor xmm0, xmm0, xmm1
| 2^ | | | 0.4 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdi], xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm1, xmm3
| 2^ | | | 0.3 | 0.4 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rsi], xmm0
Total Num Of Uops: 26
Analysis Notes:
Backend allocation was stalled due to unavailable allocation resources.
Как вы можете видеть, во второй версии IACA говорит, что узким местом является бэкэнд, и что "бэкэнд-распределение было приостановлено из-за недоступных ресурсов выделения".
Оба ассемблерных кода содержат одинаковые инструкции, и единственными отличиями являются расписание последних 7 инструкций, а также регистры, которые они используют.
Единственное, что я могу придумать, это объяснить, почему второй код работает медленнее, это то, что он пишет дважды xmm0 в последних 4 инструкциях, таким образом вводя зависимость. Но так как эти записи независимы, я ожидаю, что ЦП будет использовать для них разные физические регистры. Однако я не могу доказать эту теорию. Кроме того, если использовать дважды xmm0 как это было проблемой, я ожидал бы, что Clang будет использовать другой регистр для одной из инструкций (в частности, поскольку давление в регистре здесь низкое).
Мой вопрос: второй код должен быть медленнее (на основе кода сборки) и почему?
Изменить: следы IACA:
Первая версия: https://pastebin.com/qGXHVW6a
Вторая версия: https://pastebin.com/dbBNWsc2
Примечание: C-коды являются реализациями первого S-блока шифра Serpent, вычисленного здесь Osvik.
1 ответ
Выяснение того, почему второй код связан с бэкэндом, требует некоторого объема ручного анализа, потому что вывод, выдаваемый IACA, слишком сырой, хотя и чрезвычайно богатый информацией. Обратите внимание, что трассировки, испускаемые IACA, особенно полезны для анализа циклов. Они также могут быть полезны для понимания того, как выполняются прямые последовательности инструкций (что не так полезно), но испускаемые трассы должны интерпретироваться по-разному. В остальной части этого ответа я представлю свой анализ по циклическому сценарию, который труднее сделать.
Тот факт, что вы отправили трассировки без помещения кода в цикл, влияет на следующие вещи:
- компилятор не может встроить и оптимизировать хранилища для выходных операндов. Они бы вообще не появлялись в реальном цикле или в цепочке с другим S-блоком.
- зависимости данных от выходов до входов происходят по совпадению, так как компилятор использовал xmm0..3 для подготовки данных к хранению, а не как следствие выбора того, какой вывод передавать на какой вход того же S-блока.
-
vpcmpeqdэто создает вектор "все единицы" (для NOT), который будет выведен из цикла после вставки. - Там будет
dec/jnzили эквивалентные издержки цикла (которые могут быть объединены в один UOP для порта 6).
Но вы попросили IACA проанализировать этот точный блок asm, как если бы он был запущен в цикле. Поэтому, чтобы объяснить результаты, мы так и подумаем (хотя это не то, что вы получите от компилятора C, если бы вы использовали эту функцию в цикле).
jmp или же dec/jnz Внизу, чтобы сделать это цикл не является проблемой в этом случае: он всегда будет выполняться на порту 6, который не используется ни одной векторной инструкцией. Это означает, что инструкция перехода не будет конкурировать с портом 6 и не будет использовать пропускную способность планировщика, которая в противном случае использовалась бы другими инструкциями. Однако это может повлиять на пропускную способность распределителя ресурсов на этапе выпуска / переименования (которое составляет не более 4 мопов слитых доменов за цикл), но это не важно в данном конкретном случае, как я буду обсуждать.
