Как читать символы FNC1 в Java JTextArea
У меня есть ручной сканер, который может считывать коды GS1-DataMatrix (как в супермаркете). Я могу сканировать коды в Notepad++ и вижу, что символы FNC1 передаются (GS до 2210, 1D в HEX - первое изображение)
Сейчас я пытаюсь прочитать тот же код GS1 из Java, но он не работает, FNC1 не виден Java. В Java я вижу только "01095011010209171719050810ABCD12342110". Я преобразовал строку в HEX, но результат тот же, FNC1 тоже нет в HEX (второе изображение).
Это тестовый код:
package gs1.datamatrix;
import java.awt.Font;
import java.io.UnsupportedEncodingException;
import java.math.BigInteger;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JTextArea;
import javax.swing.event.DocumentEvent;
import javax.swing.event.DocumentListener;
import javax.swing.text.BadLocationException;
import javax.swing.text.Document;
public class GS1DataMatrix {
public static void main(String[] args) {
JFrame f=new JFrame();//creating instance of JFrame
Font font = new Font("Courier New", Font.PLAIN, 16);
JTextArea jtf2 = new JTextArea(); // used to hold the HEX data
jtf2.setBounds(10,250,900, 200);
jtf2.setFont( font.deriveFont( 24.0f) );
jtf2.setLineWrap(true);
f.add(jtf2);//adding button in JFrame
JTextArea jtf1 = new JTextArea(); // scan area for the DataMatrix scanner
jtf1.setBounds(10,10,900, 200);
jtf1.setFont( font.deriveFont( 24.0f) );
jtf1.getDocument().addDocumentListener(new DocumentListener() {
@Override
public void insertUpdate(DocumentEvent e) { update(e); }
@Override
public void removeUpdate(DocumentEvent e) { update(e); }
@Override
public void changedUpdate(DocumentEvent e) { update(e); }
public void update(DocumentEvent e) {
try {
Document doc = (Document)e.getDocument();
String hex = String.format("%040x", new BigInteger(1, doc.getText(0, doc.getLength()).getBytes("UTF8"))); // transform to HEX
jtf2.setText(java.util.Arrays.toString(hex.split("(?<=\\G..)"))); // split hex data by 2 characters
jtf1.selectAll();
} catch (Exception ex) {
Logger.getLogger(GS1DataMatrix.class.getName()).log(Level.SEVERE, null, ex);
}
}
});
f.add(jtf1);//adding button in JFrame
f.setSize(1000,500);
f.setLayout(null);
f.setVisible(true);
}
}
Первое изображение: вот как Notepad++ читает FNC1(специальный символGS на черном фоне):
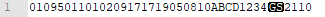
Второе изображение: это результат Java: 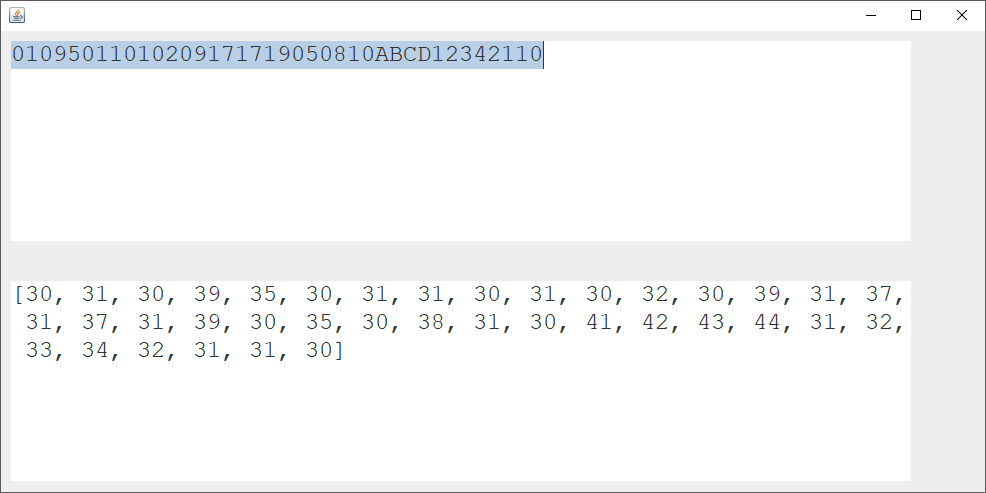
Третье изображение: шестнадцатеричный дамп Notepad++, показывающий FNC1 как 1D в HEX при каждом сканировании:

Позднее редактирование. Я думаю, что в моем первоначальном посте возникла путаница: я не анализирую изображения, сканер имеет встроенное аппаратное обеспечение, которое делает это для меня, и я получаю только текст и некоторые специальные символы (FNC1).
1 ответ
Некоторые догадки после прочтения немного:
FNC1 не имеет стандартного представления. Этот ответ о потоке стека предполагает, что нет способа напрямую кодировать FNC1 в кодировке по умолчанию Latin-1, используемой для передачи. В качестве обходного пути большинство читателей, по-видимому, по умолчанию используют управляющий символ ASCII "Разделитель групп" (GS, 29, 0x1d).
Вы используете поворотный элемент управления для отображения и работы с данными. Swing в первую очередь предназначен для отображения, а не для правильной обработки данных.
Я предполагаю, что случается так, что свинг убирает непечатный символ GS, когда он установлен в содержимом JTextArea
Учитывая, что вы не очень четко представляете, как именно ваш сканер передает данные, но вы упоминаете "Это больше похоже на клавиатуру", я предполагаю, что сканер передает данные, выдавая себя за клавиатуру. Вы будете выбирать вход, нажимая кнопку на сканере, и он будет отправлять данные как нажатия клавиш.
Теперь, если это так, вы не сможете использовать SwingDocumentListener/Documentчтобы решить это. Следующий вопрос переполнения стека в основном относится к той же проблеме, что и у вас (с той разницей, что они используют qrcode вместо штрих-кода): ASCII Непечатаемые символы в текстовом компоненте
Теперь вопрос, который я связал, предполагает, что вы можете использоватьKeyBinding или KeyListener, чтобы исправить это. Обратите внимание, что это каким-то образом нарушит шестнадцатеричное представление, если вы хотите напечатать непечатный символ.
UTF-8 имеет специальную кодовую точку для непечатаемых символьных представлений ASCII. "Символ для группового разделителя" расположен по адресу \u241d, Вариант для обработки этого будет тогда:
jtf1.getInputMap().put(KeyStroke.getKeyStroke(29), "handleGS");
jtf1.getActionMap().put("handleGS", new AbstractAction() {
@Override
public void actionPerformed(ActionEvent e) {
jtf1.setText(jtf1.getText() + "\u241d");
}
}
Таким образом, шестнадцатеричное представление должно стать:
.. , 33, 34, e2, 90, 9d, 32, 31, 31, 30]
Обратите внимание, что, поскольку мы переназначили GS в Unicode "SYMBOL_FOR_GS", мы получаем e2, 90, 9d вместо 1d,