Давайте сначала рассмотрим цифру ASCII давления в порте:
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
-----------------------------------------------------------------------------------------
| 1 | 1.0 | | | | | | | | vpxor xmm4, xmm3, xmm0
| 1 | | 1.0 | | | | | | | vpand xmm5, xmm4, xmm1
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm2, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm5, xmm5, xmm0
| 1 | | 1.0 | | | | | | | vpor xmm0, xmm3, xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm0, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm1, xmm4, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm3, xmm4, xmm2
| 1 | | | | | | 1.0 | | | vpor xmm2, xmm5, xmm2
| 1 | 1.0 | | | | | | | | vpxor xmm2, xmm2, xmm1
| 1 | | 1.0 | | | | | | | vpcmpeqd xmm4, xmm4, xmm4
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm1, xmm4
| 1 | 1.0 | | | | | | | | vpor xmm1, xmm5, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm4, xmm5, xmm3
| 1 | | | | | | 1.0 | | | vpor xmm3, xmm0, xmm3
| 2^ | | | 0.3 | 0.4 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdx], xmm2
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.4 | vmovdqa xmmword ptr [rcx], xmm0
| 1 | 1.0 | | | | | | | | vpxor xmm0, xmm4, xmm3
| 1 | | 1.0 | | | | | | | vpxor xmm0, xmm0, xmm1
| 2^ | | | 0.4 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdi], xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm1, xmm3
| 2^ | | | 0.3 | 0.4 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rsi], xmm0
Общее количество мопов слитых доменов составляет 22. Для каждого из портов 0, 1 и 5 назначено 6 разных мопов. Остальные 4 мопа состоят из мопов STD и STA. STD требует порт 4. Это назначение является разумным. Если мы игнорируем все зависимости данных, кажется, что планировщик должен иметь возможность отправлять как минимум 3 мопа слитых доменов в каждом цикле. Однако в порту 4 может возникнуть серьезная конфликтная ситуация, которая может привести к заполнению станции бронирования. Согласно IACA, это не является узким местом в этом коде. Обратите внимание, что если планировщик может каким-то образом достичь пропускной способности, равной максимальной пропускной способности распределителя, то код может быть только привязан к внешнему интерфейсу. Очевидно, что это не тот случай.
Следующим шагом является тщательное изучение трассы IACA. Я сделал следующий график потока данных на основе трассировки, который легче анализировать. Горизонтальные желтые линии делят график, согласно которому мопы распределяются в одном и том же цикле. Обратите внимание, что IACA всегда предполагает идеальный прогноз ветвления. Также обратите внимание, что это деление примерно на 99%, но не на 100%. Это не важно, и вы можете просто считать это на 100% точным. Узлы представляют собой объединенные значения, а стрелки представляют зависимость от данных (где стрелка указывает на место назначения). Узлы окрашиваются в зависимости от того, к какой итерации цикла они принадлежат. Источники стрелок в верхней части графика для ясности опущены. Зеленые прямоугольники справа содержат номер цикла, при котором выполняется распределение для соответствующих мопов. Таким образом, предыдущий цикл X, а текущий цикл X + 1, независимо от того, что X. Знаки остановки указывают, что связанный моп имеет конфликт на одном из портов. Все красные знаки остановки представляют конфликт на порту 1. Существует только один другой знак остановки другого цвета, который представляет конфликт на порту 5. Есть случаи конфликта, но я опущу их для ясности. Стрелки бывают двух цветов: синий и красный. Те, которые являются критическими. Обратите внимание, что для выделения 2-х итерационных инструкций требуется 11 циклов, а затем шаблон распределения повторяется. Имейте в виду, что Skylake имеет 97 RS.
Расположение узла в каждом подразделении ("локальное" местоположение) имеет значение. Если два узла находятся в одной строке и если все их операнды доступны, это означает, что они могут быть отправлены в одном и том же цикле. В противном случае, если узлы не находятся в одной строке, они не могут быть отправлены в одном и том же цикле. Это относится только к динамическим мопам, которые были выделены вместе как группа, а не к динамическим мопам, размещенным как часть разных групп, даже если они находятся в одном и том же разделе на графике.
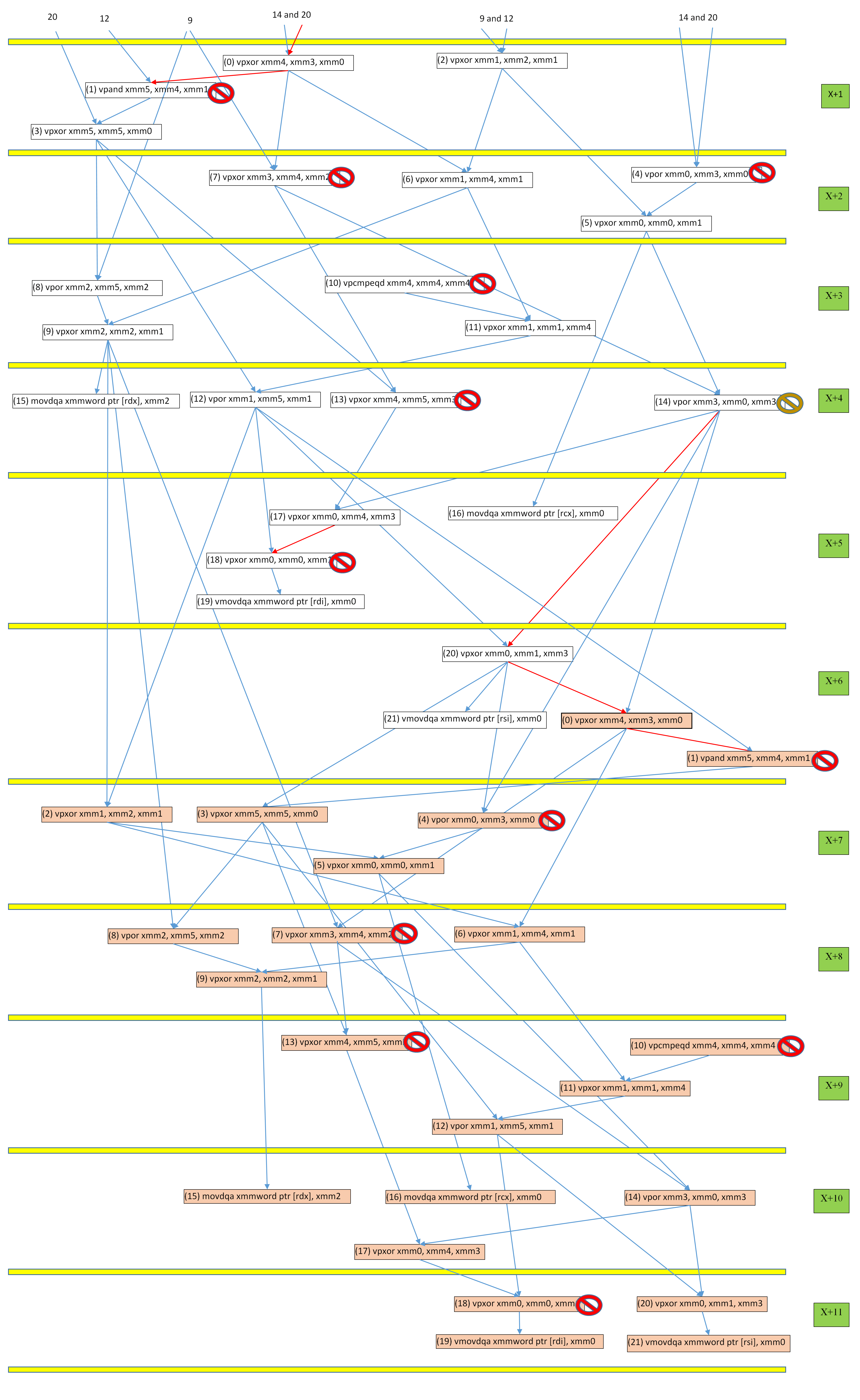
Я буду использовать обозначение (it, in) определить конкретный слитый моп, где it является нулевым номером итерации цикла и in является нулевым числом мопов. Наиболее важной частью трассировки IACA является та, которая показывает этапы конвейера для (11, 5):
11| 5|vpxor xmm0, xmm0, xmm1 : | | | | | | | | | | | | | |
11| 5| TYPE_OP (1 uops) : | | | | | |_A--------------------dw----R-------p | | | | |
Это говорит нам о том, что ширина полосы распределения в этой точке недостаточно используется из-за недоступных ресурсов (в данном случае запись в станции резервирования). Это означает, что планировщик был не в состоянии поддерживать достаточно высокую пропускную способность неиспользованных мопов, чтобы не отставать от входных 4 слитых мопов за цикл. Поскольку IACA уже сказала нам, что код связан с бэкэндом, очевидно, что причина этого недоиспользования заключается не в некоторой длинной цепочке зависимостей или конфликтах в определенных исполнительных блоках, а скорее в чем-то более сложном. Поэтому нам нужно проделать больше работы, чтобы понять, что происходит. Мы должны проанализировать прошлое (11, 5).
Циклы 1, 4, 7, 10, 13, 18 каждой итерации назначаются на порт 1. Что происходит в течение 11 циклов? Всего 12 мопов, для которых требуется порт 1, поэтому невозможно отправить их все за 11 циклов, потому что это займет не менее 12 циклов. К сожалению, зависимости данных внутри мопов, для которых требуется один и тот же порт, и между мопами, для которых требуются другие порты, значительно усугубляют проблему. Рассмотрим следующий поток в течение 11 циклов:
- В цикле 0: (0, 0) и (0, 1) распределяются (наряду с другими мопами, о которых мы сейчас не заботимся). (0, 1) зависит от данных (0, 0).
- 1: (0, 4) и (0, 7) распределяются. Предполагая, что более старые и готовые мопы не назначены для порта 0 и что операнды (0, 0) готовы, диспетчеризация (0, 0) к порту 0. Порт 1 потенциально остается незанятым, потому что (0, 1) еще не готов,
- 2: Результат (0, 0) доступен через обходную сеть. В этот момент (0, 1) может и будет отправлено. Однако, даже если (0, 4) или (0, 7) готовы, ни один из самых старых uop не назначен порту 1, поэтому оба они блокируются. (0, 10) выделяется.
- 3: (0, 4) отправляется на порт 1. (0, 7) и (0, 10) оба блокируются, даже если их операнды готовы. (0, 13) выделяется.
- 4: (0, 7) отправляется на порт 1. (0, 10) блокируется. (0, 13) должен ждать (0, 7). (0, 18) получает распределение.
- 5: (0, 10) отправляется на порт 1. (0, 13) блокируется. (0, 18) должен ждать (0, 17), который зависит от (0, 13). (1, 0) и (1, 1) распределяются.
- 6: (0, 13) отправляется на порт 1. (0, 18) должен ждать (0, 17), который зависит от (0, 13). (1, 1) должен ждать (1, 0). (1, 0) не может быть отправлено, потому что расстояние между (1, 0) и (0, 7) составляет 3 мопа, один из которых может столкнуться с конфликтом портов. (1, 4) получает распределение.
- 7: Ничто не отправляется на порт 1, потому что (0, 18), (1, 1) и (1, 4) не готовы. (1, 7) получает распределение.
- 8: Ничто не отправляется на порт 1, потому что (0, 18), (1, 1), (1, 4) и (1, 7) не готовы. (1, 10) и (1, 13) распределяются.
- 9: (0, 18) отправляется на порт 1. (1, 10) и (1, 4) готовы, но блокируются из-за конфликта портов. (1, 1), (1, 7) и (1, 13) не готовы.
- 10: (1, 1) отправляется на порт 1. (1, 4), (1, 7) и (1, 10) готовы, но блокируются из-за конфликта портов. (1, 13) не готов. (1, 18) получает распределение.
Ну, в идеале, мы бы хотели, чтобы 11 из 12 мопов были отправлены на порт 1 в 11 циклах. Но этот анализ показывает, что ситуация далека от идеальной. Порт 1 простаивает в течение 4 из 11 циклов! Если предположить, что часть (X, 18) из предыдущей итерации отправляется в цикле 0, то порт 1 будет простаивать в течение 3 циклов, что является большой тратой, учитывая, что у нас есть 12 мопов, которые требуют этого каждые 11 циклов. Из 12 мопов было отправлено только до 8. Насколько может быть плохая ситуация? Мы можем продолжить анализ трассировки и записать, как число мопов с p1-связями, которые либо готовы к отправке, но заблокированы из-за конфликта, или не готовы из-за приличия данных. Мне удалось определить, что число остановленных p1-зависимых мопов из-за конфликта портов никогда не превышает 3. Однако число p-связанных мопов, остановленных из-за приращений данных, в целом постепенно увеличивается со временем. Я не видел какой-либо закономерности его увеличения, поэтому я решил использовать линейную регрессию на первых 24 циклах трассы, чтобы предсказать, в какой момент будет 97 таких мопов. На следующем рисунке это показано.
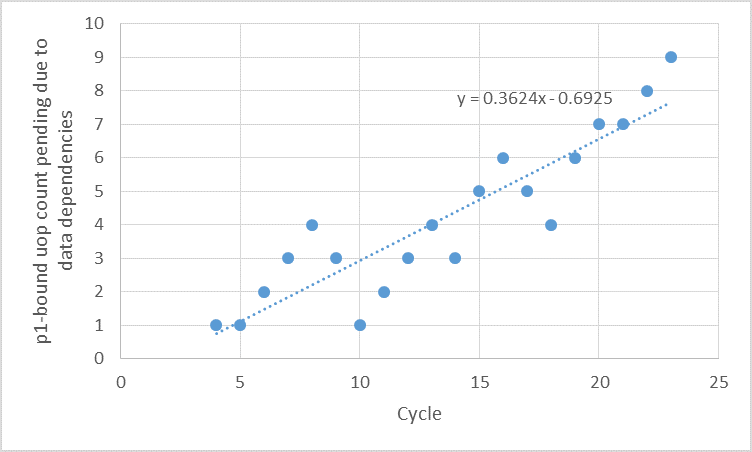
Ось X представляет нулевые циклы, увеличивающиеся слева направо. Обратите внимание, что число мопов равно нулю для первых 4 циклов. Ось Y представляет количество таких мопов в соответствующем цикле. Уравнение линейной регрессии имеет вид:
у = 0,3624х - 0,6925.
Установив у в 97 мы получаем:
х = (97 + 0,6925) / 0,3624 = 269,57
То есть примерно в цикле 269 мы ожидаем, что в RS имеется 97 мопов, все они связаны с p1 и ожидают готовности их операндов. Именно в этот момент РС полон. Однако могут быть другие мопы, ожидающие в RS по другим причинам. Таким образом, мы ожидаем, что распределитель недоиспользует свою пропускную способность в цикле 269. или перед циклом. Посмотрев на трассу IACA для инструкции (11, 5), мы можем увидеть, что ситуация происходит в цикле 61, который намного раньше, чем 269. Это означает, что либо мой предсказатель очень оптимистичен, либо подсчет числа мопов, связанных с другими портами, также демонстрирует аналогичное поведение. Мои смелости говорят мне, что это последнее. Но этого достаточно, чтобы понять, почему IACA сказала, что код связан с бэкэндом. Вы можете выполнить аналогичный анализ первого кода, чтобы понять, почему он привязан к интерфейсу. Я думаю, я просто оставлю в качестве упражнения для читателя.
Этот ручной анализ может быть выполнен в случае, если IACA не поддерживает определенный фрагмент кода или когда такого инструмента, как IACA, не существует для конкретной микроархитектуры. Модель линейной регрессии позволяет оценить, через сколько итераций распределитель использует свою пропускную способность не полностью. Например, в этом случае цикл 269 соответствует итерации 269/11/2 = 269/22 = 12. Таким образом, пока максимальное число итераций не намного больше 12, производительность внутреннего цикла цикла будет меньше вопрос.
@Bee есть похожий пост: как точно запланировано выполнение x86- мопов ?,
Я могу опубликовать детали того, что происходит в течение первых 24 циклов позже.
Примечание: в статье Викичипа о Skylake есть две ошибки. Во-первых, у планировщика Бродвелла 60 входов, а не 64. Во-вторых, пропускная способность распределителя составляет только до 4 слитых мопов.
Я сравнил эти два кода и не обнаружил разницы в производительности между ними.
Я сделал то же самое на своем Skylake i7-6700k, фактически сравнив то, что вы сказали IACA для анализа, взяв этот асм и ударив dec ebp / jnz .loop вокруг него.
я нашел sbox_ref работает на ~7.50 циклов за итерацию, в то время как sbox_resched работает на уровне ~8,04 c / iter, протестировано в статическом исполняемом файле в Linux со счетчиками производительности. (См . Действительно ли MOV в x86 "бесплатным"? Почему я вообще не могу воспроизвести это? Для деталей моей методики тестирования). Номера МАКА неверны, но это правильно, что sbox_resched медленнее.
Анализ Хади выглядит правильным: цепочки зависимостей в asm достаточно длинные, поэтому любые конфликты ресурсов при планировании uop приведут к тому, что серверная часть потеряет пропускную способность, которую она никогда не сможет догнать.
Предположительно, вы сделали это, позволив компилятору C встроить эту функцию в цикл с локальными переменными для выходных операндов. Это существенно изменит ассм (это обратный пункт, который я отредактировал в ответ @Hadi перед тем, как написать свой):
Вместо того, чтобы происходить случайно, поскольку компилятор использует xmm0..3 в качестве "чистых" регистров в конце функции, зависимости данных от выходных данных до входных данных видны компилятору, поэтому он может планировать соответствующим образом. Ваш исходный код выберет, какой выход будет возвращаться на какой вход того же S-блока.
Или deps не существует (если вы используете постоянные входы и избегаете оптимизации цикла, используя
volatileили пустой встроенный оператор asm).Запоминающие устройства для выходных операндов оптимизируются, как это происходит на самом деле, если связать это с другим S-блоком.
-
vpcmpeqdэто создает вектор "все единицы" (для NOT), который будет выведен из цикла после вставки.
Как говорит Хади, макроплавленый 1 моп dec/jnz издержки цикла не конкурируют за векторные ALU, так что это само по себе не важно. Что очень важно, так это то, что шлейф asm-цикла вокруг чего-то, что компилятор не оптимизировал, так как неудивительно, что тело цикла дает глупые результаты.